TestGrid In-Depth EDA
Contents
TestGrid In-Depth EDA#
Note: This notebook can be run and experimented with directly using the “ocp-ci-analysis” image at our jupyterhub instance hosted on the MOC.
In our previous notebook, TestGrid_EDA, we did some straightforward data access and preprocessing work in order to take a look at what data TestGrid exposes, how to access it and convert the test grids themselves into 2d arrays. While performing that initial data exploration we came up with a few more questions around how to look at this data in aggregate that we want to address here.
In this notebook we will try and answer the following questions about the TestGrid data:
How comparable are the TestGrids?
How do we analyze the TestGrids in aggregate to learn from their combined behavior?
How many/ which tests are the most common?
Are their time series dates comparable?
Are there sub-groups that should only be compared with one another?
Is looking at the grid matrices independent of test names a valid approach for issue identification?
What is the expected behavior of a test over time across multiple jobs.
How does the entire test platform/specific tests perform on a given day?
How does a test/ the entire test platform behavior evolve over time.
Is there sufficient data here for useful ML approaches?
Can we develop some meaningful alerting/ problem identification based on the results of the above questions?
import gzip
import json
import re
import pandas as pd
import numpy as np
from itertools import groupby
from scipy.stats import kurtosis
from scipy.signal import convolve2d
import datetime
from sklearn.linear_model import Ridge
from sklearn.cluster import DBSCAN
from sklearn.decomposition import IncrementalPCA
from IPython.display import Image
import matplotlib.pyplot as plt
import seaborn as sns
from ipynb.fs.defs.testgrid_EDA import decode_run_length
sns.set(rc={"figure.figsize": (20, 10)})
%matplotlib inline
with gzip.open("../../../data/raw/testgrid_810.json.gz", "rb") as read_file:
data = json.load(read_file)
1. How comparable are the TestGrids?#
Lets start by answering the first question on our list, “How comparable are the TestGrids?”
TestGrids are made of a set of tests which either pass or fail over time. They are multidimensional time series where the values can take either 12 (fail), 1 (pass) or 0 (not run). There are a few other status codes used, but we will ignore them for now. We want to know if they are always the same shape, and composed of the same tests. And if not, how do they vary?
Image(filename="../../../docs/assets/images/testgrid_0.png")
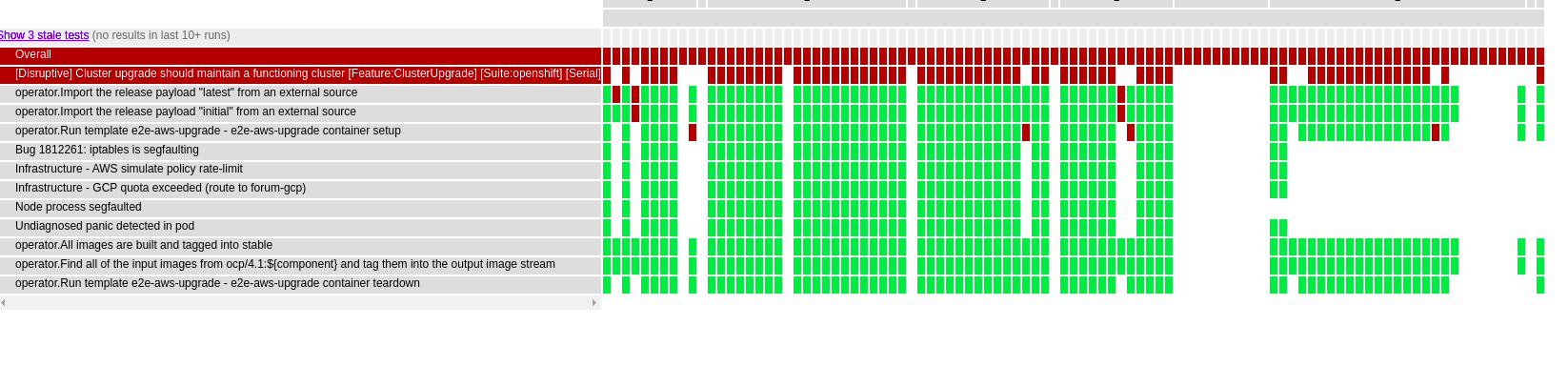
1.a) Are there duplicate grids?#
The first thing we will do is look at all the summaries and grid names to see if there is any overlap. Are there duplicate grids for different platforms?
# count all grids and uniquely nameed grids
c = 0
grid_names = set()
for i in data.keys():
for j in data[i].keys():
grid_names.add(j)
c += 1
print(len(grid_names))
print(c)
403
403
It appears as though the answer to our question, “are there duplicate grids?” is no. There a 403 individual grids by name and all grids appear to be unique. However, there seems to be a lot of similarity in naming convention between grids where only the only difference is version number. Let’s remove those references and see how many groups there are and how they compare.
1.b) Are there sub-groups?#
# count all the unique grids with version numbers removed.
c = 0
grid_names = set()
for i in data.keys():
for j in data[i].keys():
remove_version = re.sub(r"\d", "X", j)
grid_names.add(remove_version)
c += 1
print(len(grid_names))
print(c)
131
403
Great, we can now see that there are 131 grid types if we remove the version. This means that on average, a grid type is repeated about 3 times. Or stays useful for 3 versions.
This might represent a challenge since that is a fair amount of uniqueness when it comes to making statistical claims about the behavior of these grids (since there are only 3 members of each sample).
Now that we have identified these 131 cross-version grid types, lets look at each type and see what percent of tests they share. Can they be compared directly (do they have the same shape and tests)?
2. How comparable are individual tests?#
Lets ignore the grids as whole units for a minute and examine the occurrence of specific tests. Which are the most common? How many many unique tests are there? How should we expect them to behave?
2.a) What are the most common tests?#
# Count the number of tests present across the entire platform
all_tests = []
for i in data.keys():
for j in data[i].keys():
tests = [x["name"] for x in data[i][j]["grid"]]
all_tests.append(tests)
all_tests = [item for sublist in all_tests for item in sublist]
len(all_tests)
177291
# This tells us what percent a specific test is present across all grids.
# Where c is the total number of tests.
pd.Series(all_tests).value_counts() / c
Overall 0.915633
operator.All images are built and tagged into stable 0.786600
operator.Import the release payload "latest" from an external source 0.751861
operator install authentication 0.533499
operator install machine-config 0.533499
...
Create a test namespace.creates test namespace test-gpmwe if necessary 0.002481
Create a test namespace.creates test namespace test-btywt if necessary 0.002481
[sig-storage] In-tree Volumes [Driver: cinder] [Testpattern: Dynamic PV (ntfs)][sig-windows] subPath should support readOnly file specified in the volumeMount [LinuxOnly] [Suite:openshift/conformance/parallel] [Suite:k8s] 0.002481
Create a test namespace.creates test namespace test-kzmgo if necessary 0.002481
[sig-storage] Projected optional updates should be reflected in volume [NodeConformance] [Conformance] [Suite:openshift/conformance/parallel/minimal] [Suite:k8s] 0.002481
Length: 7798, dtype: float64
# This tells us the count of a specific test and filters only for tests that occur at least 10 times
test_counts = pd.Series(all_tests).value_counts()
test_counts[test_counts.values > 10]
Overall 369
operator.All images are built and tagged into stable 317
operator.Import the release payload "latest" from an external source 303
operator install authentication 215
operator install machine-config 215
...
operator.Run template e2e-gcp-serial - e2e-gcp-serial container test 11
[Disruptive] Cluster upgrade [Top Level] [Disruptive] Cluster upgrade should maintain a functioning cluster [Feature:ClusterUpgrade] [Serial] [Suite:openshift] 11
operator.Find all of the input images from ocp/4.1:${component} and tag them into the output image stream 11
[sig-auth][Feature:OpenShiftAuthorization][Serial] authorization TestAuthorizationResourceAccessReview should succeed [Suite:openshift/conformance/serial] 11
[sig-network] IngressClass [Feature:Ingress] should not set default value if no default IngressClass [Serial] [Suite:openshift/conformance/serial] [Suite:k8s] 11
Length: 3137, dtype: int64
We can see above that there are 177,291 test instances across all 403 grids. Of those tests, there are only 7,798 unique tests which is over a ~20x reduction.
