Table of Contents
Contents
Table of Contents#
Research on current industry offerings#
Find a curated list of companies involved in AI/ML for CI/CD here.
Architecture Diagram#
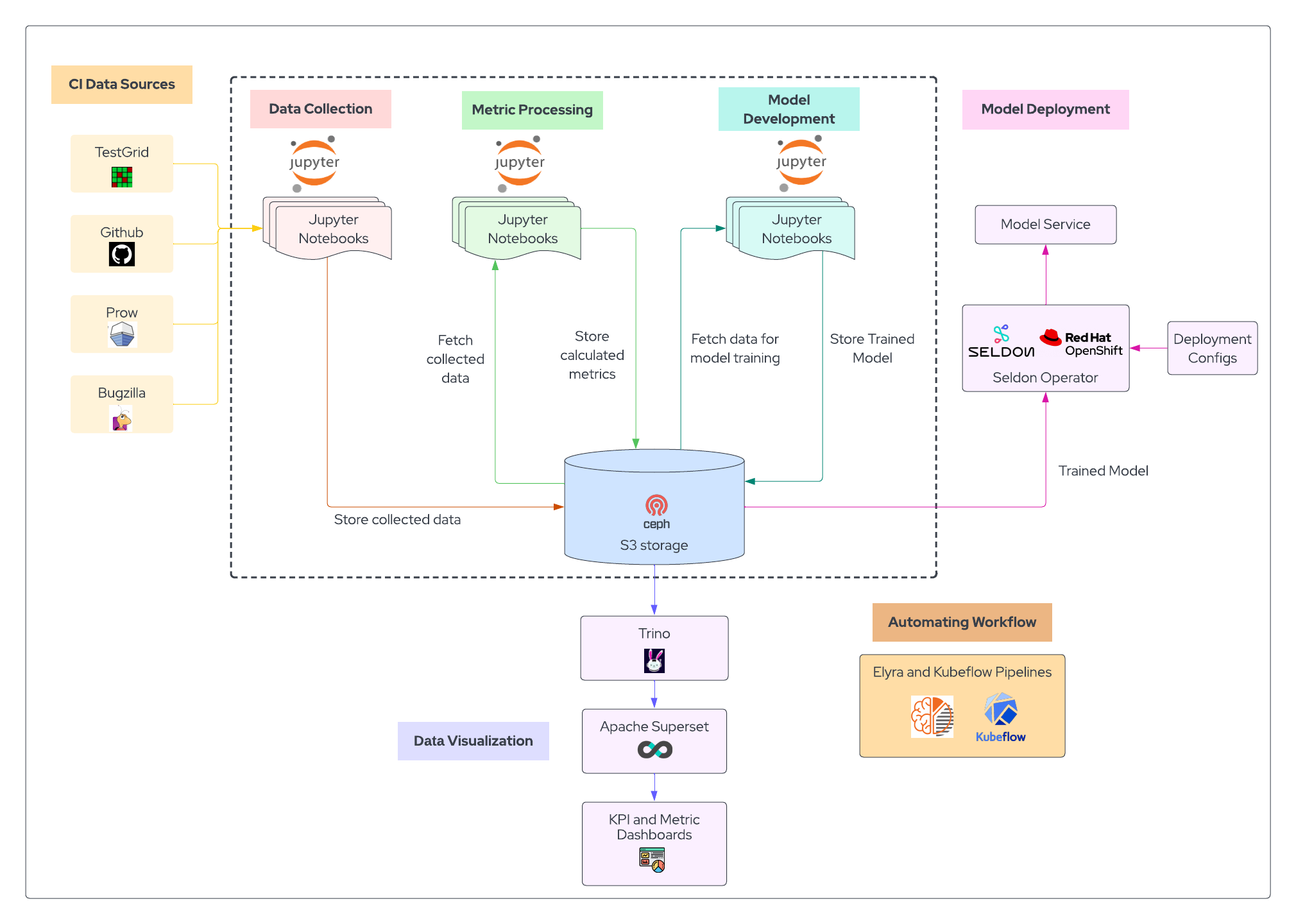
Data Engineering: Metrics and KPIs for CI#
Before we attempt to apply any AI or machine learning techniques to improve the CI workflow, it is important that we know how to both quantify and evaluate the current state of the CI workflow. In order to do this we must establish and collect the relevant metrics and key performance indicators (KPIs) needed to measure it. This is a critical first step as it allows us to quantify the state of CI operations, as well as apply the KPIs we will need to evaluate the impact of our AI tools in the future.
There are currently five open datasets that can be used to help us fully describe the CI process: Testgrid, Prow, Github, Telemetry and Bugzilla. This data is currently stored in disparate locations and does not exist in a data science friendly format ready for analysis. Below are our current efforts to collect and prepare each of these datasets for further analysis.
