Time series Concepts and modelling¶
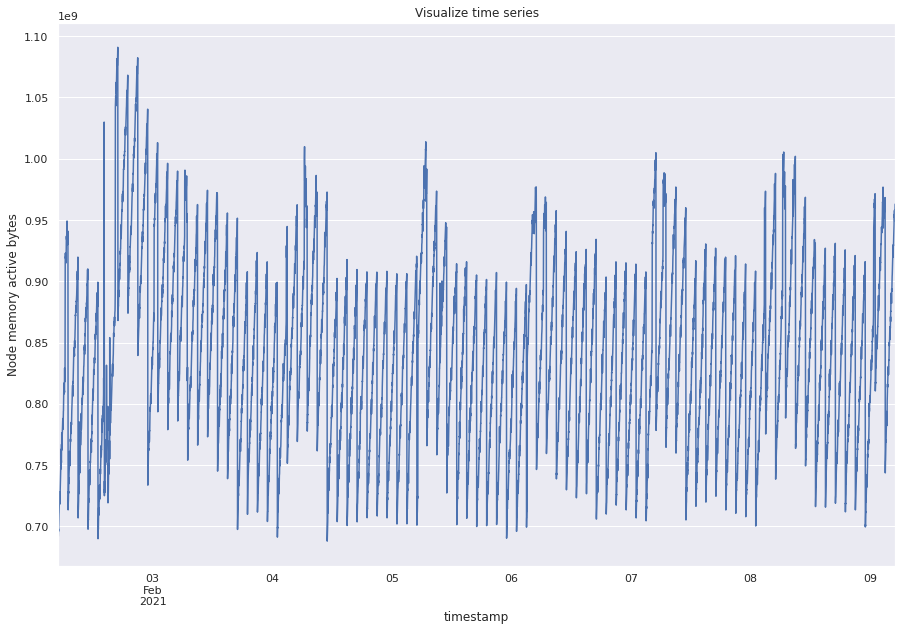
In this notebook, we shall study and experiment with the statistical tools used for time series data. We will begin with examining characteristics of a time series followed by modelling it. As an example, we take “node_memory_Active_bytes” which are the memory bytes that have been recently used by a node. It reflects the memory pressure on the node. This notebook can be used as a guideline to analyze, understand, and model any time series data.
Contents¶
Load data
Concepts
Standard time series
White noise
Random walk
Stationarity
Dicky Fuller Test
Seasonality
Naive decomposition - Additive
Multiplicative
Synthetic seasonal data
Auto Correlation
ACF
PACF
Modelling
Manual
Linear Regression
Exponential Smoothing
AR
MA
ARMA
ARIMA
SARIMAX
Automatic
Auto ARIMA
Load Data¶
from prometheus_api_client import PrometheusConnect # noqa: F401
from prometheus_api_client.metric_range_df import ( # noqa: F401
MetricRangeDataFrame,
)
from datetime import timedelta, datetime # noqa: F401
import pandas as pd
from sklearn import linear_model
from statsmodels.tsa.api import SimpleExpSmoothing, Holt
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels.graphics.tsaplots as sgt
from statsmodels.tsa.arima_model import ARMA
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from pmdarima import auto_arima
from scipy.stats.distributions import chi2
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import itertools
import warnings
warnings.filterwarnings("ignore")
# # To ensure reproducibilty, use the saved snapshot of time series data.
# # For modelling on your own as an exercise, fetch new data using this cell.
# # Creating the prometheus connect object with the required parameter
# prom_url = "http://demo.robustperception.io:9090"
# pc = PrometheusConnect(url=prom_url, disable_ssl=True)
# # Request fixed data for 1 week
# start_time = datetime(2021, 2, 2)
# end_time = datetime(2021, 2, 9)
# metric_data = pc.get_metric_range_data(
# "node_memory_Active_bytes", # metric name and label config
# start_time=start_time, # datetime object for metric range start time
# end_time=end_time,
# chunk_size=timedelta(
# days=1
# ), # timedelta object for duration of metric data downloaded in one request
# )
# ## Make the dataframe
# metric_df = MetricRangeDataFrame(metric_data)
# metric_df.index = pd.to_datetime(metric_df.index, unit="s", utc=True)
# ## Save the sanpshot of the data to ensure reproducibility
# metric_df.to_pickle("../data/raw/ts.pkl")
metric_df = pd.read_pickle("../data/raw/ts.pkl")
ts = metric_df["value"].astype(float).resample("min").mean()
sns.set()
ts.plot(figsize=(15, 10))
plt.title("Visualize time series")
plt.ylabel("Node memory active bytes")
plt.show()
Concepts¶
Standard time series¶
Before defining statistical properties, let’s understand two standard time series: white noise and random walk. These time series are often used to understand and compare others.
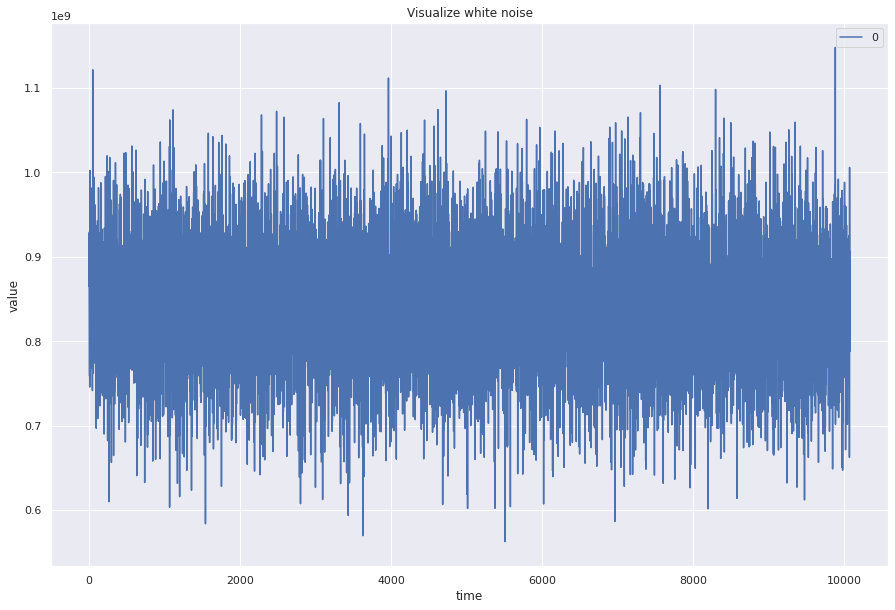
White noise¶
White noise has constant mean, constant variance, and no autocorrelation (no relationship between past and present of time series)
## Create a wn time series with mean, std, length same as our loaded data
wn = np.random.normal(loc=ts.mean(), scale=ts.std(), size=len(ts))
pd.DataFrame(wn).plot(figsize=(15, 10))
plt.title("Visualize white noise")
plt.ylabel("value")
plt.xlabel("time")
plt.show()
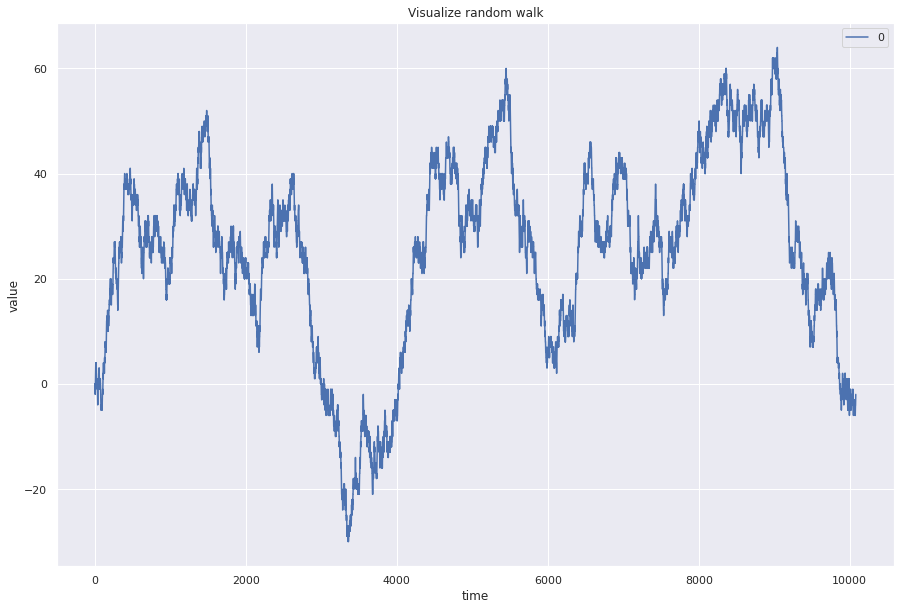
Random walk¶
A random walk is modelled using this equation: Pt = Pt-1 + \(\epsilon\)t where \(\epsilon\)t is white noise.
Random walks are not predictable
## Randomly choose from -1, 0, 1 for the next step
random_steps = np.random.choice(a=[-1, 0, 1], size=(len(ts), 1))
rw = np.concatenate([np.zeros((1, 1)), random_steps]).cumsum(0)
pd.DataFrame(rw).plot(figsize=(15, 10))
plt.title("Visualize random walk")
plt.ylabel("value")
plt.xlabel("time")
plt.show()
Stationarity¶
Intuitively, a stationary time series does not change the way it changes. In other words, the statistical properties of the process generating the time series does not change over time. For real world problems, we use the weak form or covariance stationarity definition:
Constant \(\mu\)
Constant \(\sigma\)
Cov (xn, xn+k) = Cov (xm, xm+k)
Ideally we would want the time series to be stationary for modelling. In the real world it is rarely stationary. We shall now look at the Dickey Fuller Test which determines if a series is stationary or not.
Dickey Fuller Test¶
This test determines if the time series is stationary or not.
If p value > 0.05 then process is not stationary.
If p < 0.05, null hypothesis is rejected and the process is stationary.
dft = adfuller(ts)
print(
f"p value {round(dft[1], 4)}",
f"\n Test statistic {round(dft[0], 4)}",
f"\n Critical values {dft[4]}",
)
p value 0.0
Test statistic -13.1299
Critical values {'1%': -3.431000972468946, '5%': -2.8618276912593523, '10%': -2.5669231329178066}
For this series, the p-value is 0 which means that the null hypothesis can be rejected and the series is stationary. The test statistic of -15.6815 is less than 1% critical value (-3.4304) meaning that the chances of this result being a fluke is less than 1%.
## Examining white noise
dft = adfuller(wn)
print(
f"p value {round(dft[1], 4)}",
f"\n Test statistic {round(dft[0], 4)}",
f"\n Critical values {dft[4]}",
)
p value 0.0
Test statistic -100.7762
Critical values {'1%': -3.4309989697613776, '5%': -2.861826806277955, '10%': -2.566922661841282}
## Examining random walk
dft = adfuller(rw.squeeze())
print(
f"p value {round(dft[1], 4)}",
f"\n Test statistic {round(dft[0], 4)}",
f"\n Critical values {dft[4]}",
)
p value 0.1956
Test statistic -2.2298
Critical values {'1%': -3.4309989697613776, '5%': -2.861826806277955, '10%': -2.566922661841282}
As we can see from the above, we know by definition that that white noise is stationary and the random walk is not. Since the results of the Dickey Fuller test verified our expected results, we know that we can at least have some confidence in this statistical test when it indicates to us that our real world time series data set is stationary.
Seasonality¶
There are certain trends in some time series that appear cyclically.