Somewhat contrary to the findings in the earlier section, this tells us that there is a fair amount of overlap of tests among grids. Perhaps our criteria for comparison above was too strict, and we should employ some more fuzzy matching methods.
We can also see that of these ~7k unique tests, 3,137 (about 1/3) occur across at least 10 grids. So it is probably this subset that we could use for comparisons and determining average behavior of a test overtime.
Let’s look at one of the most common tests and see what we can say about its overall behavior.
2.b) Single Test Behavior Analysis#
We will use “operator.All images are built and tagged into stable” since it looks like it impacts ~80% of our grids.
target_test = "operator.All images are built and tagged into stable"
collected_target_tests = []
timestamps = []
for i in data.keys():
for j in data[i].keys():
grid = data[i][j]["grid"]
if len(grid) == 0:
continue
if target_test in [x["name"] for x in grid]:
test_data = [x["statuses"] for x in grid if x["name"] == target_test]
collected_target_tests.append(test_data)
timestamps.append(data[i][j]["timestamps"])
def get_timeseries_by_name(data, test_name):
collected_target_tests = []
timestamps = []
for i in data.keys():
for j in data[i].keys():
grid = data[i][j]["grid"]
if len(grid) == 0:
continue
if test_name in [x["name"] for x in grid]:
test_data = [x["statuses"] for x in grid if x["name"] == test_name]
collected_target_tests.append(test_data)
timestamps.append(data[i][j]["timestamps"])
ts_data = pd.DataFrame(
zip(collected_target_tests, timestamps), columns=["values", "time"]
)
# use the decode_run_length function imported from TestGrid_EDA notebook
ts_data["values"] = ts_data["values"].apply(lambda x: x[0]).apply(decode_run_length)
ts_data["time"] = ts_data["time"].apply(lambda x: (np.array(x) // 1000))
ts_data["time"] = ts_data["time"].apply(
lambda x: [datetime.datetime.fromtimestamp(y) for y in x]
)
return ts_data
print(len(collected_target_tests))
print(len(timestamps))
317
317
Great, this particular test has 317 examples, which means of the 403 grids its used in 78%. Let see if we have roughly the same number of samples for each instance of this test.
# use the decode_run_length function imported from TestGrid_EDA notebook
pd.DataFrame(collected_target_tests, columns=["RL"])["RL"].apply(
decode_run_length
).apply(len)
0 118
1 867
2 181
3 15
4 15
...
312 32
313 104
314 30
315 23
316 50
Name: RL, Length: 317, dtype: int64
So we can see from the above output that the we have a very different number of data points for a test depending on which grid it is associated with. This again, creates a problem for making direct comparisons between these tests.
