Probability To Fail
Contents
Probability To Fail#
One of the key performance indicators that we would like to create greater visibility into and for a given moment in time, is to calculate what is the probability that a given test will fail. Using this information, we plan to build a model that uses the probability to fail to predict the time to failure.
In order to provide maxium flexibility for the end-user of this work, instead of creating a number of dataframes to answer each of these specifc questions, we will define a long and narrow data structure (a list of tuples saved as a csv for now) that contains only 7 columns (“timestamp”, “tab”,”grid”,”test”,”test_duration”, “pass_or_fail”, “prob”). This allows visualization tools like Superset (or pandas) to perform the last filter and/or aggregate interested columns to an end user. Which is to say, there may be a lot of repetition within the final data set, but each row should be unique, and it should provide the simplest usability for an end-user.
Linked issue(s) : Issue
import json
import gzip
import os
import pandas as pd
import datetime
from sklearn.svm import SVC
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
from sklearn.calibration import calibration_curve
from sklearn.metrics import brier_score_loss, roc_auc_score
from matplotlib import pyplot
import numpy as np
from ipynb.fs.defs.metric_template import testgrid_labelwise_encoding
from ipynb.fs.defs.metric_template import CephCommunication
from ipynb.fs.defs.metric_template import save_to_disk, read_from_disk
from dotenv import load_dotenv, find_dotenv
import warnings
warnings.filterwarnings("ignore")
load_dotenv(find_dotenv())
True
## Specify variables
METRIC_NAME = "probability_to_fail"
# Specify the path for input grid data,
INPUT_DATA_PATH = "../../../../data/raw/testgrid_183.json.gz"
# Specify the path for output metric data
OUTPUT_DATA_PATH = f"../../../../data/processed/metrics/{METRIC_NAME}"
# Specify whether or not we are running this as a notebook or part of an automation pipeline.
AUTOMATION = os.getenv("IN_AUTOMATION")
## CEPH Bucket variables
## Create a .env file on your local with the correct configs,
s3_endpoint_url = os.getenv("S3_ENDPOINT")
s3_access_key = os.getenv("S3_ACCESS_KEY")
s3_secret_key = os.getenv("S3_SECRET_KEY")
s3_bucket = os.getenv("S3_BUCKET")
s3_path = os.getenv("S3_PROJECT_KEY", "ai4ci/testgrid/metrics")
s3_input_data_path = "raw_data"
metric_path = f"metrics/{METRIC_NAME}"
## Import data
timestamp = datetime.datetime.today()
if AUTOMATION:
filename = f"testgrid_{timestamp.day}{timestamp.month}.json"
cc = CephCommunication(s3_endpoint_url, s3_access_key, s3_secret_key, s3_bucket)
s3_object = cc.s3_resource.Object(s3_bucket, f"{s3_input_data_path}/{filename}")
file_content = s3_object.get()["Body"].read().decode("utf-8")
testgrid_data = json.loads(file_content)
else:
with gzip.open(INPUT_DATA_PATH, "rb") as read_file:
testgrid_data = json.load(read_file)
Calculation#
# We will now fetch all the tests which are failing i.e. have a status code of 12.
failures_list = testgrid_labelwise_encoding(testgrid_data, 12, overall_only=False)
# Convert to dataframe
failures_df = pd.DataFrame(
failures_list,
columns=["timestamp", "tab", "grid", "test", "test_duration", "failure"],
)
failures_df.head()
| timestamp | tab | grid | test | test_duration | failure | |
|---|---|---|---|---|---|---|
| 0 | 2021-08-25 19:11:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.800000 | False |
| 1 | 2021-08-25 18:31:23 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 17.350000 | True |
| 2 | 2021-08-25 14:51:42 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.933333 | False |
| 3 | 2021-08-23 00:01:04 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 95.300000 | False |
| 4 | 2021-08-22 08:53:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 101.800000 | False |