We can decompose the time series data into trend, seasonal, residual
Trend: general pattern present in the time series
Seasonal: cyclical effect in the time series
Residual: Error of prediction
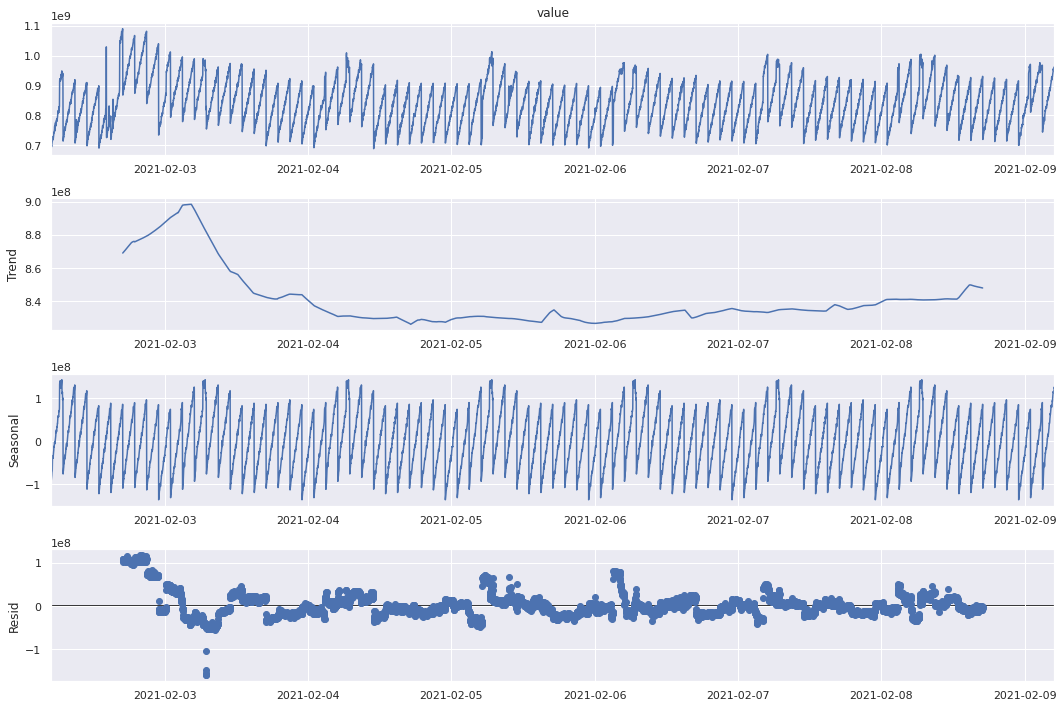
Naive Decomposition¶
One way to decompose a time series in order to check for seasonality is through naive decomposition that assumes an additive or multiplicative nature between the three components: trend, seasonal, residual.
Additive
Observed = trend + seasonal + residual
Multiplicative
Observed = trend * seasonal * residual
# Since this is minutely data, we have set freq=60*24 implying that we need to focus on one day
# We need to manually gauge this parameter in order to come up with the right decomposition
# We can set it to 60 to focus on hourly decomposition as well
plt.rc("figure", figsize=(15, 10))
sd_add = seasonal_decompose(ts, model="additive", freq=60 * 24)
sd_add.plot() # Image manipulation doesn't work here.
plt.show()
# Since this is minutely data, we have set freq=60*24 implying that we need to focus on one day
# We need to manually gauge this parameter in order to come up with the right decomposition
# We have can it to 60 to focus on hourly decomposition as well
plt.rc("figure", figsize=(15, 10))
sd_add = seasonal_decompose(ts, model="multiplicative", freq=60 * 24)
sd_add.plot() # Image manipulation doesn't work here.
plt.show()
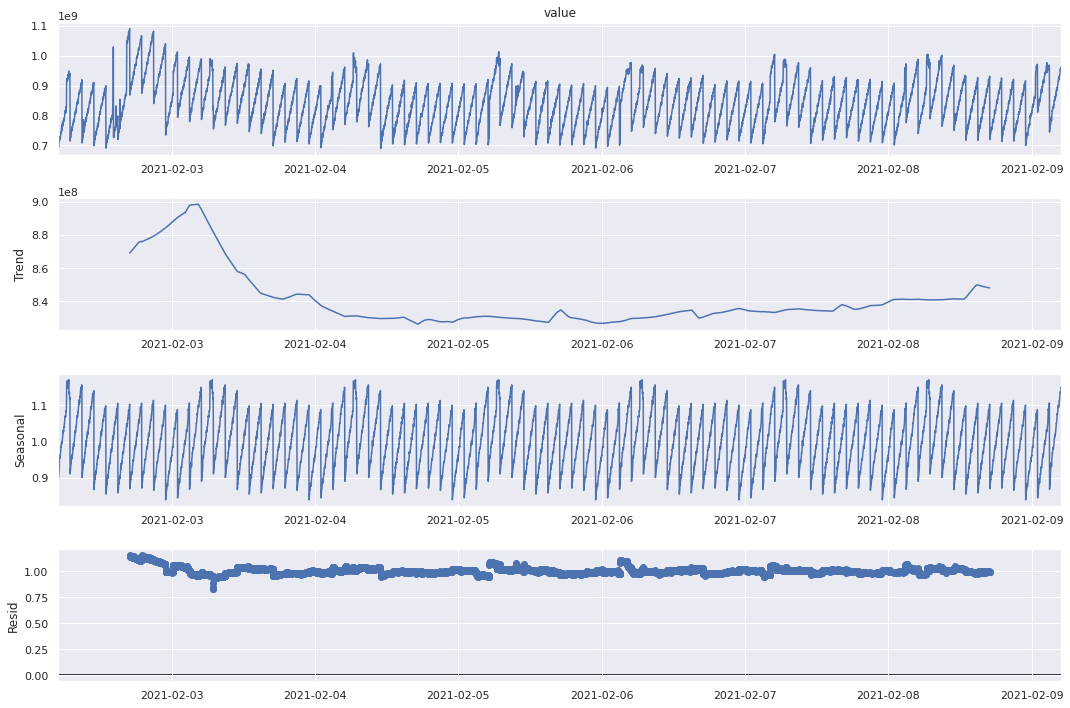
Both additive and multiplicative models give a similar output. There is a downward trend in memory usage at the begining of the week and it remains low throughout the week increasing slightly towards the end. The seasonal values show an oscillating behavior, however we can see that within a day, it starts high and reduces towards the end. The residuals however do not seem exactly random (like white noise) indicating that the decomposition is not perfect. For a better understanding, let’s try these methods on a synthetic seasonal time series.
time = np.arange(50)
## Create a pattern
values = np.where(time < 10, time ** 3, (time - 9) ** 2)
## Repeat it several times
seasonal = np.hstack((values, values, values, values, values))
## Add noise
noise = np.random.randn(250) * 100
## Add upward trend
trend = np.arange(250) * 10
## Combine all
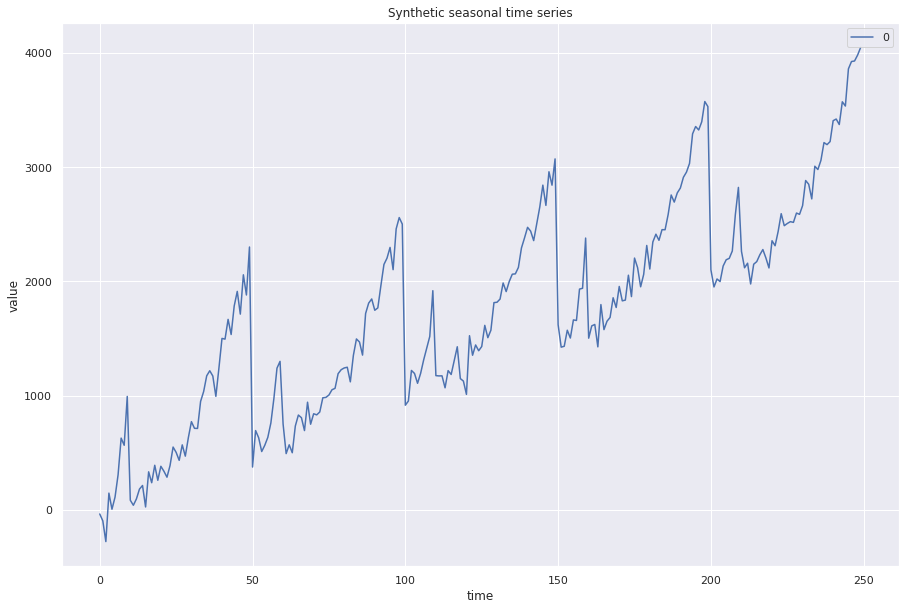
synthetic_time_series = seasonal + noise + trend
## Visualize
pd.DataFrame(synthetic_time_series).plot()
plt.xlabel("time")
plt.ylabel("value")
plt.title("Synthetic seasonal time series")
plt.show()
# For this data, we set freq=50 since we repeated a pattern 50 times
# Again, we used additional information to gauge this parameter
sd_add = seasonal_decompose(synthetic_time_series, model="additive", freq=50)
sd_add.plot() # Image manipulation doesn't work here.
plt.rc("figure", figsize=(15, 10))
plt.show()
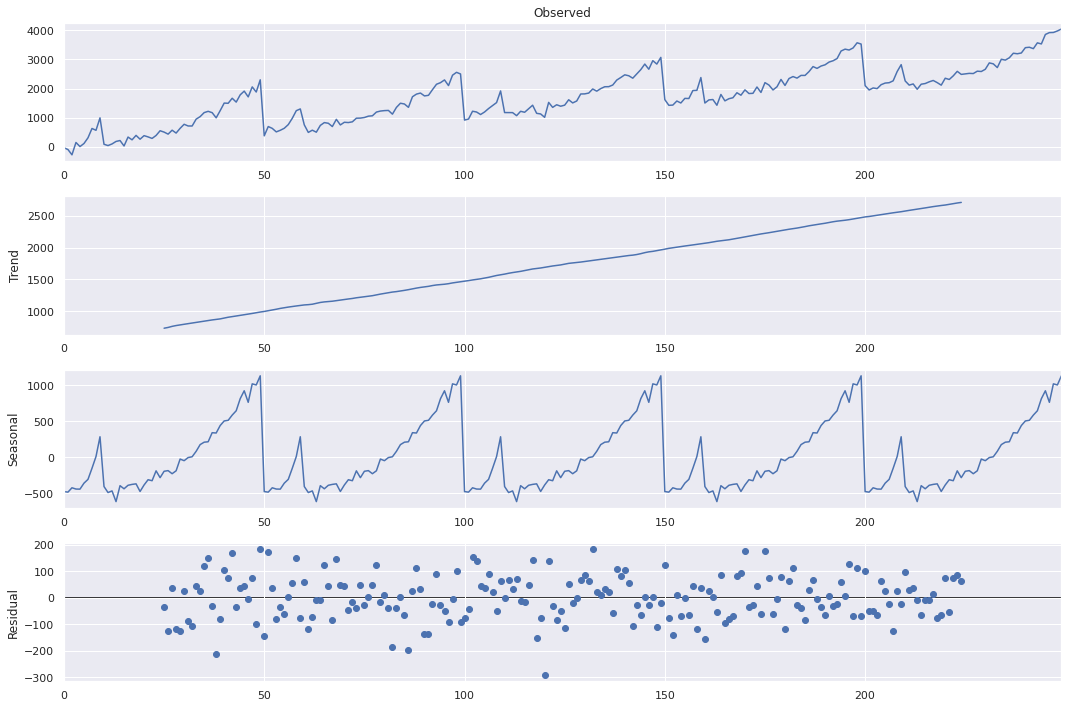
No surprises here, but we see that the time series being perfectly decomposed into the trend and the seasonal variations. The residuals look like white noise as well. We can use such decomposition for simpifying and understanding all time series data.
Auto-correlation¶
Auto correlation refers to correlation of a time series with a lagged version of itself.