But that’s alright, there are a number of ways this issue can be addressed. For now, lets go ahead, and generate some statistics about each time series. We can then define “normal behavior” as the average of these statistics as an initial naive approach to comparing tests in aggregate.
# Create a dataframe for all of the "operator.All images are built and tagged into stable" time series data
ts_data = pd.DataFrame(
zip(collected_target_tests, timestamps), columns=["values", "time"]
)
# use the decode_run_length function imported from TestGrid_EDA notebook
ts_data["values"] = ts_data["values"].apply(lambda x: x[0]).apply(decode_run_length)
ts_data["time"] = ts_data["time"].apply(lambda x: (np.array(x) // 1000))
ts_data["time"] = ts_data["time"].apply(
lambda x: [datetime.datetime.fromtimestamp(y) for y in x]
)
ts_data.head(1)
| values | time | |
|---|---|---|
| 0 | [0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, ... | [2020-10-08 20:48:05, 2020-10-08 19:12:01, 202... |
### Plot the first ten time series to see what we are working with
sns.set(rc={"figure.figsize": (11, 8)})
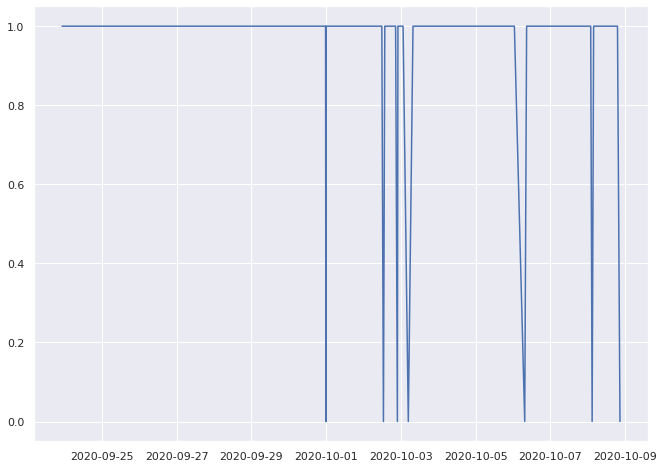
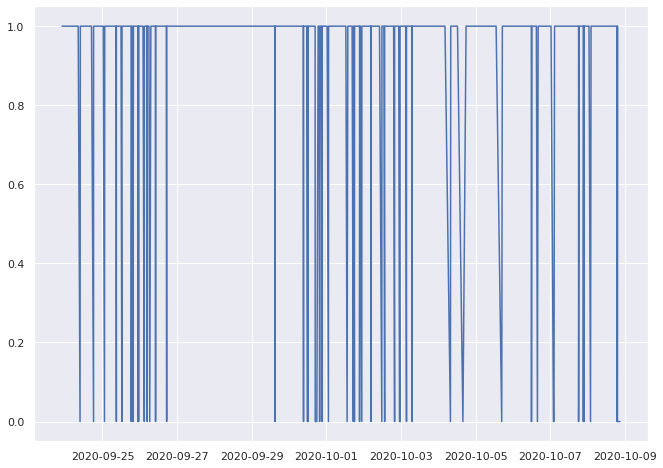
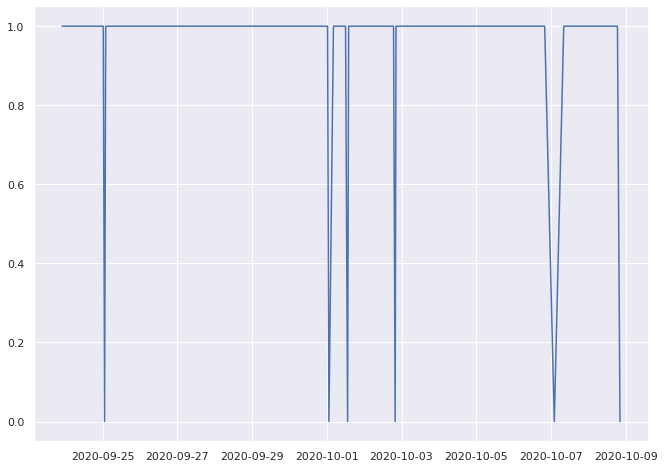
for i in range(len(ts_data))[0:10]:
print(f"{sum(ts_data.loc[i,'values'])/len(ts_data.loc[i,'values'])}% pass \n")
plt.plot(ts_data.loc[i, "time"], ts_data.loc[i, "values"])
plt.show()
print("\n")
0.940677966101695% pass
0.9319492502883506% pass
0.9668508287292817% pass
0.7333333333333333% pass
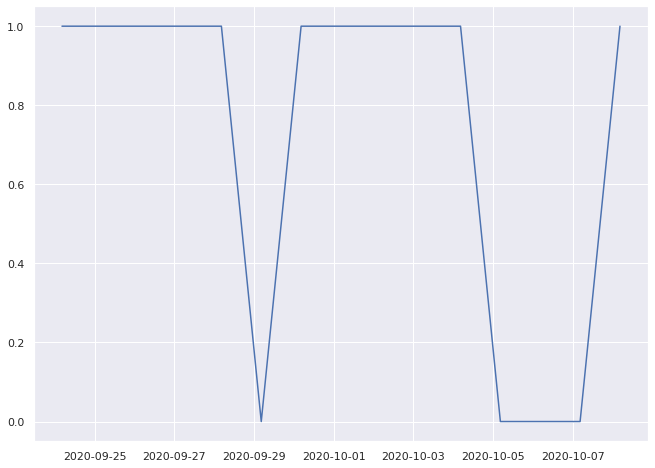
1.0% pass
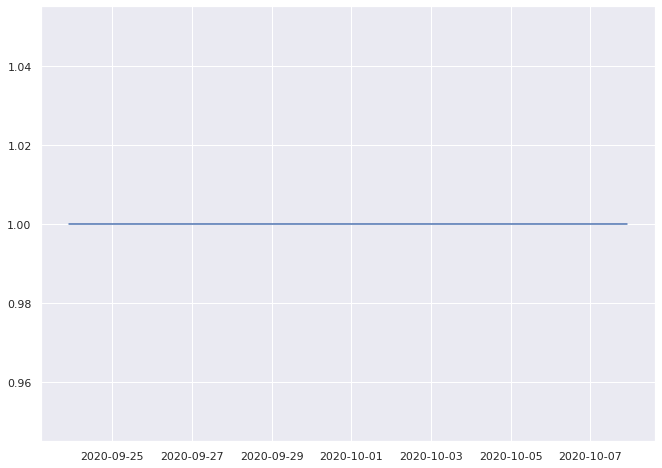
1.0% pass
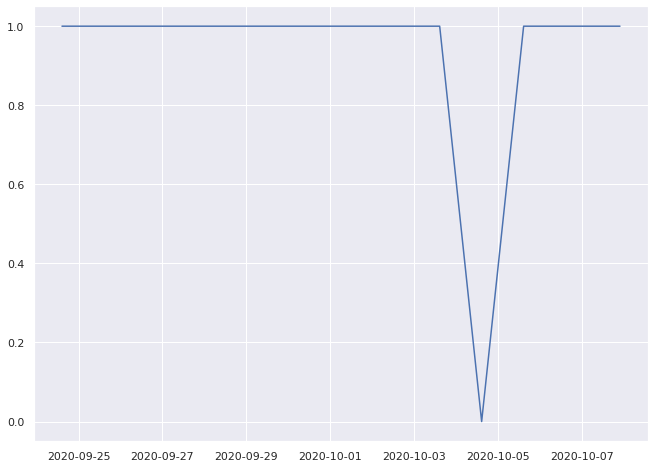
0.9333333333333333% pass
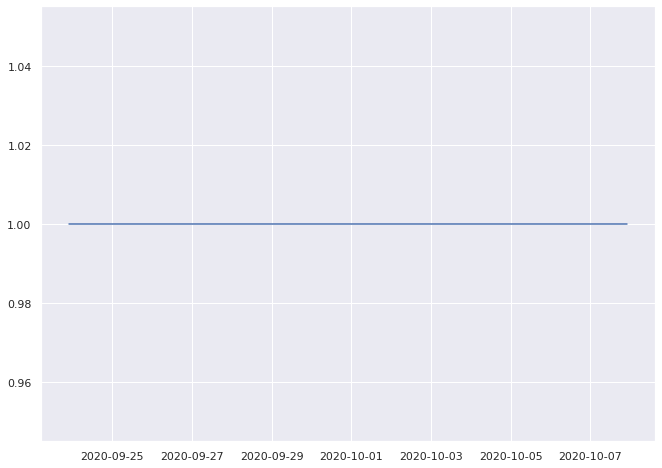
1.0% pass
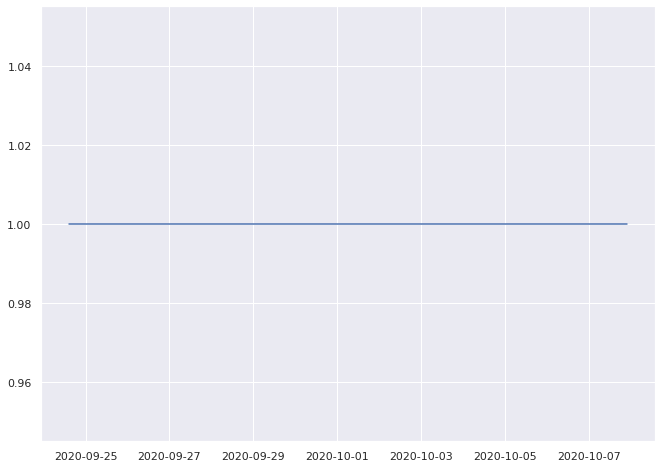
0.8333333333333334% pass
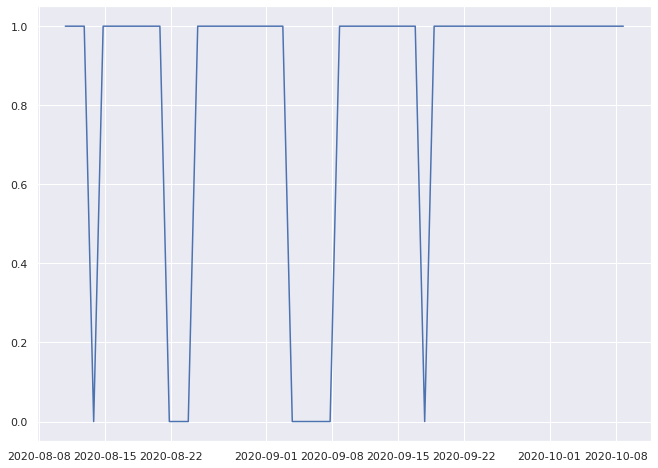
0.8333333333333334% pass
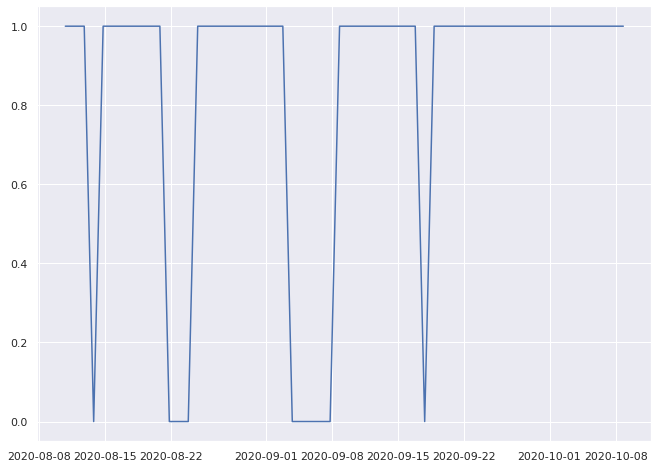
Since these time series are of unequal length, and we want to encode their general behavior to make comparisons, lets convert each of them into a vector of features based on some statistical properties of the time series.
Selected Features
pass rate
regression slope
regression intercept
longest failure streak ratio
kurtosis ratio
largest frequency ratio
There are obviously many ways to convert time series into a fixed length feature vector. But we’ll use these as I think they are fairly interesting and will allow us to move forward. But I encourage future contributors to question/update/change these selected features. :)