TestGrid:#
According to the project’s readme, TestGrid is a, “highly configurable, interactive dashboard for viewing your test results in a grid!” In other words, it’s an aggregation and visualization platform for CI data. Testgrid primarily reports categorical metrics about which tests passed or failed during specific builds over a configurable time window.
Data Collection
Data Exploration
Metrics and KPIs
Visualization of Metrics
Automate Workflows
Prow/GCS Artifacts:#
TestGrid provides the results of tests, but if we want to triage an issue and see the actual logs generated during the building and testing process, we will need to access the logs generated by prow and stored in google cloud storage. This dataset contains all of the log data generated for each build and each job as directories and text files in remote storage.
Github:#
The builds and tests run by the CI process are required because of changes that are happening in the applications code base. The goal of CI is to automatically identify if any of these code changes will cause problems for the deployed application. Therefore, we also include information such as metadata and diff’s about the PR’s associated with the builds run by Prow. This dataset contains a mix of numerical, categorical and textual data types.
GitHub PR EDA
Bugzilla:#
Bugzilla is Red Hat’s bug-tracking system and is used to submit and review defects that have been found in Red Hat distributions. In addition to TestGrid, analyzing bugs related to OpenShift CI can help us get into automated root cause analysis. This is primarily a dataset of human written text.
Telemetry:#
The builds and tests we are interested in analyzing run in the cloud and produce metrics about the resources they are using and report any alerts they experience while running. These metrics are stored in Thanos for users to query. Here we have primarily numerical time series data that describes the underlying state of the cluster running these builds and tests.
Machine Learning and Analytics Projects#
With the data sources made easily accessible and with the necessary metrics and KPIs available to quantify and evaluate the CI workflow we can start to apply some AI and machine learning techniques to help improve the CI workflow. There are many ways in which this could be done given the multimodal, multi-source nature of our data. Instead of defining a single specific problem to solve, our current aim is to use this repository as a hub for multiple machine learning and analytics projects centered around this data for AIOps problems focused on improving CI workflows. Below is a list of the current ML and analytics projects.
Github Time to Merge Prediction#
To quantify critical metrics within a software development workflow, we can start by calculating metrics related to code contributions. One such metric which can help identify bottlenecks within the development process can be the time taken to merge an open pull request. By predicting the time that it could take to merge a PR, we can better allocate development resources.
We would like to create a GitHub bot that ingests information from a PR, including the written description, author, number of files, etc, in addition to the diff, and returns a prediction for how long it will take to be merged. For that, we train a model which can predict the time taken to merge a PR and classifies it into one of a few predefined time ranges.
Interactive model endpoint: http://github-pr-ttm-ds-ml-workflows-ws.apps.smaug.na.operate-first.cloud/predict
Model Inference Notebook
Time to Merge Model Training Notebook
Deployment Configuration for Seldon Service
TestGrid Failure Type Classification#
Currently, human subject matter experts are able to identify different types of failures by looking at the testgrids. This is, however, a manual process. This project aims to automate the manual identification process for individual Testgrids. This can be thought of as a classification problem aimed at classifying errors on the testgrids as either flakey tests, infra flakes, install flakes or new test failures.
Prow Log Classification#
Logs represent a rich source of information for automated triaging and root cause analysis. Unfortunately, logs are very noisy data types, i.e, two logs that are of the same type but from two different sources may be different enough at a character level that traditional comparison methods are insufficient to capture this similarity. To overcome this issue, we will use the Prow logs made available to us by this project to identify useful methods for learning log templates that denoise log data and help improve performance on downstream ML tasks.
We start by applying a clustering algorithm to job runs based on the term frequency within their build logs to group job runs according to their type of failure.
Optimal Stopping Point Prediction#
Every new Pull Request to a repository with new code changes is subjected to an automated set of builds and tests before being merged. Some tests may run for longer durations for various reasons such as unoptimized algorithms, slow networks, or the simple fact that many different independent services are part of a single test. Longer running tests are often painful as they can block the CI/CD process for longer periods of time. By predicting the optimal stopping point for the test, we can better allocate development resources.
TestGrid is a platform that is used to aggregate and visually represent the results of all these automated tests. Based on test and build time duration data available on testgrid, we can predict and suggest a stopping point, beyond which a given test is likely to result in a failure.
Interactive model endpoint: http://optimal-stopping-point-ds-ml-workflows-ws.apps.smaug.na.operate-first.cloud/predict
Deployment Configuration for Seldon Service
More Projects Coming Soon…#
Automate Notebook Pipelines using Elyra and Kubeflow#
In order to automate the sequential running of the various notebooks in the project responsible for data collection, metric calculation, ML analysis, we are using Kubeflow Pipelines. For more information on using Elyra and Kubeflow pipelines to automate the notebook workflows you can go through the following resources.