ACF¶
Auto correlation function for how the number of lags we are interested in.
sgt.plot_acf(ts, lags=50, zero=False)
## We give zero=False since correlation of a time series with itself is always 1
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
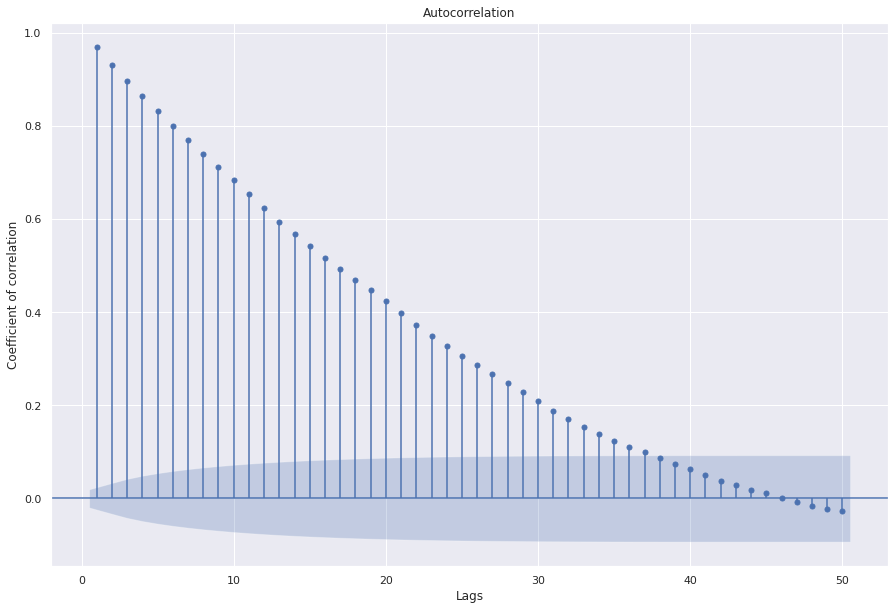
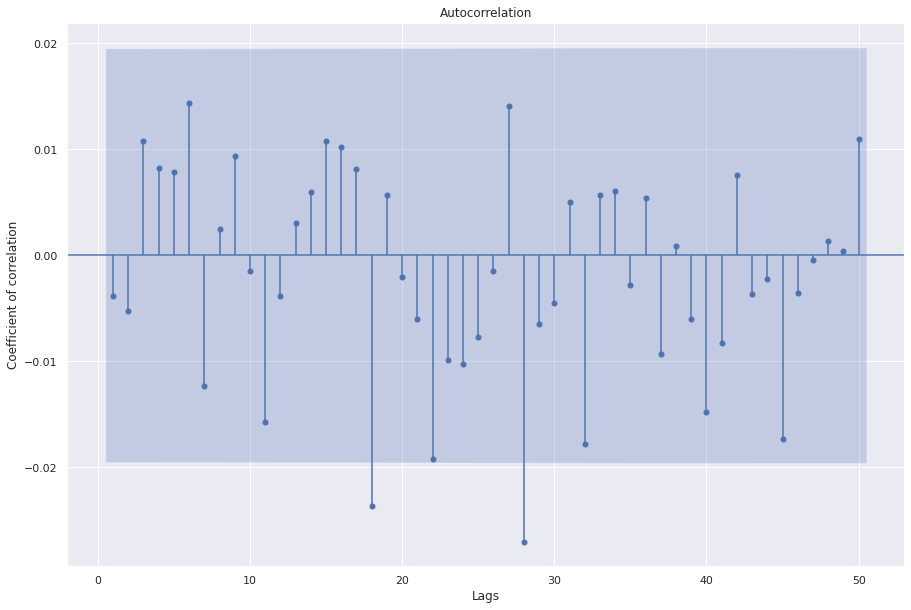
X axis represents the number of lags.
Y axis represents the correlation value of the time series with a lagged version of itself
Blue area depicts significance. In this plot, all lines are higher than significance which means that all the autocorrelation coefficients are significant.
Interpretation: There is time dependence in the data since we see high correlation. In other words, we can even use 50 points behind to predict what comes next.
This curve is also indicative of some non-stationarity in the dataset. Although the dickey-fuller test shows stationarity, ACF plot with many significant coefficients may require integrations before modelling (explained in ARIMA section).
## Let's examine auto correlation of white noise
sgt.plot_acf(wn, lags=50, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
We see that most coefficients are not significant
Randomly, some of them cross the blue area
Hence, white noise has no auto correlation or no time dependence
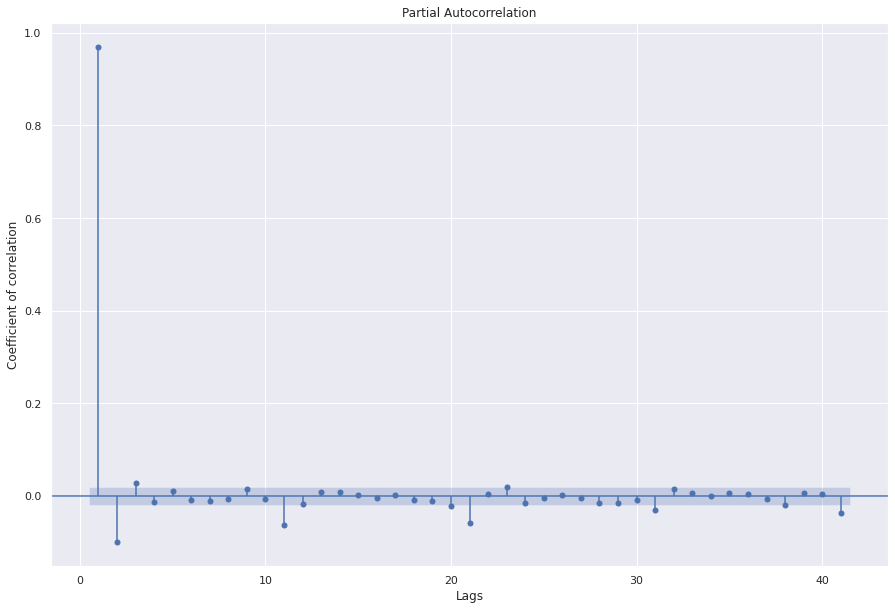
PACF (Partial Auto correlation)¶
Accounts for direct effect of xlagged on xt
For example, ACF for a lag of 3, will also include effect of xt-3 on xt-2, xt-2 on xt-1, and xt-1 on xt
PACF for a lag of 3, only accounts for effect of xt-3 on xt
The first value is same for both as there are no indirect influences in the first computation.
sgt.plot_pacf(ts, zero=False, method="ols")
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
Great! now we have a basic understanding of statistical properties of the time series data. Next, we’ll look at how to model a time series data.
Modelling¶
Before we dive into various time series models, here are some general points to keep in mind:
Start with a simple parsimonious model and add more parameters and complexity as required.
If coefficients of added variables are significantly different from zero keep them otherwise prefer simpler models to favour generalizability.
To see if we should select the more complex model, we can compare log likelihood, information criterion like AIC, and BIC.
Residuals: If the model fits the data well then the residuals should resemble white noise (or in other words, there is no trend left to capture).
Linear Regression Model¶
Linear regression is a linear model, a model that assumes a linear relationship between the input variables (x) and the single output variable (y). y can be calculated from a linear combination of the input variables (x). If we try to draw a relatonshop between these two variables, we get a straight line that can be mathematically expressed as :
y = mx + b
Where b is the intercept and m is the slope of the line.
yt = β0 + β1xt + εt
The coefficients β0 and β1 denote the intercept and the slope of the line respectively. The intercept β0 represents the predicted value of y when x=0. The slope β1 represents the average predicted change in y resulting from a one unit increase in x.
So basically, the linear regression algorithm gives us the most optimal value for the intercept and the slope in a two dimensional environment. The x and y values
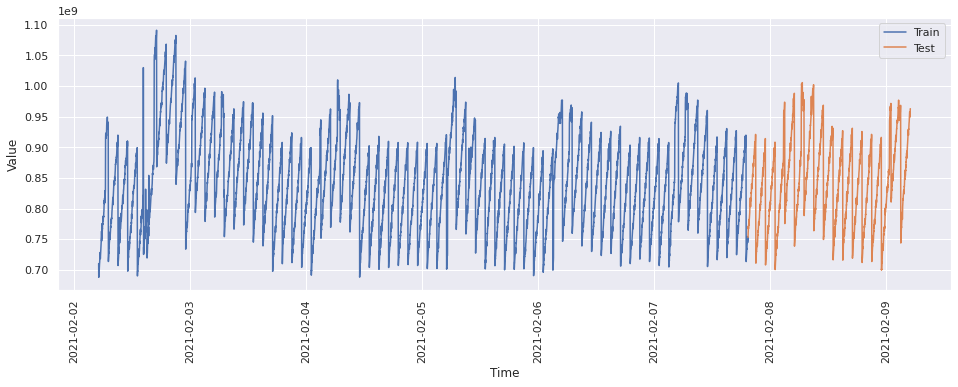
train = ts[0 : int(len(ts) * 0.8)]
test = ts[int(len(ts) * 0.8) :]
train_time = [i + 1 for i in range(len(train))]
test_time = [i + 8065 for i in range(len(test))]
LinearRegression_train = pd.DataFrame(train)
LinearRegression_test = pd.DataFrame(test)
LinearRegression_train["time"] = train_time
LinearRegression_test["time"] = test_time
LinearRegression_train.tail()
| value | time | |
|---|---|---|
| timestamp | ||
| 2021-02-07 19:19:00+00:00 | 7.443729e+08 | 8060 |
| 2021-02-07 19:20:00+00:00 | 7.448098e+08 | 8061 |
| 2021-02-07 19:21:00+00:00 | 7.495154e+08 | 8062 |
| 2021-02-07 19:22:00+00:00 | 7.500192e+08 | 8063 |
| 2021-02-07 19:23:00+00:00 | 7.529506e+08 | 8064 |
LinearRegression_test.head()
| value | time | |
|---|---|---|
| timestamp | ||
| 2021-02-07 19:24:00+00:00 | 7.529376e+08 | 8065 |
| 2021-02-07 19:25:00+00:00 | 7.605699e+08 | 8066 |
| 2021-02-07 19:26:00+00:00 | 7.616949e+08 | 8067 |
| 2021-02-07 19:27:00+00:00 | 7.628725e+08 | 8068 |
| 2021-02-07 19:28:00+00:00 | 7.714700e+08 | 8069 |
plt.figure(figsize=(16, 5))
plt.plot(LinearRegression_train["value"], label="Train")
plt.plot(LinearRegression_test["value"], label="Test")
plt.legend(loc="best")
plt.xlabel("Time")
plt.ylabel("Value")
plt.xticks(rotation=90)
plt.show()
# Training the algorithm
lr = linear_model.LinearRegression()
lr.fit(
LinearRegression_train[["time"]], LinearRegression_train["value"].values
)
LinearRegression()
As discussed previously, we saw that Linear Regression model looks for the best value for the intercept and result in a line that best fits the data. Let’s see how we can retrieve those parameters.
# Intercept
print("Intercept :", lr.intercept_)
# Coeffiecient of x : Slope
print("Coefficient of x :", lr.coef_)
Intercept : 857400029.6296086
Coefficient of x : [-4126.27650078]
This means that for every one unit of change in time, the change in the value is about -4126.27. However, this information doesn’t help a lot in knowing how the time series data would change with time. This method can be mostly be useful in cases where the data is linear. In this scenario we have some trends and seasonality as well. We will now move towards Exponential Smoothing models to see how they are different and better than linear models.
Exponential Smoothing Model¶
Forecasts produced using exponential smoothing methods are weighted averages of past observations, with the weights decaying exponentially as the observations get older. In other words, the more recent the observation the higher the associated weight.
Simple Exponential Smoothing¶
Simple exponential smoothing method is most suitable for forecasting data with no clear trend or seasonal pattern. It requires a single parameter, called alpha (α), also called the smoothing factor or smoothing coefficient.
Alpha (smoothing_level) controls the rate at which the influence of the observations at prior time steps decay exponentially.
Alpha is often set to a value between 0 and 1.
Large values mean that the model pays attention mainly to the most recent past observations, whereas smaller values mean more of the history is taken into account when making a prediction.
As we mentioned, that SES has only one component, let’s see how it is represented in mathematical form :
Forecast : pt = lt
Level : lt = α yt + (1-α)lt-1
Where p is the forecast, l is the level and α is the smoothing factor.
ses_train = pd.DataFrame(train)
# Try autofit
ses_model = SimpleExpSmoothing(ses_train["value"])
ses_model_autofit = ses_model.fit(optimized=True, use_brute=True)
ses_model_autofit.summary()
| Dep. Variable: | value | No. Observations: | 8064 |
|---|---|---|---|
| Model: | SimpleExpSmoothing | SSE | 2821028751038333952.000 |
| Optimized: | True | AIC | 270055.008 |
| Trend: | None | BIC | 270068.999 |
| Seasonal: | None | AICC | 270055.013 |
| Seasonal Periods: | None | Date: | Tue, 20 Apr 2021 |
| Box-Cox: | False | Time: | 18:55:27 |
| Box-Cox Coeff.: | None |
| coeff | code | optimized | |
|---|---|---|---|
| smoothing_level | 0.9950000 | alpha | True |
| initial_level | 7.1014e+08 | l.0 | True |
The above model is a result of the autofit model by statsmodels. As mentioned above, the depends on one parameter alpha also known as the smoothing factor or smoothing coefficient. According to autofit, the best alpha for this data would be 0.995. That means the model pays attention mainly to the most recent past observations.