# Functions for calculating each feature from the time seires.
def get_regression_coefs(data):
lr = Ridge()
x = np.array(range(len(data))).reshape(-1, 1)
y = np.array(data).reshape(-1, 1)
lr.fit(x, y)
line = lr.predict(x)
return lr.coef_, line[0]
def longest_failure_streak(x):
prev_streak = 0
for n, c in groupby(x):
if n == 12:
count = sum(1 for i in c)
if count > prev_streak:
prev_streak = count
return prev_streak
def largest_frequncy(x):
f = np.fft.fft(x).real / len(x)
f = f[range(int(len(x) / 2))]
if len(f[1:]) > 0:
return f[1:].argmax() / len(x)
else:
return 0
def get_test_individual_behavior(test):
description = []
for i, ts in enumerate(test):
pass_rate = sum([x for x in ts if x == 1]) / len(ts)
coef, intercept = get_regression_coefs(ts)
failure_streak = longest_failure_streak(ts) / len(ts)
kurtosiss = kurtosis(ts) / len(ts)
frequency = largest_frequncy(ts)
description.append(
(
pass_rate,
float(coef),
float(intercept),
failure_streak,
kurtosiss,
frequency,
)
)
return description
indivudial_metric = pd.DataFrame(
get_test_individual_behavior(ts_data["values"]),
columns=[
"pass_rate",
"slope",
"intercept",
"failures_streak",
"kurtosis",
"frequency",
],
)
indivudial_metric
| pass_rate | slope | intercept | failures_streak | kurtosis | frequency | |
|---|---|---|---|---|---|---|
| 0 | 0.940678 | 0.001494 | 0.853298 | 0.0 | 0.101019 | 0.161017 |
| 1 | 0.931949 | 0.000109 | 0.884678 | 0.0 | 0.011266 | 0.085352 |
| 2 | 0.966851 | 0.000391 | 0.931698 | 0.0 | 0.139232 | 0.016575 |
| 3 | 0.733333 | 0.046263 | 0.409490 | 0.0 | -0.059091 | 0.200000 |
| 4 | 1.000000 | 0.000000 | 1.000000 | 0.0 | -0.200000 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... |
| 312 | 0.968750 | 0.002382 | 0.931832 | 0.0 | 0.844758 | 0.250000 |
| 313 | 0.990385 | 0.000549 | 0.962088 | 0.0 | 0.952016 | 0.298077 |
| 314 | 0.966667 | -0.004225 | 1.027930 | 0.0 | 0.834483 | 0.066667 |
| 315 | 0.782609 | 0.002962 | 0.750032 | 0.0 | -0.005314 | 0.304348 |
| 316 | 0.880000 | 0.006434 | 0.722368 | 0.0 | 0.069394 | 0.360000 |
317 rows × 6 columns
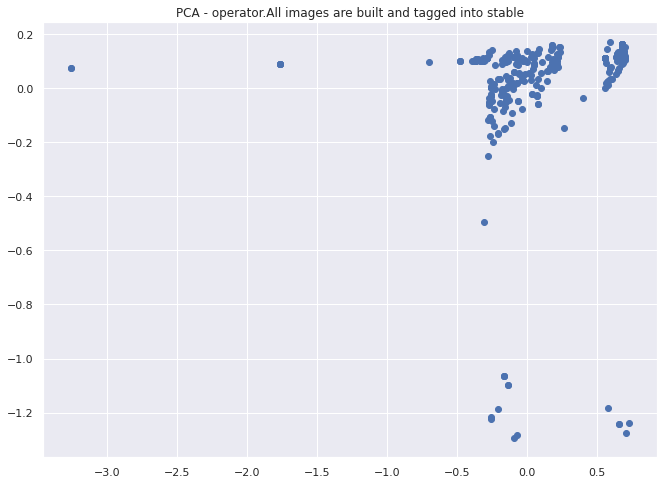
We’ve now converted our 317 variable length binary time series data into a tabular data set with 6 features that represent the behavior of our tests over time. The benefit of doing this is that we can now apply some classic machine learning approaches, like dimensionality reduction and clustering to our data.
Lets visualize the instances of this test and see if any obvious structure jumps out.
Visualizing our tests#
First we will apply PCA to reduce our 6 dimensional data down to 2 for visualization purposes. Then we will apply DBSCAN to identify any clusters or outliers that might be present in our data.
X = indivudial_metric
ipca = IncrementalPCA(n_components=2, batch_size=10)
ipca.fit(X)
two_d = ipca.transform(X)
plt.scatter(two_d[:, 0], two_d[:, 1])
plt.title("PCA - operator.All images are built and tagged into stable")
plt.show()
X = indivudial_metric
cluster = DBSCAN().fit(X)
fig, ax = plt.subplots()
scatter = ax.scatter(two_d[:, 0], two_d[:, 1], c=cluster.labels_)
legend1 = ax.legend(*scatter.legend_elements(), loc="lower left", title="Classes")
plt.title("DBSCAN - operator.All images are built and tagged into stable")
plt.show()
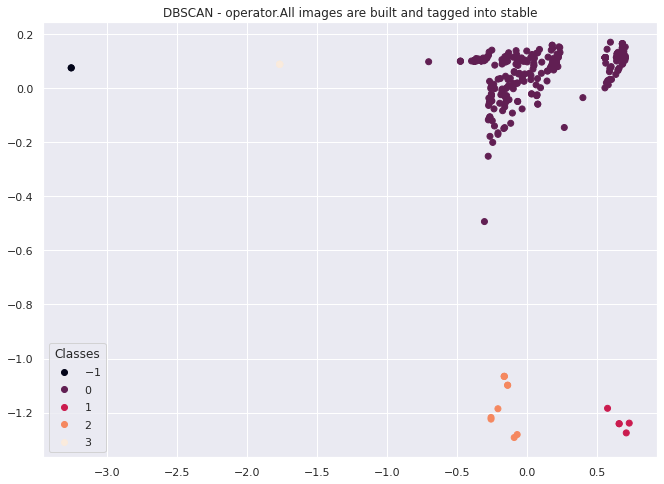
It looks like this method works to cluster individual test behavior across multiple instances of the same test. In this case we have divide the space into 4 clusters with a couple of outliers that we could investigate further.
For the purposes of this notebook,we have established at least one method for encoding and categorizing the behavior of tests that are all of the same type. We will now move on to another topic.
In the future this could be used to classify different types of observed errors for tests found in TestGrids
2.c) Multiple Test Behavior#
Lets just quickly take a look at a larger portion of th entire data set that we have and see if we notice anything from clustering across multiple tests, i.e. are there types of behavior clusters we can identify.
note: Using all 117k tests is rather slow, so I’ll limit it only to ~12k from the first 200 grids for the purposes of this notebook
first_pass = True
for i in all_tests[1:200]:
if first_pass:
tsx = get_timeseries_by_name(data, i)
tsx["name"] = i
first_pass = False
else:
next_ts = get_timeseries_by_name(data, i)
next_ts["name"] = i
tsx = tsx.append(next_ts, ignore_index=True)
tsx.shape
(11927, 3)
indivudial_metric = pd.DataFrame(
get_test_individual_behavior(tsx["values"]),
columns=[
"pass_rate",
"slope",
"intercept",
"failures_streak",
"kurtosis",
"frequency",
],
)
indivudial_metric.head()
| pass_rate | slope | intercept | failures_streak | kurtosis | frequency | |
|---|---|---|---|---|---|---|
| 0 | 0.016949 | -0.036272 | 3.765972 | 0.016949 | 0.021369 | 0.084746 |
| 1 | 0.237601 | 0.001266 | 1.793203 | 0.008074 | 0.000992 | 0.003460 |
| 2 | 0.000000 | -0.076442 | 10.962582 | 0.372881 | -0.015939 | 0.237288 |
| 3 | 0.000000 | -0.024003 | 10.001448 | 0.166667 | -0.008263 | 0.000000 |
| 4 | 0.000000 | -0.056302 | 12.105453 | 0.388889 | 0.002778 | 0.022222 |
X = indivudial_metric
ipca = IncrementalPCA(n_components=2, batch_size=10)
ipca.fit(X)
two_d = ipca.transform(X)
plt.scatter(two_d[:, 0], two_d[:, 1])
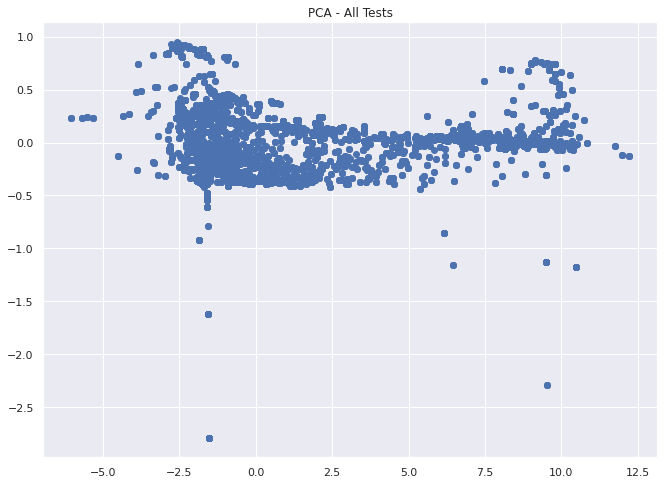
plt.title("PCA - All Tests")
plt.show()
X = indivudial_metric
cluster = DBSCAN().fit(X)
fig, ax = plt.subplots()
scatter = ax.scatter(two_d[:, 0], two_d[:, 1], c=cluster.labels_)
legend1 = ax.legend(*scatter.legend_elements(), loc="lower left", title="Classes")
plt.title("DBSCAN - All Tests")
plt.show()
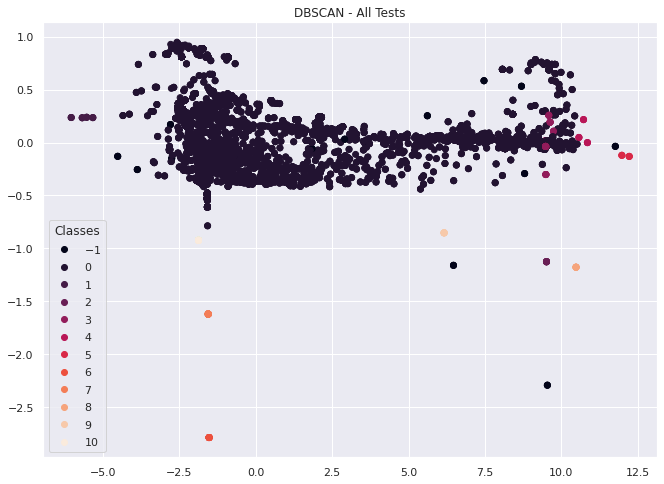
Based on the image above, its looks like we get something close to a 2d uniform distribution of our dataset with a few outliers and smaller clusters when we take a larger portion of our tests at once with this feature set.