# We will fetch all the tests which are passing i.e. have status code of 1.
passing_list = testgrid_labelwise_encoding(testgrid_data, 1, overall_only=False)
# Convert to dataframe
passing_df = pd.DataFrame(
passing_list,
columns=["timestamp", "tab", "grid", "test", "test_duration", "passing"],
)
passing_df.head()
| timestamp | tab | grid | test | test_duration | passing | |
|---|---|---|---|---|---|---|
| 0 | 2021-08-25 19:11:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.800000 | True |
| 1 | 2021-08-25 18:31:23 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 17.350000 | False |
| 2 | 2021-08-25 14:51:42 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.933333 | True |
| 3 | 2021-08-23 00:01:04 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 95.300000 | True |
| 4 | 2021-08-22 08:53:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 101.800000 | True |
df = pd.merge(
failures_df,
passing_df,
on=["timestamp", "tab", "grid", "test", "test_duration"],
)
df = df.dropna()
df.head()
| timestamp | tab | grid | test | test_duration | failure | passing | |
|---|---|---|---|---|---|---|---|
| 0 | 2021-08-25 19:11:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.800000 | False | True |
| 1 | 2021-08-25 18:31:23 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 17.350000 | True | False |
| 2 | 2021-08-25 14:51:42 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 91.933333 | False | True |
| 3 | 2021-08-23 00:01:04 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 95.300000 | False | True |
| 4 | 2021-08-22 08:53:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 101.800000 | False | True |
df.shape
(19938777, 7)
Calculate Probability to Fail using SVM and Calibrated Classification Model#
In order to calculate the probability to fail, some of the approaches we could consider are SVM (support vector machines) and a Calibrated Classification Model. In this section of the notebook, we will compare the SVM and Calibrated Classification model, and choose the model giving better results.
The objective of the support vector machine algorithm is to find a hyperplane in an N-dimensional space(N — the number of features) that distinctly classifies the data points. SVM is a good candidate model to calibrate because it does not natively predict probabilities, meaning the probabilities are often uncalibrated. The probabilities are not normalized, but can be normalized when calling the calibration_curve() function by setting the normalize argument to True.
An SVM model can be created using the scikit learn module.
A classification predictive modeling problem requires predicting or forecasting a label for a given observation. An alternative to predicting the label directly, a model may predict the probability of an observation belonging to each possible class label. Although a model may be able to predict probabilities, the distribution and behavior of the probabilities may not match the expected distribution of observed probabilities in the training data. The distribution of the probabilities can be adjusted to better match the expected distribution observed in the data. This adjustment is referred to as calibration, as in the calibration of the model or the calibration of the distribution of class probabilities.
A classifier can be calibrated using the CalibratedClassifierCV sci-kit library. We will generate the labels/classes required for classification and train the model on a subset of the data set.
## This helper function will add pass/fail labels to enable classification model
## i.e 1-"Pass", 0-"Failure".
def p_f_label(row):
if row["passing"]:
return 1
elif row["failure"]:
return 0
## Create a sample df with a batch of 10000 to start with.
sample_df = df[0:10000]
## Add the pass_or_fail label using the helper function `p_f_label`
sample_df["pass_or_fail"] = sample_df.apply(lambda row: p_f_label(row), axis=1)
## For all the missing test_duration values, drop the row.
sample_df = sample_df.dropna()
## Labels for multiclass classification
sample_df.pass_or_fail.unique()
sample_df.pass_or_fail.value_counts()
1.0 9837
0.0 135
Name: pass_or_fail, dtype: int64
Resampling the data#
From above, we see that we have an imbalanced dataset i.e the classes are not represented equally, and this can lead to misleading classification accuracy results. To handle this issue of imbalanced datasets, we will resample the data. Resampling is a widely-adopted technique for dealing with imbalanced datasets by changing the dataset into a more balanced one by:
Undersampling - This simply deletes instances from the over-represented class (majority class) in different ways. The most obvious way is to do delete instances randomly.
Oversampling - This method adds copies of instances from the under-represented class (minority class) to obtain a balanced dataset. There are multiple ways you can oversample a dataset, like random oversampling.