Optimize Alpha
We could also try other values for alpha as follows and will chose the minimum AIC i.e. Akaike’s Information Criterion which is defined as :
AIC = -2log(L) + 2k
where L is the likelihood of the model and k is the total number of parameters and initial states that have been estimated (including the residual variance).
The measures on the training set (training sample) are not really suitable as basis for model selection. It is because in the training sample it is always possible to overfit, and the richer the model, the better the fit will be. Meanwhile, information criteria like AIC or BIC take this into account and penalize for the model complexity accordingly. Therefore, they generally are suitable for model selection. For this model let’s try to minimize the value of AIC in order to find the best model.
# Try to optimize the coefficient by finding minimum AIC.
min_ses_aic = 99999999
for i in np.arange(0.01, 1, 0.01):
ses_model_alpha = ses_model.fit(
smoothing_level=i, optimized=False, use_brute=False
)
# You can print to see all the AIC values
# print(' SES {} - AIC {} '.format(i,ses_model_alpha.aic))
if ses_model_alpha.aic < min_ses_aic:
min_ses_aic = ses_model_alpha.aic
min_aic_ses_model = ses_model_alpha
min_aic_alpha_ses = i
print("Best Alpha : ", min_aic_alpha_ses)
print("Best Model : \n")
min_aic_ses_model.summary()
Best Alpha : 0.99
Best Model :
| Dep. Variable: | value | No. Observations: | 8064 |
|---|---|---|---|
| Model: | SimpleExpSmoothing | SSE | 2823356819433681408.000 |
| Optimized: | False | AIC | 270061.661 |
| Trend: | None | BIC | 270075.651 |
| Seasonal: | None | AICC | 270061.666 |
| Seasonal Periods: | None | Date: | Tue, 20 Apr 2021 |
| Box-Cox: | False | Time: | 18:55:28 |
| Box-Cox Coeff.: | None |
| coeff | code | optimized | |
|---|---|---|---|
| smoothing_level | 0.9900000 | alpha | False |
| initial_level | 7.1014e+08 | l.0 | False |
The above implementation of Simple Exponential Smoothing allows us to compare the autofit and manual grid search for best alpha and best model. Both the alphas are pretty comparable and gives us the best model. However, this model performs better where there is no seasonality and trend. So we will move to Holt’s model that covers the trend in data but no seasonality.
Holt’s Double Exponential Smoothing Model¶
Holt’s Double Exponential Smoothing method is similar to Simple Exponential Smoothing. It calculates the level component to measure the level in the Forecast.In addition to the alpha parameter for controlling smoothing factor for the level, an additional smoothing factor is added to control the decay of the influence of the change in trend called beta (β).
Forecast Equation : pt+h|t = lt + hbt
Level Equation : lt = αyt + (1-α)lt-1
Trend Equation : bt = β(lt - lt-1) + (1-β)bt-1
Where p is the forecast, l is the level, α is the smoothing factor and β is the smoothing slope.
# since optimization is intensive, we are sampling for this method
ts_holt = metric_df["value"].astype(float).resample("30min").mean()
train = ts_holt[0 : int(len(ts_holt) * 0.8)]
test = ts_holt[int(len(ts_holt) * 0.8) :]
des_train = pd.DataFrame(train)
# Try out autofit model and see what alpha and beta values are.
des_model = Holt(des_train["value"])
des_model_autofit = des_model.fit(optimized=True, use_brute=True)
des_model_autofit.summary()
| Dep. Variable: | value | No. Observations: | 268 |
|---|---|---|---|
| Model: | Holt | SSE | 1568472669608974080.000 |
| Optimized: | True | AIC | 9737.913 |
| Trend: | Additive | BIC | 9752.277 |
| Seasonal: | None | AICC | 9738.235 |
| Seasonal Periods: | None | Date: | Tue, 20 Apr 2021 |
| Box-Cox: | False | Time: | 18:55:28 |
| Box-Cox Coeff.: | None |
| coeff | code | optimized | |
|---|---|---|---|
| smoothing_level | 0.2878571 | alpha | True |
| smoothing_trend | 0.1877329 | beta | True |
| initial_level | 7.1496e+08 | l.0 | True |
| initial_trend | 5.1207e+07 | b.0 | True |
Just like we did for Simple Exponential Smoothing model, for this model also let’s try to minimize the value of AIC in order to find the best model. The only difference here would be that we have two parameters : alpha and beta.
# Try to optimize the coefficient:
min_des_aic = 99999
for i in np.arange(0.01, 1, 0.01):
for j in np.arange(0.01, 1.01, 0.01):
des_model_alpha_beta = des_model.fit(
smoothing_level=i,
smoothing_slope=j,
optimized=False,
use_brute=False,
)
# You can print to see all the AIC values
# print(' DES {} - AIC {} '.format(i,des_model_alpha_beta.aic))
if des_model_alpha_beta.aic < min_des_aic:
min_des_aic = des_model_alpha_beta.aic
min_aic_des_model = des_model_alpha_beta
min_aic_alpha_des = i
min_aic_beta_des = j
print("Best Alpha : ", min_aic_alpha_des)
print("Best Beta : ", min_aic_beta_des)
print("Best Model : \n")
min_aic_des_model.summary()
Best Alpha : 0.23
Best Beta : 0.45
Best Model :
| Dep. Variable: | value | No. Observations: | 268 |
|---|---|---|---|
| Model: | Holt | SSE | 1567952299397379584.000 |
| Optimized: | False | AIC | 9737.824 |
| Trend: | Additive | BIC | 9752.188 |
| Seasonal: | None | AICC | 9738.146 |
| Seasonal Periods: | None | Date: | Tue, 20 Apr 2021 |
| Box-Cox: | False | Time: | 18:56:24 |
| Box-Cox Coeff.: | None |
| coeff | code | optimized | |
|---|---|---|---|
| smoothing_level | 0.2300000 | alpha | False |
| smoothing_trend | 0.4500000 | beta | False |
| initial_level | 7.1496e+08 | l.0 | False |
| initial_trend | 5.1207e+07 | b.0 | False |
The above implementation of Simple Exponential Smoothing allows us to compare the autofit and manual grid search for best alpha, beta and best model. Both the alphas and betas are very different from each other. However, this model performs better where there is no seasonality. So we will move to other approaches that capture seasonality as well.
Auto regressive (AR) Model¶
The next model we will explore is the AR model. Linear regression models the linear relationship of predictors whereas ARIMA models the linear relationship of past observation. This makes ARIMA naturally adaptive to new data [source]. The following equation shows AR(1) or auto regression model that learns from just one past observation.
xt = c + \(\phi\)xt-1 + \(\epsilon\)t
\(\phi\) is a numerical constant from -1 to 1 (otherwise it’ll blow up)
\(\epsilon\)t represents unpredictable shocks.
In real life, looking at just 1 lag may not give reasonable results. To determine the optimal number of lags, we look at PACF plots and incrementally increase the number. If we have coefficients close to 1, that means they can be good candidates for the model. Note: AR model stationary process better. For non-stationary time series, it is often converted to stationary process first.
sgt.plot_pacf(ts, zero=False, method="ols")
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
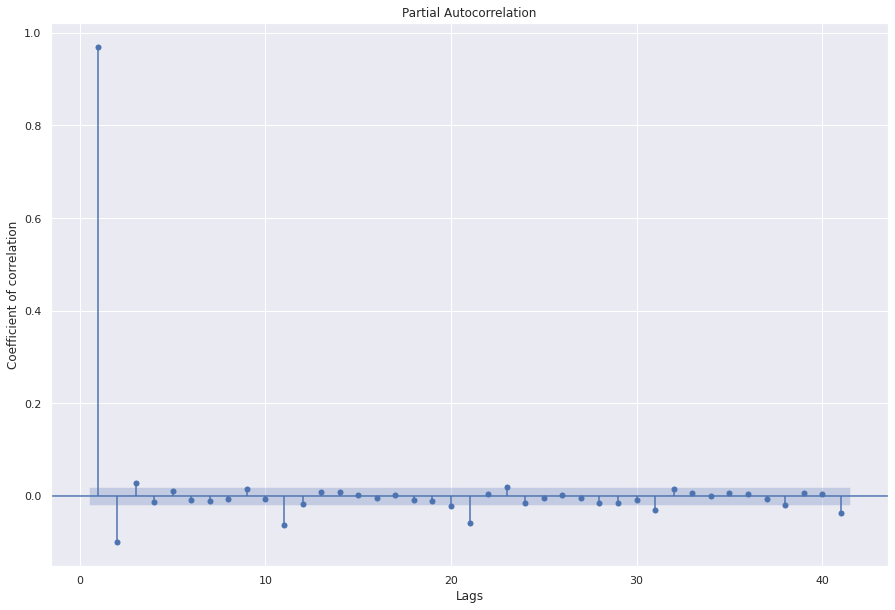
## Let's start with a simple model with 1 lag
## Since we have the highest PACF coefficient for lag 1
model_ar_1 = ARMA(ts, order=(1, 0))
results_ar_1 = model_ar_1.fit()
results_ar_1.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(1, 0) | Log Likelihood | -182908.385 |
| Method: | css-mle | S.D. of innovations | 18376741.644 |
| Date: | Tue, 20 Apr 2021 | AIC | 365822.770 |
| Time: | 18:56:26 | BIC | 365844.425 |
| Sample: | 02-02-2021 | HQIC | 365830.097 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.83e+06 | 144.366 | 0.000 | 8.3e+08 | 8.53e+08 |
| ar.L1.value | 0.9687 | 0.002 | 391.053 | 0.000 | 0.964 | 0.974 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0323 | +0.0000j | 1.0323 | 0.0000 |
Interpretation:
ar.L1.value is the value of \(\phi\) in the AR(1) equation.
const is the value of c in AR(1) equation.
p < 0.05 suggests that these coefficients are significant.
Since the ar.L1.value is not 0, this variable adds to the model.
Great! let’s increase the order and see if the more complex model is better.
model_ar_2 = ARMA(ts, order=(2, 0))
results_ar_2 = model_ar_2.fit()
results_ar_2.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(2, 0) | Log Likelihood | -182859.191 |
| Method: | css-mle | S.D. of innovations | 18287258.874 |
| Date: | Tue, 20 Apr 2021 | AIC | 365726.383 |
| Time: | 18:56:28 | BIC | 365755.256 |
| Sample: | 02-02-2021 | HQIC | 365736.152 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.27e+06 | 159.483 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 1.0641 | 0.010 | 107.367 | 0.000 | 1.045 | 1.084 |
| ar.L2.value | -0.0986 | 0.010 | -9.943 | 0.000 | -0.118 | -0.079 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0399 | +0.0000j | 1.0399 | 0.0000 |
| AR.2 | 9.7543 | +0.0000j | 9.7543 | 0.0000 |
Alright, we have a more complex model, but is it adding anything new? The log likelihood ratio (LLR) test determines if the new model adds value to the modelling significantly. It returns a p value, if p<0.05 then the complex model is better.
# LLR Test
def llr_test(res_1, res_2, df=1):
l1, l2 = res_1.llf, res_2.llf
lr = 2 * (l2 - l1)
p = chi2.sf(lr, df).round(3)
result = "Insignificant"
if p < 0.005:
result = "Significant"
return p, result
llr_test(results_ar_1, results_ar_2)
(0.0, 'Significant')
So the second model is significantly better than the first.