This might be noise or it might show that most time series behave in a similar way, or cluster into one of the other 10 failure types.
In either case, we can use these methods outlined above to investigate this approach further in a later notebook.
2.d) Comparing tests in aggregate#
Now that we’ve looked at individual tests, lets derive a new object that describes a single test as the aggregation of the features we’ve defined above for every instance of the same test.
def get_test_behavior(test):
description = {}
pass_rate = 0
avg_coef = 0
avg_intercept = 0
avg_failure_streak = 0
avg_kurtosis = 0
avg_frequency = 0
for i, ts in enumerate(test):
pass_rate += sum([x for x in ts if x == 1]) / len(ts)
coef, intercept = get_regression_coefs(ts)
avg_coef += coef
avg_intercept += intercept
avg_failure_streak += longest_failure_streak(ts) / len(ts)
avg_kurtosis += kurtosis(ts) / len(ts)
avg_frequency += largest_frequncy(ts)
description["pass_rate"] = pass_rate / (i + 1)
description["avg_coef"] = float(avg_coef / (i + 1))
description["avg_intercept"] = float(avg_intercept / (i + 1))
description["avg_failure_streak"] = avg_failure_streak / (i + 1)
description["avg_kurtosis"] = avg_kurtosis / (i + 1)
description["avg_frequency"] = avg_frequency / (i + 1)
return description
single_test = get_timeseries_by_name(
data, "operator.All images are built and tagged into stable"
)
get_test_behavior(single_test["values"])
{'pass_rate': 0.911815196098699,
'avg_coef': -0.00031722304811730484,
'avg_intercept': 0.9199496749854382,
'avg_failure_streak': 0.0,
'avg_kurtosis': 0.25686846515261513,
'avg_frequency': 0.1669826612570952}
Alright, this looks like it might be a reasonable representation for a summary of expected behavior for a test. What can this tell us?
For the test “operator.All images are built and tagged into stable” we should expect this test to pass about 91% percent of the time regardless of the platform its run on. We have a small negative slope (avg_coef), which means on average we have more “not run” instances as we move forward in time, but this is such a small slope its practically flat, i.e., this is a reliable test. If it does fail, there is 0% average failure streak, meaning if it does fail, it could fail for up to 0% of the total number of tests runs to date in a row (i.e, this test never fails, seems to only pass or not run). This value basically tells us how often we see small flips vs longer outages in our data. Finally, kurtosis and frequency are two additional measures of “steadiness” of our data, but since they are normalized here their interpretation is less direct, but can be understood in relation to other test vectors.
Now, is it useful to represent tests this way? Maybe. Its not fully clear at this point. My concern here would be that we have over-summarized the different dynamics occurring in these individual test runs. Especially, as we saw about 4 clear clusters for this test above. However, we can validate the usefulness of these baselines by repeating the above for all the tests and seeing if there is stronger inter-test relationship than between different tests. (Basically, will the individual tests land closer to the baseline for their test on average or not if we measure their vector distances?)
Lets find out and produce these vectors for each test, and compare them similarly to how we did above.
def get_timeseries_for_test(x, target_test):
collected_target_tests = []
timestamps = []
for i in x.keys():
for j in x[i].keys():
grid = x[i][j]["grid"]
if len(grid) == 0:
continue
if target_test in [x["name"] for x in grid]:
test_data = [x["statuses"] for x in grid if x["name"] == target_test]
collected_target_tests.append(test_data)
timestamps.append(x[i][j]["timestamps"])
ts_data = pd.DataFrame(
zip(collected_target_tests, timestamps), columns=["values", "time"]
)
# use the decode_run_length function imported from TestGrid_EDA notebook
ts_data["values"] = ts_data["values"].apply(lambda x: x[0]).apply(decode_run_length)
ts_data["time"] = ts_data["time"].apply(lambda x: (np.array(x) // 1000))
ts_data["time"] = ts_data["time"].apply(
lambda x: [datetime.datetime.fromtimestamp(y) for y in x]
)
return ts_data
vector_set = {}
test_names = list(set(all_tests))
for test in test_names:
test_set = get_timeseries_for_test(data, test)
vector = get_test_behavior(test_set["values"])
vector_set[test] = vector
vector_set[test_names[0]]
{'pass_rate': 0.4001886802824165,
'avg_coef': 0.005342678117091565,
'avg_intercept': 7.116541139292677,
'avg_failure_streak': 0.33080526429387325,
'avg_kurtosis': 0.05301396234931552,
'avg_frequency': 0.13468357069313408}
transpo = pd.DataFrame(vector_set).T
Now that we have our data converted from individual time series into one data point for each test with 6 features representing the average behavior of a test across all of its instances. Lets visualize it and get a sense for the distribution. To plot this 6d data in 2d we will again use PCA to reduce the dimensions.
X = transpo
ipca = IncrementalPCA(n_components=2, batch_size=20)
ipca.fit(X)
two_d = ipca.transform(X)
plt.scatter(two_d[:, 0], two_d[:, 1])
plt.title("PCA - Tests")
plt.show()
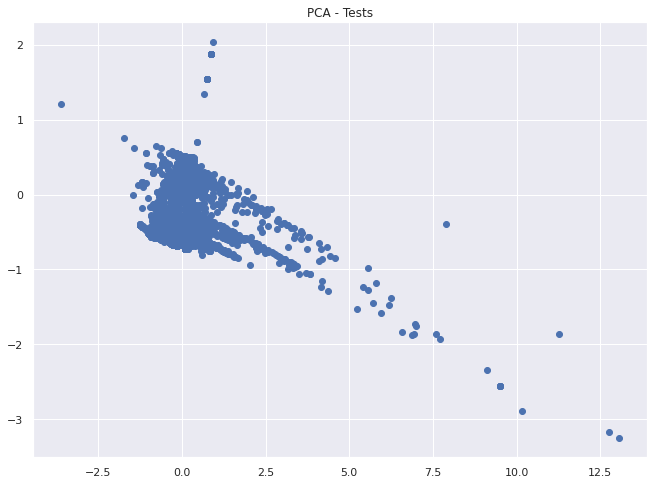
Clearly we can see some differentiation in this representation. Let’s use DBSCAN on the 6d data and see if there is still some meaningful grouping.
X = transpo
cluster = DBSCAN().fit(X)
fig, ax = plt.subplots()
scatter = ax.scatter(two_d[:, 0], two_d[:, 1], c=cluster.labels_)
legend1 = ax.legend(*scatter.legend_elements(), loc="lower left", title="Classes")
plt.title("DBSCAN - Tests")
plt.show()
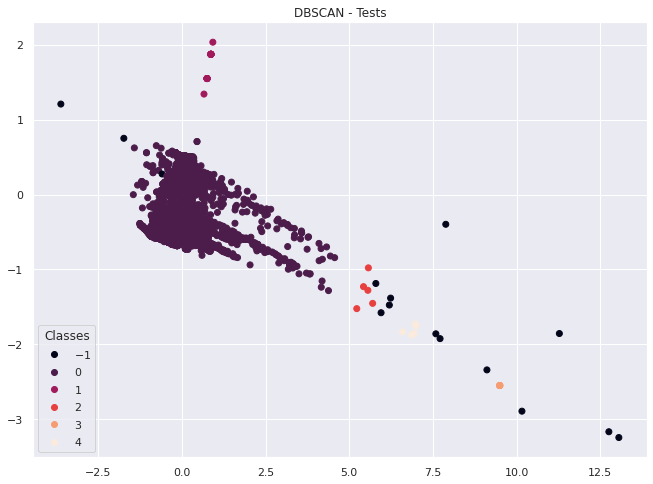
We can see some clustering going on in the plot above, but also a fairly even distribution between tests.
