Telemetry Data for CI Clusters
Contents
Telemetry Data for CI Clusters#
Every cluster running an OpenShift CI job sends some operational data back to Red Hat via Telemetry. This data gets stored as Prometheus metrics in a Thanos deployment at Red Hat. Some examples of the prometheus metrics collected here include CPU and memory capacity, operators installed, alerts fired, provider platform, etc. Thus, in addition to high level test run data on testgrid and prow, we also have detailed time series data available for the CI clusters that ran the tests.
In this notebook, we will show how to access this telemetry data using some open source tools developed by the AIOps team. Specifically we will show that, given a specific CI job run, how to get the telemetry data associated with the cluster that ran it. In addition, we will show how to get the pass/fail status of a given build of a job, from a given point in time. Then we will compare the telemetry metrics of a passing build with those of failing build within the same job, and see if we can get insights into the build failure.
NOTE: Since this data is currently hosted on a Red Hat internal Thanos, only those users with access to it will be able to run this notebook to get “live” data. To ensure that the wider open source community is also able to use this data for further analysis, we will use this notebook to extract a snippet of this data and save it on our public GitHub repo.
# import all the required libraries
import os
import warnings
import datetime as dt
from tqdm.notebook import tqdm
from dotenv import load_dotenv, find_dotenv
from urllib3.exceptions import InsecureRequestWarning
import requests
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from prometheus_api_client import (
PrometheusConnect,
MetricSnapshotDataFrame,
MetricRangeDataFrame,
)
import sys
sys.path.insert(1, "../TestGrid/metrics")
from ipynb.fs.defs.metric_template import save_to_disk # noqa: E402
load_dotenv(find_dotenv())
True
# config for a pretty notebook
sns.set()
load_dotenv(find_dotenv())
warnings.filterwarnings("ignore", category=InsecureRequestWarning)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
Data Access Setup#
In this section, we will configure the prometheus-api-client-python tool to pull data from our Thanos instance. That is, set the value of PROM_URL to the Thanos endpoint, and set the value of PROM_ACCESS_TOKEN to the bearer token for authentication. We will also set the timestamp from which telemetry data is to be pulled.
In order to get access to the token, you can follow either one of these steps:
Visit
https://datahub.psi.redhat.com/. Click on your profile (top right) and select Copy Login Command from the drop down menu. This will copy a command that will look something like:oc login https://datahub.psi.redhat.com:443 --token=<YOUR_TOKEN>. The value in YOUR_TOKEN is the required token.From the command line, run
oc whoami --show-token. Ensure that the output ofoc projectishttps://datahub.psi.redhat.com/. This will output the required token.
NOTE: The above methods can only used if you are on Red Hat VPN.
# prometheus from which metrics are to be fetched
PROM_URL = os.getenv("PROM_URL")
PROM_ACCESS_TOKEN = os.getenv("PROM_ACCESS_TOKEN")
# prometheus connector object
pc = PrometheusConnect(
url=PROM_URL,
disable_ssl=True,
headers={"Authorization": f"bearer {PROM_ACCESS_TOKEN}"},
)
# which metrics to fetch
# we will try to get all metrics, but leave out ones that may have potentially sensitive data
metrics_to_fetch = [
m
for m in pc.all_metrics()
if "subscription" not in m and "internal" not in m and "url" not in m
]
# these fields are either irrelevant or contain something that could potentially be sensitive
# either way, these likely wont be useful for analysis anyway so exclude them when reading data
drop_cols = [
"prometheus",
"tenant_id",
"endpoint",
"instance",
"receive",
"url",
]
Get All Data for Job Build#
In this section, we will get all the prometheus metrics corresponding to a given job name, build id and fixed date. If you want to extract the information for another job name and build id, please ensure that Thanos actually contains the data for this job/build at the corresponding timestamp at which you’re evaluating the query. The job name and build id can be obtained either directly from the testgrid UI, or from the query and changelists fields respectively in the testgrid json as shown in the testgrid metadata EDA notebook.
One of the metrics stored in Thanos is cluster_installer. This metric describes what entity triggered the install of each cluster. For the clusters that run OpenShift CI jobs, the invoker label value in this metric is set to openshift-internal-ci/{job_name}/{build_id}.
Therefore, we can get all data for a given job build by first finding the ID of the cluster that ran it (using cluster_installer), and then querying prometheus for metrics where the _id label value equals this cluster ID. These steps are demonstrated through the example below. We will be choosing two jobs and build_id and later to compare their telemetry metric values.