Let’s implement the basic method of undersampling and oversampling, which uses the DataFrame.sample method to get random samples of each class:
# Class count
count_class_1, count_class_0 = sample_df.pass_or_fail.value_counts()
df_class_1 = sample_df[sample_df["pass_or_fail"] == 1]
df_class_0 = sample_df[sample_df["pass_or_fail"] == 0]
Undersampling#
Here, we delete instances randomly from the over-represented class i.e. for our dataset the ‘Pass (1)’ class.
# Divide by class
df_class_1_under = df_class_1.sample(count_class_0)
df_us = pd.concat([df_class_1_under, df_class_0], axis=0)
print("Random under-sampling:")
print(df_us.pass_or_fail.value_counts())
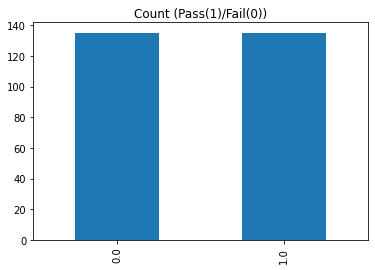
df_us.pass_or_fail.value_counts().plot(kind="bar", title="Count (Pass(1)/Fail(0))")
Random under-sampling:
0.0 135
1.0 135
Name: pass_or_fail, dtype: int64
<AxesSubplot:title={'center':'Count (Pass(1)/Fail(0))'}>
Oversampling#
Here, we add instances randomly to the under-represented class i.e. for our dataset the ‘Fail (0)’ class.
# Divide by class
df_class_0_over = df_class_0.sample(count_class_1, replace=True)
df_os = pd.concat([df_class_1, df_class_0_over], axis=0)
print("Random over-sampling:")
print(df_os.pass_or_fail.value_counts())
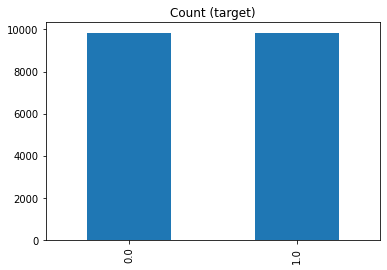
df_os.pass_or_fail.value_counts().plot(kind="bar", title="Count (target)")
Random over-sampling:
0.0 9837
1.0 9837
Name: pass_or_fail, dtype: int64
<AxesSubplot:title={'center':'Count (target)'}>
SVM#
Now, we will fit the SVM model to calculate the probabilities. Let’s run it for both the under and over sampled data and compare.
## Create X = test_duration and y = pass_or_fail and calculate probabilty for under sampled data
X, y = np.array([df_us["test_duration"].values]), np.array(
[df_us["pass_or_fail"].values]
)
X = X.reshape(-1, 1)
y = y.reshape(-1, 1)
# split into train/test sets.
trainx, testx, trainy, testy = train_test_split(
X, y, train_size=0.8, test_size=0.2, random_state=42
)
# fit a SVM Model.
model = SVC(probability=True).fit(trainx, trainy)
# Evaluate the model
y_pred = model.predict(testx)
# predict probabilities.
probs_train = model.predict_proba(trainx)[:, 0]
probs_test = model.predict_proba(testx)[:, 0]
probs = np.append(probs_train, probs_test, axis=None)
df_us["prob"] = probs
NOTE : The probabilities are not normalized, but can be normalized when calling the calibration_curve() function by setting the normalize argument to True.
# Mean accuracy on the given test data and labels.
svm_accuracy = model.score(testx, testy)
print("SVM Model accuracy :", svm_accuracy)
svm_brier = brier_score_loss(testy, y_pred, pos_label=1)
print("SVM Brier Score", svm_brier)
svm_roc = roc_auc_score(testy, y_pred)
print("SVM Roc Score", svm_roc)
SVM Model accuracy : 0.8888888888888888
SVM Brier Score 0.1111111111111111
SVM Roc Score 0.8859890109890111
Brier Score is a distance in the probability domain. Which means: the lower the value of this score, the better the prediction.