However, what we want to know is if these “baseline” vectors for each test are actually meaningful. We will make that assessment by determining if individual tests are closer to their “baselines” on average than the datasets overall average.
indivudial_metric = pd.DataFrame(
get_test_individual_behavior(ts_data["values"]),
columns=[
"pass_rate",
"slope",
"intercept",
"failures_streak",
"kurtosis",
"frequency",
],
)
# This is the center of our baselines.
tests_baseline = pd.DataFrame(vector_set).mean(axis=1)
tests_baseline
pass_rate 0.436850
avg_coef -0.001499
avg_intercept 0.730979
avg_failure_streak 0.006771
avg_kurtosis 0.351694
avg_frequency 0.184582
dtype: float64
# for each test, get the averge distance of their test instances from their baseline and the global baseline
results = []
for i in test_names:
indivudial_metric = get_timeseries_by_name(data, i)
indivudial_metric = pd.DataFrame(
get_test_individual_behavior(indivudial_metric["values"]),
columns=[
"pass_rate",
"slope",
"intercept",
"failures_streak",
"kurtosis",
"frequency",
],
)
baseline = pd.Series(vector_set[i])
group_baseline_distance = indivudial_metric.apply(
lambda x: np.linalg.norm(x.values - baseline.values), axis=1
).mean()
absolute_basline_distance = indivudial_metric.apply(
lambda x: np.linalg.norm(x.values - tests_baseline.values), axis=1
).mean()
results.append((i, group_baseline_distance, absolute_basline_distance))
local_vs_global = pd.DataFrame(
results,
columns=["test", "local average distance", "global average distance"],
)
local_vs_global.head()
| test | local average distance | global average distance | |
|---|---|---|---|
| 0 | Overall | 4.136537 | 6.522205 |
| 1 | [sig-api-machinery] ResourceQuota should creat... | 0.487039 | 0.671237 |
| 2 | [sig-network] NetworkPolicy NetworkPolicy betw... | 0.457299 | 0.569890 |
| 3 | [sig-storage] In-tree Volumes [Driver: gcepd] ... | 0.283472 | 0.587822 |
| 4 | [Suite: service-definition] [OSD] NodeLabels M... | 0.341153 | 0.856538 |
sum(
local_vs_global["local average distance"]
<= local_vs_global["global average distance"]
) / len(local_vs_global)
0.9842267248012311
Great, so in 98% of cases the local average distance of individual tests to their baseline is closer than an overall baseline. This tells us that there is some usefulness in describing the expected behavior of a test based on the mean of its individual features.
What have we accomplished up to now?
So far we have looked at the girds as a whole based on their shared collection of tests, determined that that the grids themselves are all unique and not directly comparable with regard to their set of tests.
However, some tests are repeated across many grids and we showed a couple methods to visualize, encode and analyze them both individually and in aggregate.
3. How does the entire test platform (or a specific test) perform on a given day?#
Now that we’ve looked at encoding and comparing tests from a “horizontal perspective” with regard to the grids and examined the tests independent of time. Lets switch to a “vertical perspective” and determine how the entire platform, specific grids, or particular tests behave at specific days and across time.
3.a) Platform performance for a given day#
In order to iterate over and search by the epoch time in our dataset, lets quickly collect all the unique times where a test value was logged.
times = []
for i in data.keys():
for j in data[i].keys():
times.extend(data[i][j]["timestamps"])
times = set(times)
times = sorted(list(times))
date = set([datetime.datetime.fromtimestamp(x // 1000) for x in times])
date = list(date)
times should contain every possible time stamp in our dataset.
Now let’s iterate through our dataset and collect all the data on our platform that occurred on our query date.
tests_on_day = []
query_date = datetime.date.fromtimestamp(1601671083)
for i in data.keys():
for j in data[i].keys():
for t in data[i][j]["timestamps"]:
if datetime.date.fromtimestamp(t // 1000) == query_date:
index = data[i][j]["timestamps"].index(t)
v = {}
for k in data[i][j]["grid"]:
# use the decode_run_length function imported from TestGrid_EDA notebook
value = decode_run_length(k["statuses"])[index]
name = k["name"]
v[name] = value
tests_on_day.append((i, j, t, v))
one_day_behaviour = pd.DataFrame(
tests_on_day, columns=["tab", "grid", "timestamp", "tests_values"]
)
one_day_behaviour.head(2)
| tab | grid | timestamp | tests_values | |
|---|---|---|---|---|
| 0 | "redhat-openshift-informing" | release-openshift-okd-installer-e2e-aws-upgrade | 1601677764000 | {'Application behind service load balancer wit... |
| 1 | "redhat-openshift-informing" | release-openshift-okd-installer-e2e-aws-upgrade | 1601676485000 | {'Application behind service load balancer wit... |
one_day_behaviour["passes"] = one_day_behaviour.tests_values.apply(
lambda x: sum([y for y in x.values() if y == 1])
)
one_day_behaviour["length"] = one_day_behaviour.tests_values.apply(
lambda x: len(x.values())
)
one_day_behaviour.head(2)
| tab | grid | timestamp | tests_values | passes | length | |
|---|---|---|---|---|---|---|
| 0 | "redhat-openshift-informing" | release-openshift-okd-installer-e2e-aws-upgrade | 1601677764000 | {'Application behind service load balancer wit... | 8 | 77 |
| 1 | "redhat-openshift-informing" | release-openshift-okd-installer-e2e-aws-upgrade | 1601676485000 | {'Application behind service load balancer wit... | 23 | 77 |
platfrom_pass_rate = one_day_behaviour.passes.sum() / one_day_behaviour.length.sum()
platfrom_pass_rate
0.6142468337152454
Great, so we can use this method to calculate the pass rate, or any other derived value, for the entire platform for a specific day. As we can see above, there was a 60% pass rate across the entire platform on our query day.
We could also use this approach on a subset of the data to get behavior metrics for specific tests, grids, or custom subsets.
Now that we know how to look at behavior for a single day across the entire platform, we could roll this out across each day to see how the platform evolves over time.
3.b) Platform performance over time#
Lets create a list of dates that we are interested in reviewing and plot the platform pass rate.
dates = [datetime.date(2020, 9, i) for i in range(1, 25)]
platform_pass_rate = []
for d in dates:
tests_on_day = []
query_date = d
for i in data.keys():
for j in data[i].keys():
for t in data[i][j]["timestamps"]:
if datetime.date.fromtimestamp(t // 1000) == query_date:
index = data[i][j]["timestamps"].index(t)
v = {}
for k in data[i][j]["grid"]:
# use the decode_run_length function imported from TestGrid_EDA notebook
value = decode_run_length(k["statuses"])[index]
name = k["name"]
v[name] = value
tests_on_day.append((i, j, t, v))
one_day_behaviour = pd.DataFrame(
tests_on_day, columns=["tab", "grid", "timestamp", "tests_values"]
)
one_day_behaviour["passes"] = one_day_behaviour.tests_values.apply(
lambda x: sum([y for y in x.values() if y == 1])
)
one_day_behaviour["length"] = one_day_behaviour.tests_values.apply(
lambda x: len(x.values())
)
platfrom_pass_rate_one_day = (
one_day_behaviour.passes.sum() / one_day_behaviour.length.sum()
)
platform_pass_rate.append(platfrom_pass_rate_one_day)
plt.plot(dates, platform_pass_rate)
plt.title("platfrom pass rate")
plt.ylabel("pass rate (%)")
plt.xlabel("date")
plt.show()
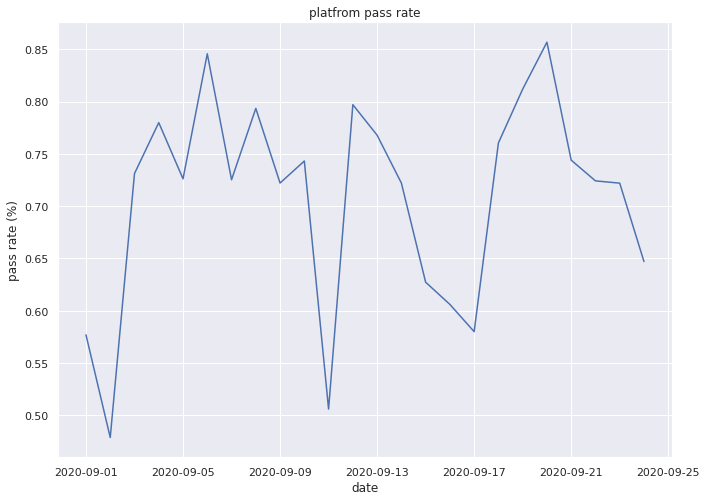
Great, from the above, we can now select any time period of interest (that we have data for) and examine the behavior of the entire platform over time.