# timestamp for which prometheus queries will be evaluated
query_eval_time = dt.datetime(
year=2022, month=1, day=18, hour=21, minute=53, second=51, tzinfo=dt.timezone.utc
)
query_eval_ts = query_eval_time.timestamp()
1642542831.0
# example job and build
job_name = "periodic-ci-openshift-release-master-nightly-4.10-e2e-aws-upgrade"
build_id_1 = "1483543721860403200"
build_id_2 = "1483543720656637952"
# get installer info for the job/build
job_build_cluster_installer1 = pc.custom_query(
query=f'cluster_installer{{invoker="openshift-internal-ci/{job_name}/{build_id_1}"}}',
params={"time": query_eval_ts},
)
job_build_cluster_installer2 = pc.custom_query(
query=f'cluster_installer{{invoker="openshift-internal-ci/{job_name}/{build_id_2}"}}',
params={"time": query_eval_ts},
)
# extract cluster id out of the installer info metric
cluster_id1 = job_build_cluster_installer1[0]["metric"]["_id"]
cluster_id2 = job_build_cluster_installer2[0]["metric"]["_id"]
Overall Status#
We are able to to get the status of past builds from the historical testgrid data that we are collecting. That is how we are calculating build pass/fail metrics over time. However, I am not sure if we are able to get the build_id from the Testgrid data. Hence, it makes more sense to get it from the prow logs. The overall status (pass/fail) of the past job and build id can be found in finished.json file in build log data (example link).
Here we are checking the status of the two job using prow log.
prow_log1 = requests.get(
f"https://gcsweb-ci.apps.ci.l2s4.p1.openshiftapps.com"
f"/gcs/origin-ci-test/logs/{job_name}/{build_id_1}/finished.json"
)
prow_log2 = requests.get(
f"https://gcsweb-ci.apps.ci.l2s4.p1.openshiftapps.com"
f"/gcs/origin-ci-test/logs/{job_name}/{build_id_2}/finished.json"
)
status1 = prow_log1.json()["result"]
status2 = prow_log2.json()["result"]
print(
f"The status of the first build is {status1}"
f" and the status of second build is {status2}."
)
The status of the first build is SUCCESS and the status of second build is FAILURE.
In the next step, we will calculate the metrics for the two builds.
Get One Metric#
Before we fetch all the metrics, let’s fetch just one metric and familiarize ourselves with the data format, and understand how to interpret it. In the cell below, we will look at an example metric, cluster:cpu_capacity:sum.
# fetch the metric and format it into a df
metric_df1 = MetricSnapshotDataFrame(
pc.custom_query(
query=f'cluster:capacity_cpu_cores:sum{{_id="{cluster_id1}"}}',
params={"time": query_eval_ts},
)
)
metric_df2 = MetricSnapshotDataFrame(
pc.custom_query(
query=f'cluster:capacity_cpu_cores:sum{{_id="{cluster_id2}"}}',
params={"time": query_eval_ts},
)
)
metric_df1.drop(columns=drop_cols, errors="ignore", inplace=True)
metric_df2.drop(columns=drop_cols, errors="ignore", inplace=True)
Metric for SUCCESS job#
metric_df1
| __name__ | _id | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | timestamp | value | label_node_role_kubernetes_io | |
|---|---|---|---|---|---|---|---|---|
| 0 | cluster:capacity_cpu_cores:sum | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | m5.xlarge | amd64 | rhcos | 1642542831 | 12 | NaN |
| 1 | cluster:capacity_cpu_cores:sum | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | m6i.xlarge | amd64 | rhcos | 1642542831 | 12 | master |
Metric for FAILED job#
metric_df2
| __name__ | _id | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | timestamp | value | label_node_role_kubernetes_io | |
|---|---|---|---|---|---|---|---|---|
| 0 | cluster:capacity_cpu_cores:sum | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | m5.xlarge | amd64 | rhcos | 1642542831 | 12 | NaN |
| 1 | cluster:capacity_cpu_cores:sum | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | m6i.xlarge | amd64 | rhcos | 1642542831 | 12 | master |
HOW TO READ THIS DATAFRAME
In the above dataframe, each column represents a “label” of the prometheus metric, and each row represents a different “label configuration”. In this example, the first row has label_node_role_kubernetes_io = NaN and value = 12, and the second row has label_node_role_kubernetes_io = master and value = 12. This means that in this cluster, the master node had 12 CPU cores, and the worker node also had 12 CPU cores.
To learn more about labels, label configurations, and the prometheus data model in general, please check out their official documentation here.
Observing the above metrics value, we see that the value is 12 cores for both SUCCESS and FAILED build.