The above calculated score is a harsh metric since we require for each sample that each label set be correctly predicted. This does not give us a clear indication of a better model so we will use the reliability diagram to find out the better suited model.
Reliability Diagram#
A reliability diagram is a line plot of the relative frequency of what was observed (y-axis) versus the predicted probability frequency (x-axis). These plots are commonly referred to as ‘reliability‘ diagrams in forecast literature, although may also be called ‘calibration‘ plots or curves as they summarize how well the forecast probabilities are calibrated.
The better calibrated or more reliable a forecast, the closer the points will appear along the main diagonal from the bottom left to the top right of the plot.
# reliability diagram
fop, mpv = calibration_curve(testy, probs_test, n_bins=10, normalize=True)
# plot perfectly calibrated
pyplot.plot([0, 1], [0, 1], linestyle="--")
# plot model reliability
pyplot.plot(mpv, fop, marker=".")
pyplot.xlabel("Mean predicted Value")
pyplot.ylabel("Relative Frequency")
pyplot.title("SVM Reliability Diagram")
pyplot.show()
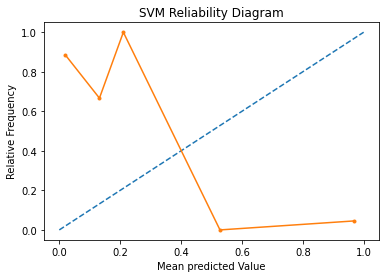
In the above graph, the solid line represents the calibration of the SVMs predicted probabilities and the dotted line represents a comparison to a perfectly calibrated model. The better calibrated or more reliable a forecast, the closer the points will appear along the main diagonal from the bottom left to the top right of the plot. Here, we see that calibration probabilities are much further away from the ideal prediction.
The position of the points or the curve relative to the diagonal can help to interpret the probabilities; for example:
Below the diagonal: The model has over-forecast; the probabilities are too large.
Above the diagonal: The model has under-forecast; the probabilities are too small.
SVM for over sampled data#
## Create X = test_duration and y = pass_or_fail and calculate probabilty for over sampled data
X, y = np.array([df_os["test_duration"].values]), np.array(
[df_os["pass_or_fail"].values]
)
X = X.reshape(-1, 1)
y = y.reshape(-1, 1)
# split into train/test sets.
trainx, testx, trainy, testy = train_test_split(
X, y, train_size=0.8, test_size=0.2, random_state=42
)
# fit a SVM Model.
model = SVC(probability=True).fit(trainx, trainy)
# Evaluate the model
y_pred = model.predict(testx)
# predict probabilities.
probs_train = model.predict_proba(trainx)[:, 0]
probs_test = model.predict_proba(testx)[:, 0]
probs = np.append(probs_train, probs_test, axis=None)
df_os["prob"] = probs
# Mean accuracy on the given test data and labels.
svm_accuracy = model.score(testx, testy)
print("SVM Model accuracy :", svm_accuracy)
svm_brier = brier_score_loss(testy, y_pred, pos_label=1)
print("SVM Brier Score", svm_brier)
svm_roc = roc_auc_score(testy, y_pred)
print("SVM Roc Score", svm_roc)
SVM Model accuracy : 0.9110546378653113
SVM Brier Score 0.08894536213468869
SVM Roc Score 0.9108594984441994
Brier Score is a distance in the probability domain. Which means: the lower the value of this score, the better the prediction.
The above calculated score is a harsh metric since we require for each sample that each label set be correctly predicted. This does not give us a clear indication of a better model so we will use the reliability diagram to find out the better suited model.
We also see that we achieved a higher accuracy of ~81% with over sampling of the data compared to the ~78% accuracy with the under sampled data.
Reliability Diagram#
A reliability diagram is a line plot of the relative frequency of what was observed (y-axis) versus the predicted probability frequency (x-axis). These plots are commonly referred to as ‘reliability‘ diagrams in forecast literature, although may also be called ‘calibration‘ plots or curves as they summarize how well the forecast probabilities are calibrated.