## Let's automate this process to find the order
llr = 0
p = 1
results = ARMA(ts, order=(p, 0)).fit()
while llr < 0.05:
results_prev = results
p += 1
results = ARMA(ts, order=(p, 0)).fit()
llr, _ = llr_test(results_prev, results)
print(p, llr)
2 0.0
3 0.004
4 0.22
The above code suggests that going from order 3 to order 4 does not add any significant value in the model. We can also see that by looking at the summaries of the results. Side note: These are rules of thumb but as we see in the pacf plot, some higher lags than 3 are also significant, it could be that a higher lag model may fit the series better.
model_ar_3 = ARMA(ts, order=(3, 0))
results_ar_3 = model_ar_3.fit()
model_ar_4 = ARMA(ts, order=(4, 0))
results_ar_4 = model_ar_4.fit()
results_ar_3.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(3, 0) | Log Likelihood | -182855.084 |
| Method: | css-mle | S.D. of innovations | 18279805.659 |
| Date: | Tue, 20 Apr 2021 | AIC | 365720.167 |
| Time: | 18:56:45 | BIC | 365756.259 |
| Sample: | 02-02-2021 | HQIC | 365732.379 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.43e+06 | 154.966 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 1.0670 | 0.010 | 107.170 | 0.000 | 1.047 | 1.086 |
| ar.L2.value | -0.1290 | 0.015 | -8.889 | 0.000 | -0.157 | -0.101 |
| ar.L3.value | 0.0285 | 0.010 | 2.867 | 0.004 | 0.009 | 0.048 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0375 | -0.0000j | 1.0375 | -0.0000 |
| AR.2 | 1.7397 | -5.5440j | 5.8105 | -0.2016 |
| AR.3 | 1.7397 | +5.5440j | 5.8105 | 0.2016 |
results_ar_4.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(4, 0) | Log Likelihood | -182854.332 |
| Method: | css-mle | S.D. of innovations | 18278441.806 |
| Date: | Tue, 20 Apr 2021 | AIC | 365720.663 |
| Time: | 18:56:47 | BIC | 365763.973 |
| Sample: | 02-02-2021 | HQIC | 365735.318 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.36e+06 | 156.885 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 1.0673 | 0.010 | 107.169 | 0.000 | 1.048 | 1.087 |
| ar.L2.value | -0.1305 | 0.015 | -8.964 | 0.000 | -0.159 | -0.102 |
| ar.L3.value | 0.0416 | 0.015 | 2.855 | 0.004 | 0.013 | 0.070 |
| ar.L4.value | -0.0122 | 0.010 | -1.226 | 0.220 | -0.032 | 0.007 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0385 | -0.0000j | 1.0385 | -0.0000 |
| AR.2 | 4.4697 | -0.0000j | 4.4697 | -0.0000 |
| AR.3 | -1.0523 | -4.0655j | 4.1995 | -0.2903 |
| AR.4 | -1.0523 | +4.0655j | 4.1995 | 0.2903 |
At the end the more complex model should have both insignificant \(\phi\) values and insignificant log value. When we reach that stage, in this case at the lag 3, we stop.
Side note: If you want to compare different time series, make sure to normalize values. One way to do this is to divide the series by the first number.
Analyzing the residuals¶
This is a very important step in analysing the model performance.
Remember that residuals should be similar to white noise reflecting that there is no trend remaining to be captured.
We will now plot the residuals, check for stationarity, and check ACF plots.
resid = results_ar_3.resid
resid.plot()
plt.ylabel("Residuals")
plt.rc("figure", figsize=(15, 10))
plt.title("Visualizing residuals")
plt.show()
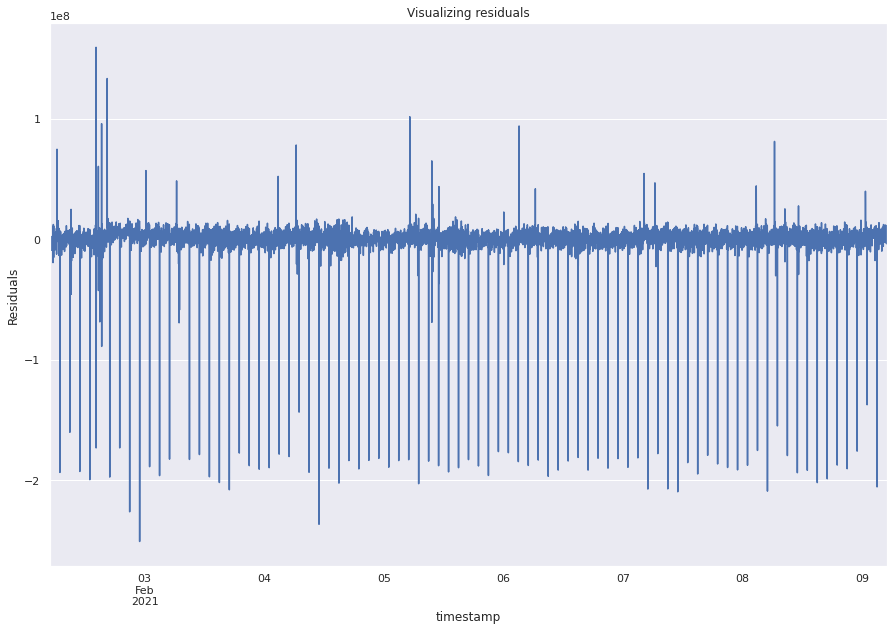
print(resid.mean(), resid.var())
9857.757619109436 335785710794057.25
adfuller(resid)
(-20.71399135956376,
0.0,
21,
10058,
{'1%': -3.4310003250850523,
'5%': -2.8618274051853487,
'10%': -2.5669229806403036},
364247.3069391926)
sgt.plot_acf(resid, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
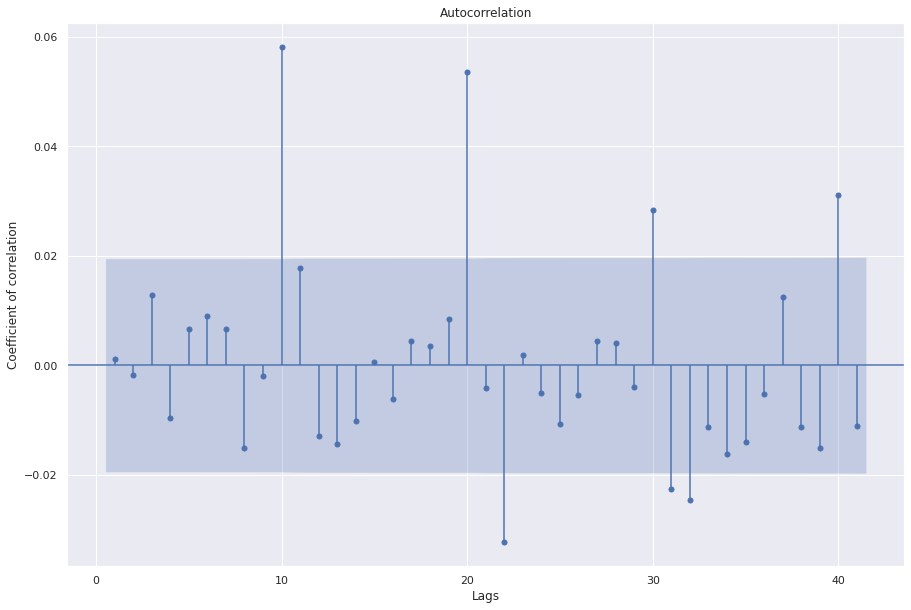
Interpretation¶
The plot shows that the residuals look random but are not exactly like white noise.
The Dickey Fuller test suggests that the residuals are stationary.
The ACF plots show coefficients that are significant further indicating that the residuals are not perfectly white noise and there could be better predictors.
Moving average model¶
Better suited if the data has unexpected shocks
Accounts for the past residuals
Absorbs shocks (accounts from past errors) and correct
rt = c + \(\theta\)\(\epsilon\)t-1 + \(\epsilon\)t
For finding the optimal number of lags for this model, we rely more on ACF than PACF because it learns from residuals, so the direct effect of a past observation on the present day is not relevant.
Mathematical fact: If MA coefficients are close to 1 then it is basically an approximation of AR model.
Both AR, MA models are bad with non-stationary data.
sgt.plot_acf(ts, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
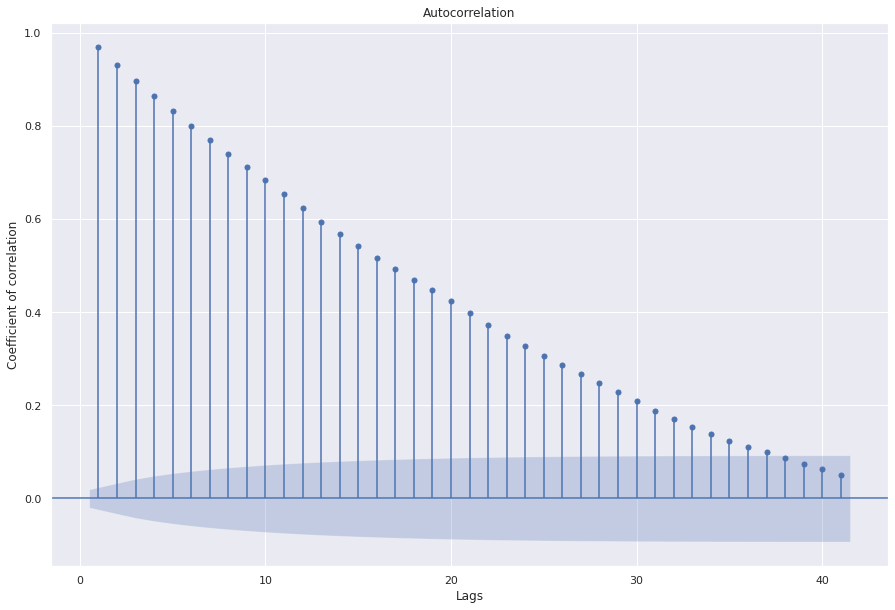
Most the coefficients in the lags are significant implying that MA(n+1) will always be better than MA(n). This type of data suggests that some type of a combination of AR and MA is required to correctly model the data. For reference, let’s train a MA model of order 1.
model_ma_1 = ARMA(ts, order=(0, 1)) ## p, q where p is AR and q is MA param¶
model_ma_results_1 = ARMA(ts, order=(0, 1)).fit() model_ma_results_1.summary()
The results show that the coefficient is significant.
ARMA (AR and MA models together)¶
The ARMA model considers both lagged value and lagged errors.
Following equation represents ARMA(1,1):
rt = c + \(\phi\)rt-1 + \(\theta\)\(\epsilon\)t-1 + \(\epsilon\)t
For ARMA model, we select complex model and move to simpler models.
For determining p, q take hint from PACF and ACF respectively.
The coefficients of the complex model should be significantly better than 0 and the either the AIC should be lower or the LLR test should give significant p-values.
LLR test only works for nested models (one model should have all the lag terms of the other). While comparing ARMA(1,3) and ARMA(3,1), we have to look at AIC. Lower values of AIC are prefered over higher values.