Get All Metrics#
Now that we understand the data structure of the metrics, let’s fetch all the metrics and concatenate them into one single dataframe.
Metrics for testgrid SUCCESSFUL build#
# let's combine all the metrics into one dataframe
# for the above mentioned job name and build name.
all_metrics_df = pd.DataFrame()
for metric in metrics_to_fetch:
metric_df = MetricSnapshotDataFrame(
pc.custom_query(
query=f'{metric}{{_id="{cluster_id1}"}}',
params={"time": query_eval_ts},
)
)
if len(metric_df) > 0:
metric_df.drop(columns=drop_cols, errors="ignore", inplace=True)
# print(f"Metric = {metric}")
# display(metric_df.head())
all_metrics_df = pd.concat(
[
all_metrics_df,
metric_df,
],
axis=0,
join="outer",
ignore_index=True,
)
all_metrics_df.head(5)
| __name__ | _id | alertname | alertstate | namespace | severity | timestamp | value | container | job | mode | pod | service | apiserver | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | label_node_role_kubernetes_io | plugin_name | volume_mode | provisioner | networks | resource | type | region | invoker | version | condition | name | reason | from_version | image | code | metrics_path | exported_namespace | install_type | network_type | host_type | provider | client | status_code | quantile | exported_service | label_node_hyperthread_enabled | label_node_role_kubernetes_io_master | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alerts | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | AlertmanagerReceiversNotConfigured | firing | openshift-monitoring | warning | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | alerts | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | Watchdog | firing | openshift-monitoring | none | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | cco_credentials_mode | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | openshift-cloud-credential-operator | NaN | 1642542831 | 1 | kube-rbac-proxy | cco-metrics | mint | cloud-credential-operator-784f994fff-lsxz8 | cco-metrics | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | cluster:alertmanager_integrations:max | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | NaN | NaN | 1642542831 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | cluster:apiserver_current_inflight_requests:su... | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | NaN | NaN | 1642542831 | 10 | NaN | NaN | NaN | NaN | NaN | kube-apiserver | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# concatenate into one dataframe
all_metricsdf1 = all_metrics_df.drop_duplicates()
all_metricsdf1.head()
| __name__ | _id | alertname | alertstate | namespace | severity | timestamp | value | container | job | mode | pod | service | apiserver | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | label_node_role_kubernetes_io | plugin_name | volume_mode | provisioner | networks | resource | type | region | invoker | version | condition | name | reason | from_version | image | code | metrics_path | exported_namespace | install_type | network_type | host_type | provider | client | status_code | quantile | exported_service | label_node_hyperthread_enabled | label_node_role_kubernetes_io_master | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alerts | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | AlertmanagerReceiversNotConfigured | firing | openshift-monitoring | warning | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | alerts | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | Watchdog | firing | openshift-monitoring | none | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | cco_credentials_mode | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | openshift-cloud-credential-operator | NaN | 1642542831 | 1 | kube-rbac-proxy | cco-metrics | mint | cloud-credential-operator-784f994fff-lsxz8 | cco-metrics | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | cluster:alertmanager_integrations:max | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | NaN | NaN | 1642542831 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | cluster:apiserver_current_inflight_requests:su... | 59a54b9c-d0fd-4b1a-b119-c24fb08fa03c | NaN | NaN | NaN | NaN | 1642542831 | 10 | NaN | NaN | NaN | NaN | NaN | kube-apiserver | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Metrics for testgrid FAILURE build#