And just to do our due diligence, below we will show that this can be done for individual test as well.
3.c) Aggregate single test performance over time#
test_name = "operator.All images are built and tagged into stable"
ts = get_timeseries_by_name(data, test_name)
ts.head()
| values | time | |
|---|---|---|
| 0 | [0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, ... | [2020-10-08 20:48:05, 2020-10-08 19:12:01, 202... |
| 1 | [0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, ... | [2020-10-08 20:52:49, 2020-10-08 20:52:45, 202... |
| 2 | [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | [2020-10-08 20:15:59, 2020-10-08 18:38:28, 202... |
| 3 | [1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1] | [2020-10-08 04:21:00, 2020-10-07 04:20:17, 202... |
| 4 | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [2020-10-07 22:04:59, 2020-10-06 22:04:21, 202... |
# epoch time is too specific, we only care about the day a test was run.
simple_dates = ts.time.apply(
lambda x: [datetime.date(y.year, y.month, y.day) for y in x]
)
ts["time"] = simple_dates
ts.head()
| values | time | |
|---|---|---|
| 0 | [0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, ... | [2020-10-08, 2020-10-08, 2020-10-08, 2020-10-0... |
| 1 | [0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, ... | [2020-10-08, 2020-10-08, 2020-10-08, 2020-10-0... |
| 2 | [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | [2020-10-08, 2020-10-08, 2020-10-08, 2020-10-0... |
| 3 | [1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1] | [2020-10-08, 2020-10-07, 2020-10-06, 2020-10-0... |
| 4 | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [2020-10-07, 2020-10-06, 2020-10-05, 2020-10-0... |
results = {}
for t in dates:
result = []
for i in range(len(ts)):
if t in ts.loc[i, "time"]:
RL_spot = ts.loc[i, "time"].index(t)
result.append(ts.loc[i, "values"][RL_spot])
results[t] = result
pass_rate = []
date = []
count = []
for k in results.keys():
date.append(k)
pass_rate.append(sum(results[k]) / len(results[k]))
count.append(len(results[k]))
fig, ax1 = plt.subplots()
color = "tab:red"
ax1.set_xlabel("time (d)", fontdict={"fontsize": 10})
ax1.set_ylabel("pass rate", color=color)
ax1.plot(date, pass_rate, color=color)
ax1.tick_params(axis="y", labelcolor=color, labelsize=10)
ax1.tick_params(axis="x", labelsize=10)
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
color = "tab:blue"
ax2.set_ylabel("count", color=color) # we already handled the x-label with ax1
ax2.plot(date, count, color=color)
ax2.tick_params(axis="y", labelcolor=color, labelsize=10)
plt.title(
'Pass Rate and Count: "operator.All images are built and tagged into stable"',
fontdict={"fontsize": 10},
)
fig.tight_layout() # otherwise the right y-label is slightly clipped
plt.show()
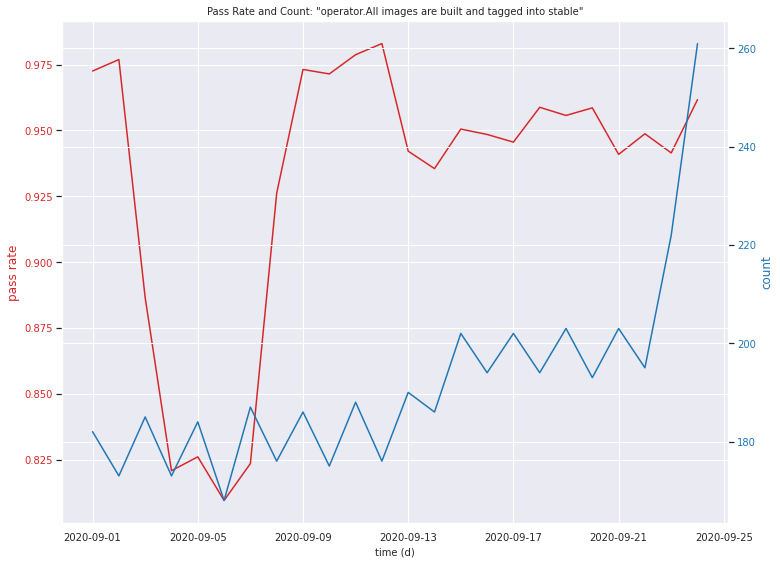
What have we accomplished?
Above we have explored a couple of methods for visualizing and calculating metrics about the TestGrid environment given a specific time or time range. Moving forward this could be used for overall trend analysis or prediction or root cause analysis for a time period with a known issue.
4. Grid matrices as 2d signals#
Is looking at the grid matrices independent of test names a valid approach for issue identification?
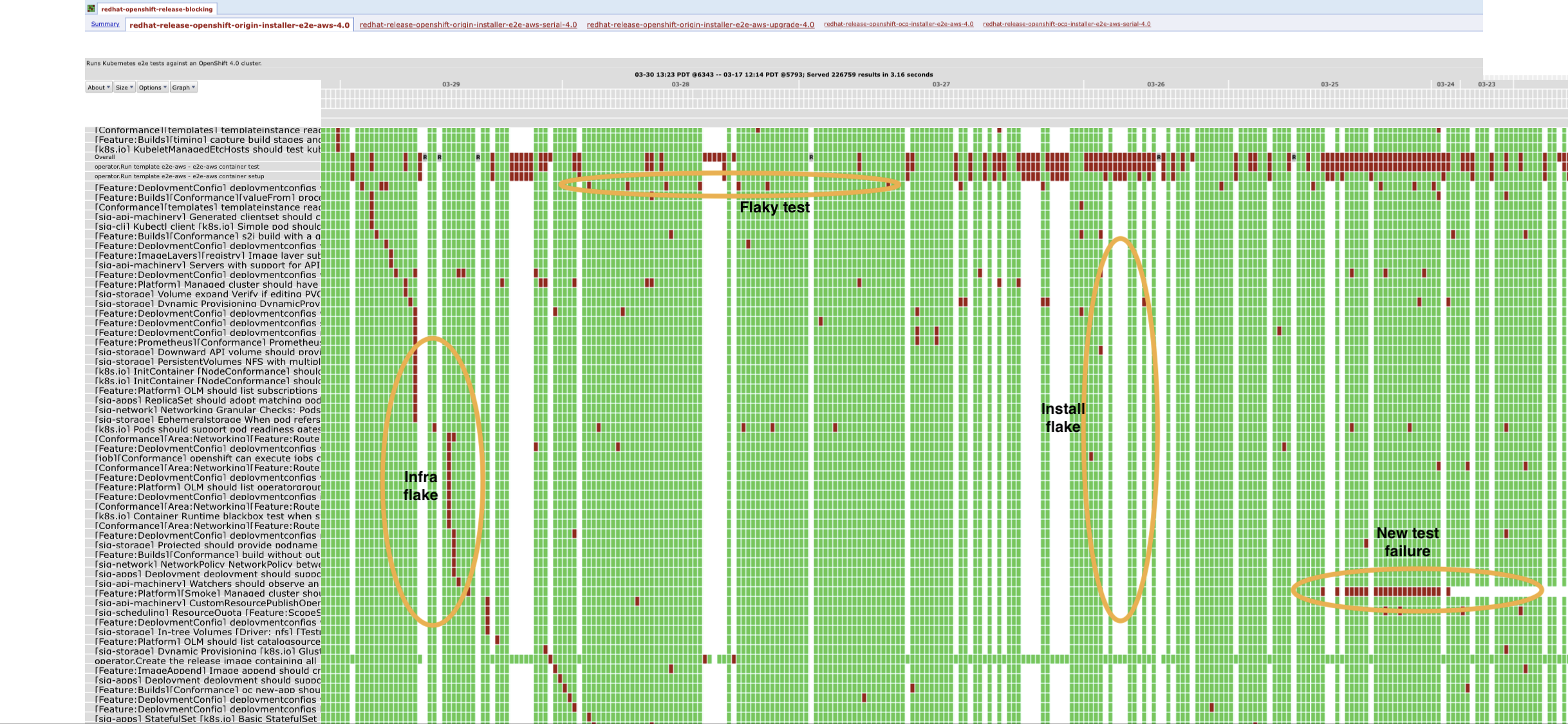
I don’t see why not. Let’s take an example: Looking at the image below we can see that it was annotated manually by a human subject matter expert. Most of these errors seem to lie either purely on the vertical or horizontal axes and can be identified by analyzing either a single test or a single day, which we’ve already explored above. Let’s look for an issue that is signaled by behavior across both days and tests.