The better calibrated or more reliable a forecast, the closer the points will appear along the main diagonal from the bottom left to the top right of the plot.
# reliability diagram
fop, mpv = calibration_curve(testy, probs_test, n_bins=10, normalize=True)
# plot perfectly calibrated
pyplot.plot([0, 1], [0, 1], linestyle="--")
# plot model reliability
pyplot.plot(mpv, fop, marker=".")
pyplot.xlabel("Mean predicted Value")
pyplot.ylabel("Relative Frequency")
pyplot.title("SVM Reliability Diagram")
pyplot.show()
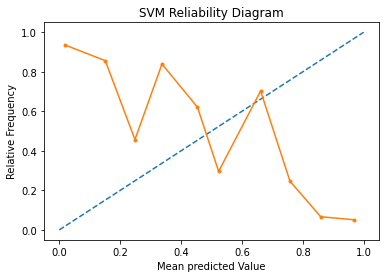
In the above graph, the solid line represents the calibration of the SVMs predicted probabilities and the dotted line represents a comparison to a perfectly calibrated model. The better calibrated or more reliable a forecast, the closer the points will appear along the main diagonal from the bottom left to the top right of the plot. Here, we see that calibration probabilities are much further away from the ideal prediction.
The position of the points or the curve relative to the diagonal can help to interpret the probabilities; for example:
Below the diagonal: The model has over-forecast; the probabilities are too large.
Above the diagonal: The model has under-forecast; the probabilities are too small.
Since this graph indicates that the probabilities calculated by SVM are too small, we shall move forward and look in the Calibrated Classification Model.
Calibrated Classification Model#
CalibratedClassifierCV class using 5-fold cross-validation, to calibrate the predicted probabilities.
Since the over sampled data resulted in a better accuracy, we will consider this dataset for training the Calibrated Classification Model
## Create X = test_duration and y = pass_or_fail and calculate probabilty for over sampled data.
X, y = np.array([df_os["test_duration"].values]), np.array(
[df_os["pass_or_fail"].values]
)
X = X.reshape(-1, 1)
y = y.reshape(-1, 1)
# split into train/test sets.
trainx, testx, trainy, testy = train_test_split(
X, y, train_size=0.8, test_size=0.2, random_state=42
)
# fit a Calibrated Classification Model.
model = SVC(probability=False)
calibrated = CalibratedClassifierCV(model, method="isotonic", cv=5)
calibrated.fit(trainx, trainy)
# Evaluate model
y_pred = calibrated.predict(testx)
# predict probabilities.
probs_train = calibrated.predict_proba(trainx)[:, 0]
probs_test = calibrated.predict_proba(testx)[:, 0]
probs = np.append(probs_train, probs_test, axis=None)
df_os["prob"] = probs
NOTE : The probabilities are not normalized, but can be normalized when calling the calibration_curve() function by setting the normalize argument to True.
# Mean accuracy on the given test data and labels.
cc_accuracy = calibrated.score(testx, testy)
print("CCM Model accuracy :", cc_accuracy)
cc_brier = brier_score_loss(testy, y_pred, pos_label=1)
print("CCM Brier Score", cc_brier)
cc_roc = roc_auc_score(testy, y_pred)
print("CCM Roc Score", cc_roc)
CCM Model accuracy : 0.9146124523506989
CCM Brier Score 0.08538754764930115
CCM Roc Score 0.9143269806101052
Brier Score is a distance in the probability domain. Which means: the lower the value of this score, the better the prediction.
The above calculated score is a harsh metric since we require for each sample that each label set be correctly predicted. This does not give us a clear indication of a better model so we will use the reliability diagram to find out the better suited model.
Reliability Diagram#
A reliability diagram is a line plot of the relative frequency of what was observed (y-axis) versus the predicted probability frequency (x-axis). These plots are commonly referred to as ‘reliability‘ diagrams in forecast literature, although may also be called ‘calibration‘ plots or curves as they summarize how well the forecast probabilities are calibrated.