# let's combine all the metrics into one dataframe
# for the above mentioned job name and build name.
all_metrics_df = pd.DataFrame()
for metric in metrics_to_fetch:
metric_df = MetricSnapshotDataFrame(
pc.custom_query(
query=f'{metric}{{_id="{cluster_id2}"}}',
params={"time": query_eval_ts},
)
)
if len(metric_df) > 0:
metric_df.drop(columns=drop_cols, errors="ignore", inplace=True)
all_metrics_df = pd.concat(
[
all_metrics_df,
metric_df,
],
axis=0,
join="outer",
ignore_index=True,
)
all_metrics_df.head()
| __name__ | _id | alertname | alertstate | namespace | severity | timestamp | value | container | job | mode | pod | service | apiserver | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | label_node_role_kubernetes_io | plugin_name | volume_mode | provisioner | networks | resource | type | region | invoker | version | condition | name | reason | from_version | image | code | metrics_path | exported_namespace | install_type | network_type | host_type | provider | client | status_code | quantile | exported_service | label_node_hyperthread_enabled | label_node_role_kubernetes_io_master | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alerts | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | AlertmanagerReceiversNotConfigured | firing | openshift-monitoring | warning | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | alerts | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | Watchdog | firing | openshift-monitoring | none | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | cco_credentials_mode | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | openshift-cloud-credential-operator | NaN | 1642542831 | 1 | kube-rbac-proxy | cco-metrics | mint | cloud-credential-operator-784f994fff-559g2 | cco-metrics | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | cluster:alertmanager_integrations:max | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | NaN | NaN | 1642542831 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | cluster:apiserver_current_inflight_requests:su... | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | NaN | NaN | 1642542831 | 24 | NaN | NaN | NaN | NaN | NaN | kube-apiserver | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
all_metricsdf2 = all_metrics_df.drop_duplicates()
all_metricsdf2.head()
| __name__ | _id | alertname | alertstate | namespace | severity | timestamp | value | container | job | mode | pod | service | apiserver | label_beta_kubernetes_io_instance_type | label_kubernetes_io_arch | label_node_openshift_io_os_id | label_node_role_kubernetes_io | plugin_name | volume_mode | provisioner | networks | resource | type | region | invoker | version | condition | name | reason | from_version | image | code | metrics_path | exported_namespace | install_type | network_type | host_type | provider | client | status_code | quantile | exported_service | label_node_hyperthread_enabled | label_node_role_kubernetes_io_master | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | alerts | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | AlertmanagerReceiversNotConfigured | firing | openshift-monitoring | warning | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | alerts | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | Watchdog | firing | openshift-monitoring | none | 1642542831 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | cco_credentials_mode | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | openshift-cloud-credential-operator | NaN | 1642542831 | 1 | kube-rbac-proxy | cco-metrics | mint | cloud-credential-operator-784f994fff-559g2 | cco-metrics | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | cluster:alertmanager_integrations:max | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | NaN | NaN | 1642542831 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | cluster:apiserver_current_inflight_requests:su... | 026e1f8a-82af-4b42-8ed3-0f6af0d7ebea | NaN | NaN | NaN | NaN | 1642542831 | 24 | NaN | NaN | NaN | NaN | NaN | kube-apiserver | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
Comparing some metrics for the SUCCESSFUL and FAILED build#
# For SUCCESS build:
print(all_metricsdf1.__name__.nunique())
# For FAILED build:
print(all_metricsdf2.__name__.nunique())
print("The number of metrices extracted from the two builds are different.")
69
70
The number of metrices extracted from the two builds are different.
Furthermore, In the next steps, we merge the two datasets from the two builds and sort the merged dataframe with respect to the percentage difference in values of build metrics. Here, df1 corresponds to the dataframe for successful build type and df2 for failed build type.
Percentage Difference:#
df1 = all_metricsdf1[["__name__", "value"]].drop_duplicates()