4.a) Identify Infrastructure Flakes#
What about the infrastructure flake case? That seems to be characterized by diagonal test failures over multiple days. We currently do not have any way of addressing that type of data. Lets see if we can use a simple hand crafted 2d filter to start identifying these types of errors.
Image(
"https://user-images.githubusercontent.com/161888/89903201-a62b3800-dbe7-11ea-9b1c-2ec62fe8952f.png"
)
# 2d filter that will have its highest value when convolved with a diagonal pattern.
infra_flake_filter = np.array([[-1, 1], [1, -1]])
infra_flake_filter
array([[-1, 1],
[ 1, -1]])
# get data for example grid
grid = data['"redhat-openshift-ocp-release-4.3-informing"'][
"release-openshift-origin-installer-e2e-gcp-compact-4.3"
]["grid"]
# Subset of the data where we see this infra flake pattern
# use the decode_run_length function imported from TestGrid_EDA notebook
grid = np.array(list(pd.DataFrame(grid).statuses.apply(decode_run_length)))
grid = grid[0:21, 0:21]
# we want to re-map the values so that the output of the convolution will be more interpretable.
def normalize(x):
if x == 1:
return 1
if x == 12:
return -1
if x == 0:
return 0
x = pd.DataFrame(grid).apply(lambda x: [normalize(y) for y in x])
x = np.array(x)
plt.imshow(x, cmap="bone")
plt.title("Test Grid: release-openshift-origin-installer-e2e-gcp-compact-4.3")
plt.show()
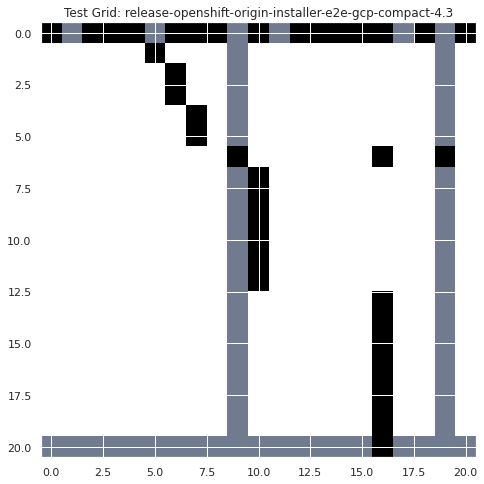
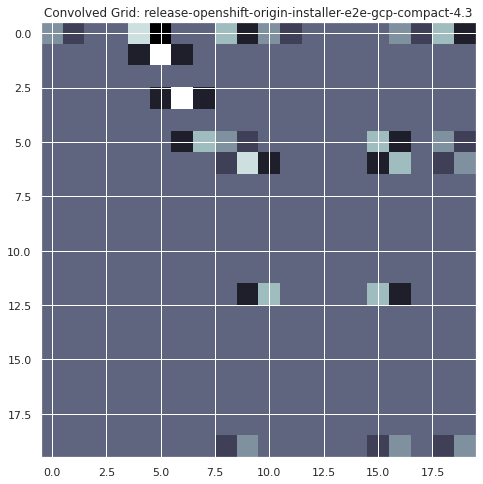
plt.imshow(convolve2d(infra_flake_filter, x, mode="valid"), cmap="bone")
plt.title("Convolved Grid: release-openshift-origin-installer-e2e-gcp-compact-4.3")
plt.show()
# Find the spots on the map where the convolution had its maximum value.
spots = convolve2d(infra_flake_filter, x, mode="valid")
infra_falkes = np.where(spots == 4)
infra_falkes
(array([1, 3]), array([5, 6]))
dates = data['"redhat-openshift-ocp-release-4.3-informing"'][
"release-openshift-origin-installer-e2e-gcp-compact-4.3"
]["timestamps"]
infra_flake_dates = np.array(dates)[list([infra_falkes][0][1])]
for i in infra_flake_dates:
print(f"possible infra flake occuring on {datetime.date.fromtimestamp(i//1000)}")
possible infra flake occuring on 2020-10-02
possible infra flake occuring on 2020-10-01
What have we accomplished?
The above example has shown one way to automatically determined if there was an infrastructure flake in our TestGrid (assuming they can be identified following this diagonal failure pattern rule). This example identified 2 such flakes between October 1st and 2nd for the “release-openshift-origin-installer-e2e-gcp-compact-4.3’” grid. Moving forward we should follow up with an SME to validate these results and refine this approach.
Conclusion#
In this notebook, we have done some additional exploration of the TestGrid data; familiarized ourselves with it further and determined a number of facts about the nature of the grids that will help us move forward developing additional analysis and ML tools for CI. We have looked at the entire TestGrid platform, individual grids and individual tests both from a stationary and time-series perspective. We have also done a couple of small experiments with encoding and clustering to explore the dataset’s viability for applying ML approaches.
In this notebook we have tried to address the following questions and come up with the following answers:
How comparable are the TestGrids?
The test grids contain nearly unique sets of tests and therefore are not directly comparable. We will either have to consider the aggregation of shared test or define grids purely by their patterns (independent of specific test)
How do we analyze the TestGrids in aggregate to learn from their combined behavior?
I don’t think we can analyze the entire grids directly due to the above stated issue of uniqueness, other than addressing purely the patterns independent of the specific test names. It will likely be better to analyze the data one step lower and learn from the tests, then use the tests the grids are composed of to understand the grids better.
How many/ which tests do they all have in common?
The set of tests in each grid appears to be unique and there is not one test that is included in all grids.
However, there are about 3k tests identified above that that occur in 10 grids or more.
Are their time series dates comparable?
We have included the timestamps for the time series, so we know when a test passed/failed and we can compare tests on specific days or time ranges.
Each grid contains different dates and lengths of runs, however, so they aren’t all equally sampled points.
Are there sub-groups that should only be compared with one another?
We removed version identifiers to compare subgroups, but still saw little overall overlap between sets of tests in grids appeared. But further analysis could still be done in this regard.
Is looking at the grid matrices independent of test names a valid approach for issue identification?
We were able to create a toy example using a 2d convolution and an handcrafted filter to identify diagonal failures in the TestGrids. If the annotated image we have is accurate, then we have shown at least one method to achieve this goal. So I would consider this to indeed be a useful approach.
What is the expected behavior of a test over time across multiple jobs.
We developed some basic encoding and clustering examples to compare individual tests, aggregated tests and tests of the same type. We should build this analysis out further in a later notebook.
How does the entire test platform/specific tests perform on a given day?
We were able to develop a number of methods to perform and display this type of analysis. We should build this analysis out further in a later notebook.
How does a test or the entire test platform behavior evolve over time.
Given the above step, we were able to roll that analysis out across time and plot trends in platform pass rate over September. We should build this analysis out further in a later notebook.
Is there sufficient data here for useful ML approaches?
Yes, especially if we focus on the level of individual time-series for tests. However, there are currently not clear labels, so much of the initial work would either be unsupervised learning or pure statistical analysis.
If we look only at the Red Hat grids, which are themselves a subset of the entire ecosystem.
There are ~400 grids
61 days of data for each grid
117,000 time series
Other platforms have also opened their data on Testgrid.io that we could leverage as well.
Can we develop some meaningful alerting/ problem identification with the results of the above questions?
Yes. Given all of the above, I think there are a number of avenues available for developing altering and classification tools for CI based on this data.