The better calibrated or more reliable a forecast, the closer the points will appear along the main diagonal from the bottom left to the top right of the plot.
# reliability diagram
fop, mpv = calibration_curve(testy, probs_test, n_bins=10, normalize=True)
# plot perfectly calibrated
pyplot.plot([0, 1], [0, 1], linestyle="--")
# plot model reliability
pyplot.plot(mpv, fop, marker=".")
pyplot.xlabel("Mean predicted Value")
pyplot.ylabel("Relative Frequency")
pyplot.title("Calibrated Classification Reliability Diagram")
pyplot.show()
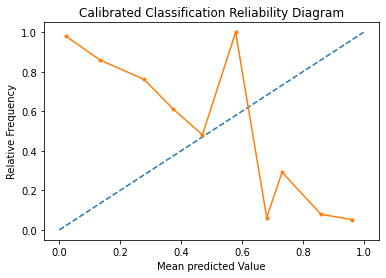
Here, we see that the shape of the calibrated probabilities is different, hugging the diagonal line much better, although still under-forecasting and over-forecasting i.e. the solid line is both above and below the ideal model.
Visually, the plot suggests a better calibrated model.
## Store only the valuable columns.
combined_df = df_os[["timestamp", "tab", "grid", "test", "prob"]]
We now have the probabilities for each test likely to fail stored in the column prob.
Save results to Ceph or locally#
Use the following helper function to save the data frame in a parquet format on the Ceph bucket if we are running in automation, and locally if not.
timestamp = datetime.datetime.now()
if AUTOMATION:
cc = CephCommunication(s3_endpoint_url, s3_access_key, s3_secret_key, s3_bucket)
cc.upload_to_ceph(
combined_df.head(1000000),
"s3_path",
f"{METRIC_NAME}/{METRIC_NAME}-{timestamp.year}-{timestamp.month}-{timestamp.day}.parquet",
)
else:
save_to_disk(
combined_df.head(1000000),
OUTPUT_DATA_PATH,
f"{METRIC_NAME}-{timestamp.year}-{timestamp.month}-{timestamp.day}.parquet",
)
## Sanity check to see if the dataset is the same
if AUTOMATION:
sanity_check = cc.read_from_ceph(
"s3_path",
f"{METRIC_NAME}/{METRIC_NAME}-{timestamp.year}-{timestamp.month}-{timestamp.day}.parquet",
)
else:
sanity_check = read_from_disk(
OUTPUT_DATA_PATH,
f"{METRIC_NAME}-{timestamp.year}-{timestamp.month}-{timestamp.day}.parquet",
)
sanity_check
| timestamp | tab | grid | test | prob | |
|---|---|---|---|---|---|
| 0 | 2021-08-25 19:11:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.955633 |
| 2 | 2021-08-25 14:51:42 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.000000 |
| 3 | 2021-08-23 00:01:04 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.037275 |
| 4 | 2021-08-22 08:53:17 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.911741 |
| 5 | 2021-08-20 23:21:32 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.132383 |
| ... | ... | ... | ... | ... | ... |
| 12 | 2021-08-16 00:01:05 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.132383 |
| 1545 | 2021-08-16 03:07:16 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | TestInstall_test_install.start_install_and_wai... | 0.955633 |
| 1547 | 2021-08-13 04:53:07 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | TestInstall_test_install.start_install_and_wai... | 0.037275 |
| 1509 | 2021-08-11 20:45:05 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.000000 |
| 8141 | 2021-08-19 15:58:19 | "redhat-assisted-installer" | periodic-ci-openshift-release-master-nightly-4... | Overall | 0.955633 |
19674 rows × 5 columns
Conclusion :#
In this notebook, we calculated for a given moment in time, what is the probability that a test will fail. Using this information, we plan to build a model that uses the probability to fail value to predict the time to failure, that is how many days, weeks, months, hours, minutes or seconds do you have until the test in question stops working. As next steps, we plan to work on this issue.