We found 3 lags for AR component and MA can be anything.
p = range(1, 5)
q = range(1, 5)
pq = list(itertools.product(p, q))
for i in range(1, len(pq)):
print("Model: {}".format(pq[i]))
Model: (1, 2)
Model: (1, 3)
Model: (1, 4)
Model: (2, 1)
Model: (2, 2)
Model: (2, 3)
Model: (2, 4)
Model: (3, 1)
Model: (3, 2)
Model: (3, 3)
Model: (3, 4)
Model: (4, 1)
Model: (4, 2)
Model: (4, 3)
Model: (4, 4)
results = []
for order in pq:
try:
print(order)
model_arma_results = ARMA(ts, order=order).fit()
results.append([order, model_arma_results.aic])
except ValueError as e:
print(order, "Error", e)
results.append([order, float("inf")])
(1, 1)
(1, 2)
(1, 3)
(1, 4)
(2, 1)
(2, 2)
(2, 2) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 3)
(2, 3) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 4)
(2, 4) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(3, 1)
(3, 2)
(3, 3)
(3, 4)
(3, 4) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(4, 1)
(4, 2)
(4, 3)
(4, 4)
(4, 4) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
results.sort(key=lambda x: x[1])
results
[[(3, 3), 365487.8721028673],
[(4, 3), 365590.621612872],
[(2, 1), 365718.12121591234],
[(1, 2), 365718.9376581142],
[(3, 1), 365719.51921091694],
[(1, 3), 365720.09677661443],
[(1, 1), 365721.14203969185],
[(1, 4), 365721.4326000566],
[(4, 1), 365721.50651079626],
[(3, 2), 365721.5111232434],
[(4, 2), 365723.4880399195],
[(2, 2), inf],
[(2, 3), inf],
[(2, 4), inf],
[(3, 4), inf],
[(4, 4), inf]]
model_arma_43_results = ARMA(ts, order=(4, 3)).fit()
model_arma_43_results.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(4, 3) | Log Likelihood | -182786.311 |
| Method: | css-mle | S.D. of innovations | 18153981.781 |
| Date: | Tue, 20 Apr 2021 | AIC | 365590.622 |
| Time: | 19:06:23 | BIC | 365655.586 |
| Sample: | 02-02-2021 | HQIC | 365612.603 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.41e+06 | 155.360 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 0.8821 | 0.083 | 10.674 | 0.000 | 0.720 | 1.044 |
| ar.L2.value | -0.7894 | 0.104 | -7.591 | 0.000 | -0.993 | -0.586 |
| ar.L3.value | 0.4839 | 0.104 | 4.664 | 0.000 | 0.281 | 0.687 |
| ar.L4.value | 0.3399 | 0.078 | 4.337 | 0.000 | 0.186 | 0.493 |
| ma.L1.value | 0.1844 | 0.079 | 2.327 | 0.020 | 0.029 | 0.340 |
| ma.L2.value | 0.8717 | 0.022 | 40.397 | 0.000 | 0.829 | 0.914 |
| ma.L3.value | 0.4526 | 0.079 | 5.740 | 0.000 | 0.298 | 0.607 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0377 | -0.0000j | 1.0377 | -0.0000 |
| AR.2 | 0.1452 | -1.0047j | 1.0151 | -0.2272 |
| AR.3 | 0.1452 | +1.0047j | 1.0151 | 0.2272 |
| AR.4 | -2.7516 | -0.0000j | 2.7516 | -0.5000 |
| MA.1 | 0.1360 | -0.9934j | 1.0026 | -0.2283 |
| MA.2 | 0.1360 | +0.9934j | 1.0026 | 0.2283 |
| MA.3 | -2.1979 | -0.0000j | 2.1979 | -0.5000 |
model_arma_33_results = ARMA(ts, order=(3, 3)).fit()
model_arma_33_results.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(3, 3) | Log Likelihood | -182735.936 |
| Method: | css-mle | S.D. of innovations | 18060470.382 |
| Date: | Tue, 20 Apr 2021 | AIC | 365487.872 |
| Time: | 19:09:58 | BIC | 365545.619 |
| Sample: | 02-02-2021 | HQIC | 365507.411 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.4e+06 | 155.763 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 0.3450 | 0.003 | 120.383 | 0.000 | 0.339 | 0.351 |
| ar.L2.value | -0.4045 | 0.002 | -227.156 | 0.000 | -0.408 | -0.401 |
| ar.L3.value | 0.9630 | 0.003 | 336.179 | 0.000 | 0.957 | 0.969 |
| ma.L1.value | 0.7292 | 0.010 | 70.724 | 0.000 | 0.709 | 0.749 |
| ma.L2.value | 1.0668 | 0.006 | 165.921 | 0.000 | 1.054 | 1.079 |
| ma.L3.value | 0.1088 | 0.010 | 10.542 | 0.000 | 0.089 | 0.129 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | -0.3091 | -0.9511j | 1.0001 | -0.3000 |
| AR.2 | -0.3091 | +0.9511j | 1.0001 | 0.3000 |
| AR.3 | 1.0383 | -0.0000j | 1.0383 | -0.0000 |
| MA.1 | -0.3104 | -0.9510j | 1.0004 | -0.3002 |
| MA.2 | -0.3104 | +0.9510j | 1.0004 | 0.3002 |
| MA.3 | -9.1869 | -0.0000j | 9.1869 | -0.5000 |
ARMA(4,3) and ARMA(3,3) have low AIC, with all significant coefficients. Both of these models are good candidates for fitting the series.
Analyzing the residuals¶
resid_43 = model_arma_43_results.resid
resid_43.plot()
plt.ylabel("Residuals")
plt.rc("figure", figsize=(15, 10))
plt.title("Visualizing residuals")
Text(0.5, 1.0, 'Visualizing residuals')
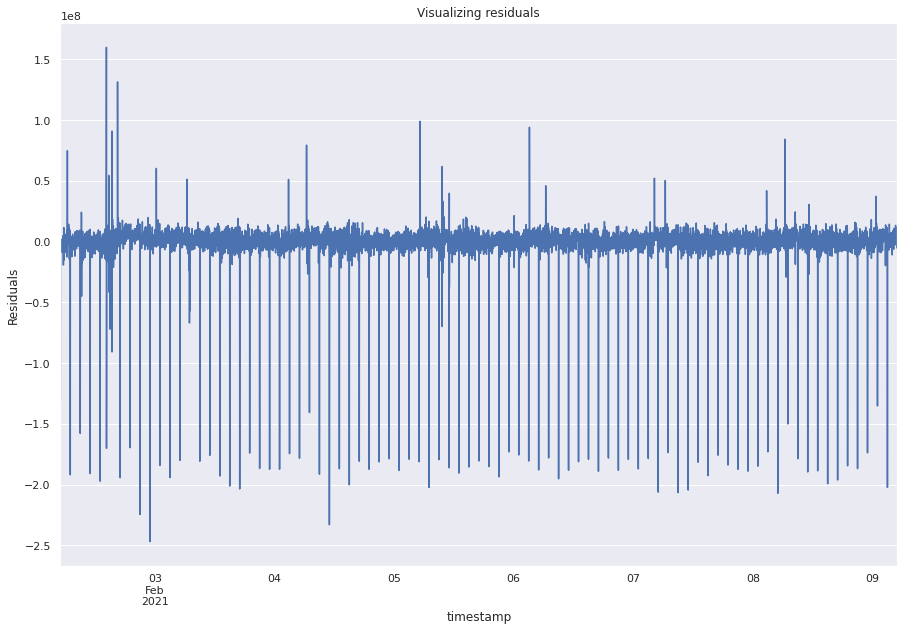
adfuller(resid_43)
(-17.905801779444907,
2.9419099978191365e-30,
32,
10047,
{'1%': -3.4310010372782322,
'5%': -2.8618277198980784,
'10%': -2.5669231481622323},
364128.5002131127)
sgt.plot_acf(resid_43, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
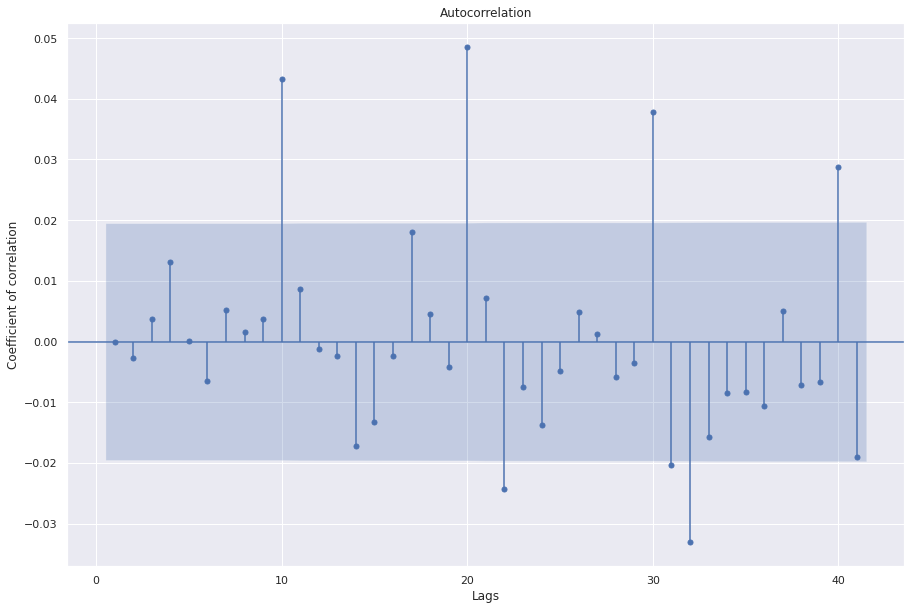
This plot has are several significant values in the PACF.
We can train higher order ARMA models but usually we have to go for ARIMA models.
ARIMA models¶
Auto-regressive integrated moving average model.
Since ARMA models do not work well with non-stationary data, we introduce integrations to make the data the stationary.
The model builds on the difference between the time periods (integerated values) instead of the values itself.
For example, converting prices to returns in stock market data would be similar to 1 degree of integration.
Intuitively, modelling returns instead of prices may be better since returns may resemble stationary data.
ARIMA has p, d, q hyperparameters.
d -> number of degree of changes to ensure stationarity.
One way of finding d is to compute delta of the data unitll stationarity is found.
ARIMA method uses AIC criteria to compare models with different orders.
The following equation represents ARIMA(1,1,1).
Start from a simple model and increase orders by looking at residuals.
\(\Delta\)Pt = c + \(\phi\)\(\Delta\)Pt-1 + \(\theta\)\(\epsilon\)t-1 + \(\epsilon\)t
arima_111 = ARIMA(ts, order=(1, 1, 1)).fit()
sgt.plot_acf(arima_111.resid, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
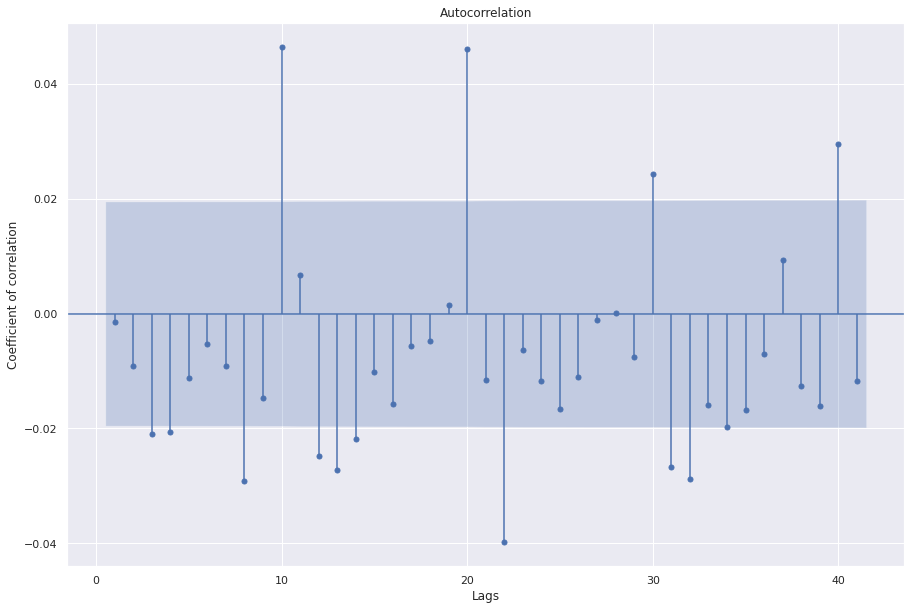
We see that the third lag is significant. We can try all models from ARIMA(0,0,0) to ARIMA(3,1,3).
p = range(0, 4)
d = range(0, 2)
q = range(0, 4)
pdq = list(itertools.product(p, d, q))
for i in range(1, len(pdq)):
print("Model: {}".format(pdq[i]))
results = []
for order in pdq:
try:
print(order)
model_arima_results = ARIMA(ts, order=order).fit()
results.append([order, model_arima_results.aic])
except ValueError as e:
print(order, "Error", e)
results.append([order, float("inf")])
Model: (0, 0, 1)
Model: (0, 0, 2)
Model: (0, 0, 3)
Model: (0, 1, 0)
Model: (0, 1, 1)
Model: (0, 1, 2)
Model: (0, 1, 3)
Model: (1, 0, 0)
Model: (1, 0, 1)
Model: (1, 0, 2)
Model: (1, 0, 3)
Model: (1, 1, 0)
Model: (1, 1, 1)
Model: (1, 1, 2)
Model: (1, 1, 3)
Model: (2, 0, 0)
Model: (2, 0, 1)
Model: (2, 0, 2)
Model: (2, 0, 3)
Model: (2, 1, 0)
Model: (2, 1, 1)
Model: (2, 1, 2)
Model: (2, 1, 3)
Model: (3, 0, 0)
Model: (3, 0, 1)
Model: (3, 0, 2)
Model: (3, 0, 3)
Model: (3, 1, 0)
Model: (3, 1, 1)
Model: (3, 1, 2)
Model: (3, 1, 3)
(0, 0, 0)
(0, 0, 1)
(0, 0, 2)
(0, 0, 2) Error The computed initial MA coefficients are not invertible
You should induce invertibility, choose a different model order, or you can
pass your own start_params.
(0, 0, 3)
(0, 0, 3) Error The computed initial MA coefficients are not invertible
You should induce invertibility, choose a different model order, or you can
pass your own start_params.
(0, 1, 0)
(0, 1, 1)
(0, 1, 2)
(0, 1, 3)
(1, 0, 0)
(1, 0, 1)
(1, 0, 2)
(1, 0, 3)
(1, 1, 0)
(1, 1, 1)
(1, 1, 2)
(1, 1, 3)
(1, 1, 3) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 0, 0)
(2, 0, 1)
(2, 0, 2)
(2, 0, 2) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 0, 3)
(2, 0, 3) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 1, 0)
(2, 1, 1)
(2, 1, 2)
(2, 1, 2) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(2, 1, 3)
(2, 1, 3) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(3, 0, 0)
(3, 0, 1)
(3, 0, 2)
(3, 0, 3)
(3, 1, 0)
(3, 1, 1)
(3, 1, 2)
(3, 1, 2) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
(3, 1, 3)
(3, 1, 3) Error The computed initial AR coefficients are not stationary
You should induce stationarity, choose a different model order, or you can
pass your own start_params.
results.sort(key=lambda x: x[1])
results
[[(3, 0, 3), 365487.8721028673],
[(3, 1, 1), 365691.8784901391],
[(1, 1, 2), 365691.92489760055],
[(2, 1, 1), 365696.89234631776],
[(2, 0, 1), 365718.12121591234],
[(1, 0, 2), 365718.9376581142],
[(3, 0, 1), 365719.51921091694],
[(1, 0, 3), 365720.09677661443],
[(3, 0, 0), 365720.1672000777],
[(1, 0, 1), 365721.14203969185],
[(3, 0, 2), 365721.5111232434],
[(2, 0, 0), 365726.38260047237],
[(1, 0, 0), 365822.7701546097],
[(2, 1, 0), 365854.88895507844],
[(0, 1, 2), 365854.9773183209],
[(0, 1, 3), 365856.0842035335],
[(3, 1, 0), 365856.5834094851],
[(1, 1, 1), 365857.4704805023],
[(0, 1, 1), 365868.8083093382],
[(1, 1, 0), 365875.05135895085],
[(0, 1, 0), 365939.7623796054],
[(0, 0, 1), 382895.5433298524],
[(0, 0, 0), 393845.016979624],
[(0, 0, 2), inf],
[(0, 0, 3), inf],
[(1, 1, 3), inf],
[(2, 0, 2), inf],
[(2, 0, 3), inf],
[(2, 1, 2), inf],
[(2, 1, 3), inf],
[(3, 1, 2), inf],
[(3, 1, 3), inf]]
ARIMA(ts, order=(3, 0, 3)).fit().summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | ARMA(3, 3) | Log Likelihood | -182735.936 |
| Method: | css-mle | S.D. of innovations | 18060470.382 |
| Date: | Tue, 20 Apr 2021 | AIC | 365487.872 |
| Time: | 19:20:38 | BIC | 365545.619 |
| Sample: | 02-02-2021 | HQIC | 365507.411 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 8.412e+08 | 5.4e+06 | 155.763 | 0.000 | 8.31e+08 | 8.52e+08 |
| ar.L1.value | 0.3450 | 0.003 | 120.383 | 0.000 | 0.339 | 0.351 |
| ar.L2.value | -0.4045 | 0.002 | -227.156 | 0.000 | -0.408 | -0.401 |
| ar.L3.value | 0.9630 | 0.003 | 336.179 | 0.000 | 0.957 | 0.969 |
| ma.L1.value | 0.7292 | 0.010 | 70.724 | 0.000 | 0.709 | 0.749 |
| ma.L2.value | 1.0668 | 0.006 | 165.921 | 0.000 | 1.054 | 1.079 |
| ma.L3.value | 0.1088 | 0.010 | 10.542 | 0.000 | 0.089 | 0.129 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | -0.3091 | -0.9511j | 1.0001 | -0.3000 |
| AR.2 | -0.3091 | +0.9511j | 1.0001 | 0.3000 |
| AR.3 | 1.0383 | -0.0000j | 1.0383 | -0.0000 |
| MA.1 | -0.3104 | -0.9510j | 1.0004 | -0.3002 |
| MA.2 | -0.3104 | +0.9510j | 1.0004 | 0.3002 |
| MA.3 | -9.1869 | -0.0000j | 9.1869 | -0.5000 |
sgt.plot_acf(ARIMA(ts, order=(3, 0, 3)).fit().resid, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
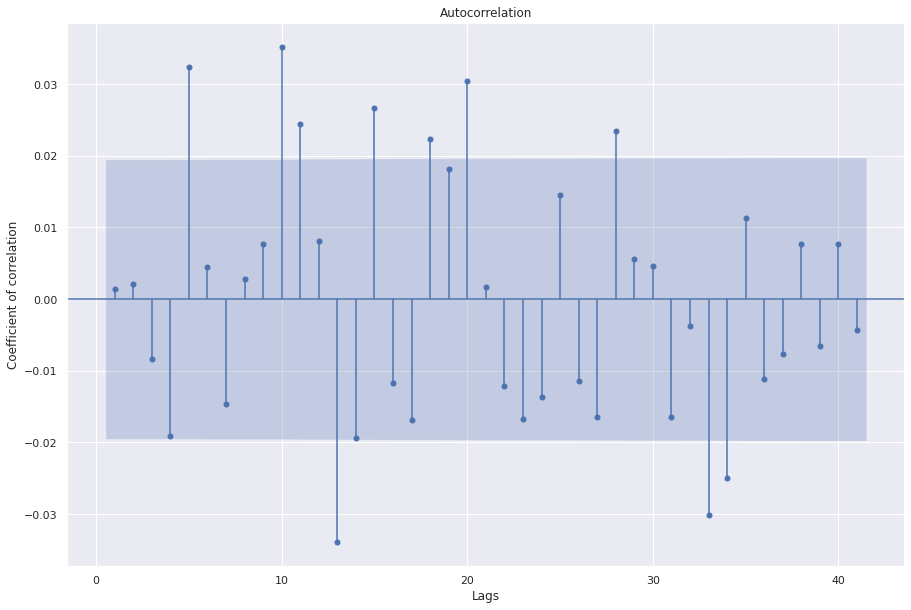
Great, we see that the first 4 coefficients are now not significant. At this point, as an additional exercise, we could try models with lag 5,6, and 7 as well to further improve performance. Next, we are going to look at how to select the value for “d”, or the number of integrations required for modelling the data. Remember that integrations are done to introduce stationarity and should be avoided if the data is already stationary. In this case, the adfuller test says that the data is stationary but ACF plot shows many significant correlations. Hence we try d as 1. Let’s manually compute 1 degree of integration and check stationarity.
adfuller(ts.diff(1)[1:])
(-19.127626021632747,
0.0,
39,
10039,
{'1%': -3.431001556217458,
'5%': -2.861827949213313,
'10%': -2.5669232702269893},
364359.1091279416)
sgt.plot_acf(ts.diff(1)[1:], zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
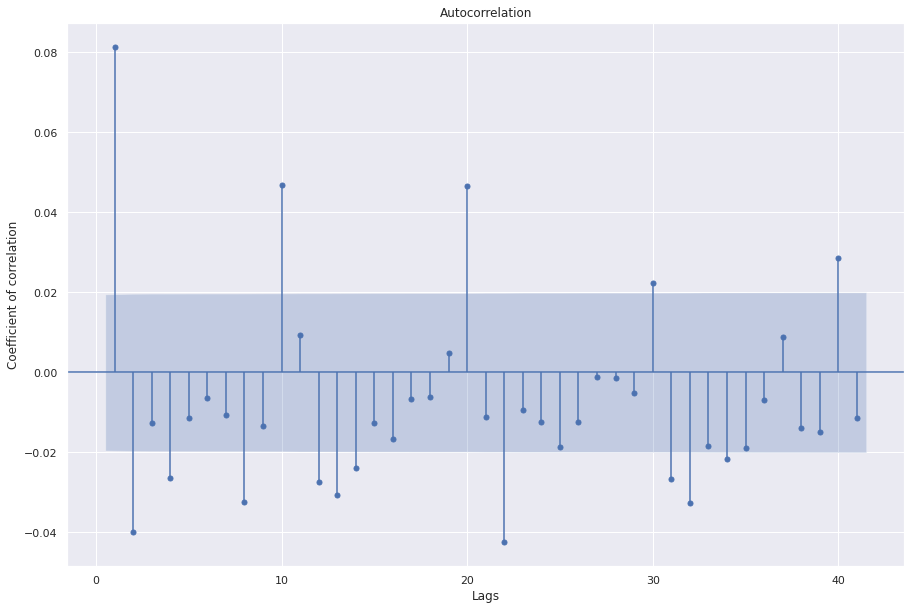
Cool, the ACF plot has less significant correlations and the adfuller test also indicates that after one integration the data is stationarity. For exercise, and a rigorous search for the best model, we could check for models with d=2 as well. However, we prefer simpler models over complex models if the improvements are not significant. Let’s fit ARIMA(3,1,1) and evaluate the results.
ARIMA_311 = ARIMA(ts, order=(3, 1, 1)).fit()
ARIMA_311.summary()
| Dep. Variable: | D.value | No. Observations: | 10079 |
|---|---|---|---|
| Model: | ARIMA(3, 1, 1) | Log Likelihood | -182839.939 |
| Method: | css-mle | S.D. of innovations | 18286554.066 |
| Date: | Tue, 20 Apr 2021 | AIC | 365691.878 |
| Time: | 19:24:48 | BIC | 365735.188 |
| Sample: | 02-02-2021 | HQIC | 365706.533 |
| - 02-09-2021 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 2.508e+04 | 2.57e+04 | 0.975 | 0.329 | -2.53e+04 | 7.55e+04 |
| ar.L1.D.value | 1.0645 | 0.010 | 105.994 | 0.000 | 1.045 | 1.084 |
| ar.L2.D.value | -0.1286 | 0.014 | -8.874 | 0.000 | -0.157 | -0.100 |
| ar.L3.D.value | 0.0265 | 0.010 | 2.644 | 0.008 | 0.007 | 0.046 |
| ma.L1.D.value | -0.9969 | 0.002 | -616.984 | 0.000 | -1.000 | -0.994 |
| Real | Imaginary | Modulus | Frequency | |
|---|---|---|---|---|
| AR.1 | 1.0425 | -0.0000j | 1.0425 | -0.0000 |
| AR.2 | 1.9075 | -5.7095j | 6.0197 | -0.1987 |
| AR.3 | 1.9075 | +5.7095j | 6.0197 | 0.1987 |
| MA.1 | 1.0031 | +0.0000j | 1.0031 | 0.0000 |
sgt.plot_acf(ARIMA_311.resid, zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
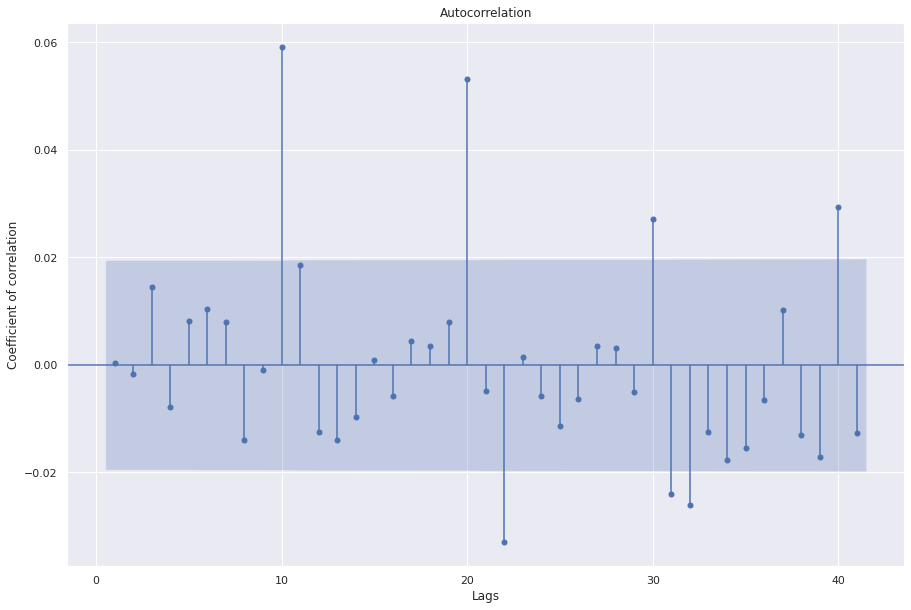
Cool, we see 9 insignificant coefficients indicating that this model is a good choice.
ARIMAX (Exogenous factors)¶
In addition to past observations, sometimes external factors also affect the future value of a time series
\(\Delta\)Pt = c + \(\beta\)X + \(\phi\)\(\Delta\)Pt-1 + \(\theta\)\(\epsilon\)t-1 + \(\epsilon\)t
X can be anything (data should be available for each period).
E.g. S&P prices for predicting a particular stock price.
\(\beta\) is a fitted coefficient.
SARIMAX (Seasonality)¶
Some time series have a seasonal aspect to them. For example, consider the number of views for a christmas song every month. Every year in December we can expect a spike in the series.
SARIMAX model includes a lag term for the last period.
Hyper parameters of SARIMAX: (p,d,q)(P,D,Q,s).
(p,d,q) is the ARIMA order.
‘s’ signifies how far behind do we observe the seasonal affect; s=1 means no seasonality.
In our number of songs example, the value of s will be 12.
P, Q specifies how many seasonal AR and MA terms we will have so for s=12, P=2, Q=1, the equation will have yt-12, yt-24, and \(\epsilon\)t-12
D specifies seasonal integrations.
The total number of coefficients for the model will be: P + Q + p + q coeffs.
In our current example we don’t see any seasonality but let’s train a SARIMAX model to understand how it works.
model_sarimax = SARIMAX(
ts, exog=wn, order=(3, 1, 1), seasonal_order=(2, 0, 1, 5)
).fit()
model_sarimax.summary()
| Dep. Variable: | value | No. Observations: | 10080 |
|---|---|---|---|
| Model: | SARIMAX(3, 1, 1)x(2, 0, 1, 5) | Log Likelihood | -182922.952 |
| Date: | Tue, 20 Apr 2021 | AIC | 365863.904 |
| Time: | 19:25:19 | BIC | 365928.868 |
| Sample: | 02-02-2021 | HQIC | 365885.886 |
| - 02-09-2021 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x1 | 0.0023 | 0.002 | 1.294 | 0.196 | -0.001 | 0.006 |
| ar.L1 | 0.0336 | 6.921 | 0.005 | 0.996 | -13.532 | 13.599 |
| ar.L2 | -0.0351 | 0.489 | -0.072 | 0.943 | -0.993 | 0.922 |
| ar.L3 | -0.0049 | 0.271 | -0.018 | 0.986 | -0.536 | 0.526 |
| ma.L1 | 0.0369 | 6.921 | 0.005 | 0.996 | -13.528 | 13.601 |
| ar.S.L5 | 0.1100 | 0.634 | 0.174 | 0.862 | -1.132 | 1.352 |
| ar.S.L10 | 0.0393 | 0.014 | 2.828 | 0.005 | 0.012 | 0.067 |
| ma.S.L5 | -0.1180 | 0.637 | -0.185 | 0.853 | -1.366 | 1.130 |
| sigma2 | 3.4e+14 | 4.69e-11 | 7.26e+24 | 0.000 | 3.4e+14 | 3.4e+14 |
| Ljung-Box (L1) (Q): | 1.92 | Jarque-Bera (JB): | 4208230.52 |
|---|---|---|---|
| Prob(Q): | 0.17 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.90 | Skew: | -9.25 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 101.38 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 4.51e+38. Standard errors may be unstable.
Automated¶
In the final section of this notebook, we show the use of auto_arima function of pmdarima library that automatically finds hyperparameters for a SARIMAX model.
However, we need to proceed with caution and do our due diligence before selecting a new model as automated values may choose a complicated model but in real life we may prefer a simpler one.
The function does dickey fuller test to find d; and uses one information criteria to select between models (default being “aic”).
The function does not look at whether all coefficients are significant or not, we have to consider that on our own.
## Calling auto arima with default settings
auto_arima_model = auto_arima(ts)
auto_arima_model.summary()
| Dep. Variable: | y | No. Observations: | 10080 |
|---|---|---|---|
| Model: | SARIMAX(2, 1, 3) | Log Likelihood | -182891.981 |
| Date: | Tue, 20 Apr 2021 | AIC | 365797.962 |
| Time: | 19:35:47 | BIC | 365848.489 |
| Sample: | 0 | HQIC | 365815.058 |
| - 10080 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| intercept | 2.587e+04 | 1.57e+04 | 1.645 | 0.100 | -4945.652 | 5.67e+04 |
| ar.L1 | 0.0825 | 0.428 | 0.193 | 0.847 | -0.756 | 0.921 |
| ar.L2 | 0.8286 | 0.401 | 2.065 | 0.039 | 0.042 | 1.615 |
| ma.L1 | -0.0225 | 0.427 | -0.053 | 0.958 | -0.860 | 0.815 |
| ma.L2 | -0.8740 | 0.370 | -2.362 | 0.018 | -1.599 | -0.149 |
| ma.L3 | -0.0758 | 0.050 | -1.521 | 0.128 | -0.174 | 0.022 |
| sigma2 | 3.4e+14 | 7.37e-05 | 4.62e+18 | 0.000 | 3.4e+14 | 3.4e+14 |
| Ljung-Box (L1) (Q): | 1.94 | Jarque-Bera (JB): | 4014680.83 |
|---|---|---|---|
| Prob(Q): | 0.16 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.89 | Skew: | -9.07 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 99.08 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 2.99e+32. Standard errors may be unstable.
## Evaluating residuals
sgt.plot_acf(auto_arima_model.resid(), zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
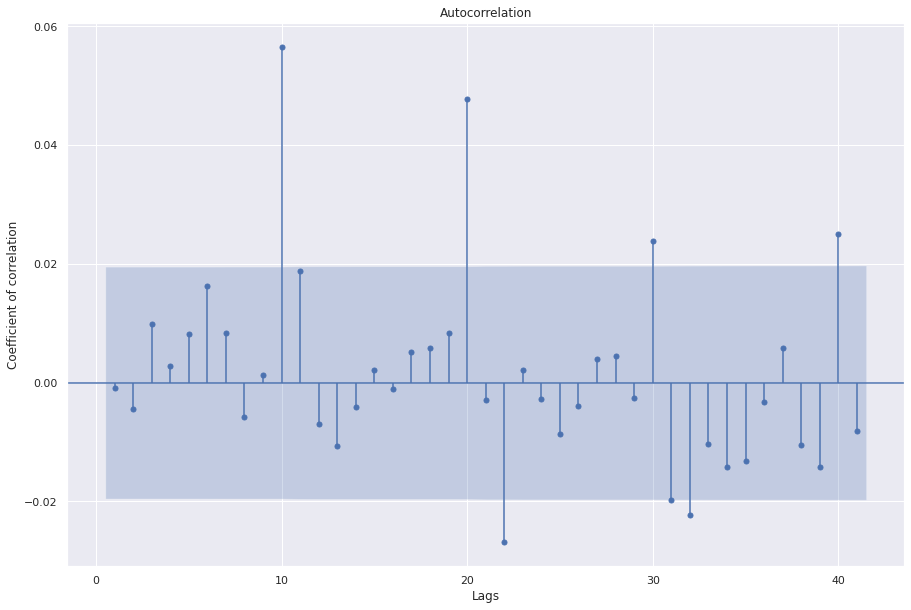
Here we see the auto_arima selects an ARIMA model with order 2,1,3. In our manual analysis using statsmodel package, the model with 2,1,3 could not converge. We can make changes to the default parameters to the function to give it more information.
An important information criteria is oob which selects model based on the score performance of the model on a validation set. Let’s try that.
## The commented parameters can be uncommented based on the need.
aam = auto_arima(
ts,
# exogenous=,
# m=12, SARIMAX s
max_order=None,
max_p=6, # Search till p=6
max_q=6, # Search till q=6
max_d=2, # Search till d=2
# max_P= #Search till P=2
# max_Q= #Search till Q=2
# max_D= #Search till D=2
maxiter=50, # Increase if you see no convergence
njobs=-1, # Number of parallel processes
# trend="ct", ##ctt for quadratic; accounts for trend in data
information_criterion="oob", # out of bag aic, aicc, bic, hqic
out_of_sample_size=int(len(ts) * 0.2), ## Validation set of 20% for oob
)
aam.summary()
| Dep. Variable: | y | No. Observations: | 10080 |
|---|---|---|---|
| Model: | SARIMAX(1, 1, 0) | Log Likelihood | -182942.835 |
| Date: | Tue, 20 Apr 2021 | AIC | 365891.670 |
| Time: | 19:37:05 | BIC | 365913.324 |
| Sample: | 0 | HQIC | 365898.997 |
| - 10080 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| intercept | 7711.9077 | 8.06e-12 | 9.57e+14 | 0.000 | 7711.908 | 7711.908 |
| ar.L1 | 0.0669 | 0.005 | 12.802 | 0.000 | 0.057 | 0.077 |
| sigma2 | 3.476e+14 | 1.08e-18 | 3.2e+32 | 0.000 | 3.48e+14 | 3.48e+14 |
| Ljung-Box (L1) (Q): | 3.05 | Jarque-Bera (JB): | 4207310.37 |
|---|---|---|---|
| Prob(Q): | 0.08 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.90 | Skew: | -9.25 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 101.37 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number inf. Standard errors may be unstable.
sgt.plot_acf(aam.resid(), zero=False)
plt.rc("figure", figsize=(15, 10))
plt.ylabel("Coefficient of correlation")
plt.xlabel("Lags")
plt.show()
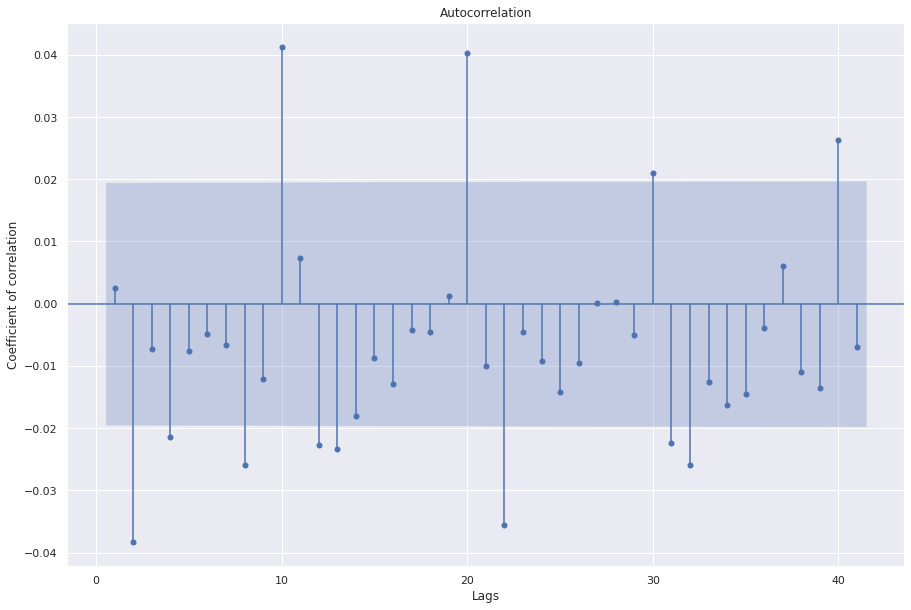
With updated parameters, especially the information criterion as “oob” we see the function selects an inferior model in terms of AIC and significance of the coefficients. However this model performs well on the validation set. We need to conduct further experiments with a test set to find the generalizability of these models.
Conclusion¶
Awesome! Apologies for a really long notebook, but we have learnt how to understand characteristics of a time series and then how to model it. Next, we are going to look at how we can forecast using these models.
Referrences¶
A lot of the content in this notebook has been adapted from this youtube playlist.