df1["value"] = df1["value"].astype(float)
df1 = df1.groupby(["__name__"])["value"].sum().to_frame()
df2 = all_metricsdf2[["__name__", "value"]].drop_duplicates()
df2["value"] = df2["value"].astype(float)
df2 = df2.groupby(["__name__"])["value"].sum().to_frame()
df1.rename(columns={"value": "Success_build_value"}, inplace=True)
df2.rename(columns={"value": "Failure_build_value"}, inplace=True)
df1 = df1.reset_index()
df2 = df2.reset_index()
df_merge = pd.merge(df1, df2, on="__name__", how="outer")
df_merge["diff"] = abs(
((df_merge["Success_build_value"] - df_merge["Failure_build_value"]) * 100)
/ ((df_merge["Success_build_value"] + df_merge["Failure_build_value"]) / 2)
)
df_merge = df_merge[
["__name__", "Success_build_value", "Failure_build_value", "diff"]
].sort_values(by="diff", ascending=False)
df_merge
| __name__ | Success_build_value | Failure_build_value | diff | |
|---|---|---|---|---|
| 3 | cluster:apiserver_current_inflight_requests:su... | 1.300000e+01 | 2.900000e+01 | 76.190476 |
| 51 | instance:etcd_disk_backend_commit_duration_sec... | 2.132312e-02 | 1.381915e-02 | 42.706215 |
| 56 | instance:etcd_object_counts:sum | 2.470200e+04 | 3.762300e+04 | 41.463297 |
| 55 | instance:etcd_network_peer_round_trip_time_sec... | 3.778560e-02 | 2.521600e-02 | 39.902479 |
| 22 | cluster:usage:openshift:ingress_request_total:... | 3.400000e+00 | 4.466667e+00 | 27.118644 |
| 63 | openshift:cpu_usage_cores:sum | 2.572576e+00 | 3.335502e+00 | 25.826554 |
| 6 | cluster:cpu_usage_cores:sum | 2.574476e+00 | 3.337539e+00 | 25.813958 |
| 60 | namespace_job:scrape_series_added:topk3_sum1h | 2.363220e+05 | 3.037350e+05 | 24.965143 |
| 18 | cluster:usage:ingress_frontend_connections:sum | 1.900000e+01 | 2.300000e+01 | 19.047619 |
| 25 | cluster:usage:workload:capacity_physical_cpu_c... | 9.852000e+03 | 1.149000e+04 | 15.350014 |
| 52 | instance:etcd_disk_wal_fsync_duration_seconds:... | 1.431914e-02 | 1.244548e-02 | 14.001049 |
| 17 | cluster:usage:ingress_frontend_bytes_out:rate5... | 4.423026e+04 | 3.922549e+04 | 11.993840 |
| 64 | openshift:memory_usage_bytes:sum | 2.804829e+10 | 2.510586e+10 | 11.071283 |
| 10 | cluster:memory_usage_bytes:sum | 2.815404e+10 | 2.521127e+10 | 11.028780 |
| 9 | cluster:kubelet_volume_stats_used_bytes:provis... | 2.393539e+08 | 2.621563e+08 | 9.093508 |
| 67 | workload:cpu_usage_cores:sum | 1.900651e-03 | 2.036780e-03 | 6.914581 |
| 57 | monitoring:container_memory_working_set_bytes:sum | 5.172630e+09 | 5.499646e+09 | 6.128336 |
| 59 | namespace_job:scrape_samples_post_metric_relab... | 6.769200e+04 | 7.172500e+04 | 5.785521 |
| 15 | cluster:usage:containers:sum | 6.660000e+02 | 7.050000e+02 | 5.689278 |
| 16 | cluster:usage:ingress_frontend_bytes_in:rate5m... | 4.236015e+03 | 4.011374e+03 | 5.447560 |
| 41 | code:apiserver_request_total:rate:sum | 7.531959e+01 | 7.176856e+01 | 4.828425 |
| 54 | instance:etcd_mvcc_db_total_size_in_use_in_byt... | 2.299535e+08 | 2.410947e+08 | 4.730353 |
| 53 | instance:etcd_mvcc_db_total_size_in_bytes:sum | 2.746409e+08 | 2.620826e+08 | 4.679630 |
| 65 | openshift:prometheus_tsdb_head_samples_appende... | 1.770057e+04 | 1.695999e+04 | 4.273317 |
| 66 | openshift:prometheus_tsdb_head_series:sum | 7.357900e+05 | 7.655760e+05 | 3.967853 |
| 24 | cluster:usage:resources:sum | 1.218100e+04 | 1.261300e+04 | 3.484714 |
| 23 | cluster:usage:openshift:kube_running_pod_ready... | 9.950495e-01 | 1.000000e+00 | 0.496278 |
| 68 | workload:memory_usage_bytes:sum | 1.057546e+08 | 1.054065e+08 | 0.329758 |
| 14 | cluster:telemetry_selected_series:count | 5.050000e+02 | 5.040000e+02 | 0.198216 |
| 5 | cluster:capacity_memory_bytes:sum | 9.886904e+10 | 9.904518e+10 | 0.177992 |
| 39 | cluster_version | 6.570163e+09 | 6.570162e+09 | 0.000009 |
| 61 | node_role_os_version_machine:cpu_capacity_core... | 6.000000e+00 | 6.000000e+00 | 0.000000 |
| 45 | id_network_type | 7.000000e+00 | 7.000000e+00 | 0.000000 |
| 62 | node_role_os_version_machine:cpu_capacity_sock... | 3.000000e+00 | 3.000000e+00 | 0.000000 |
| 50 | insightsclient_request_send_total | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 49 | id_version:cluster_available | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 0 | alerts | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 43 | csv_succeeded | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 27 | cluster:usage:workload:capacity_physical_cpu_c... | 6.000000e+00 | 6.000000e+00 | 0.000000 |
| 4 | cluster:capacity_cpu_cores:sum | 1.200000e+01 | 1.200000e+01 | 0.000000 |
| 7 | cluster:kube_persistentvolume_plugin_type_coun... | 2.000000e+00 | 2.000000e+00 | 0.000000 |
| 8 | cluster:kube_persistentvolumeclaim_resource_re... | 2.147484e+10 | 2.147484e+10 | 0.000000 |
| 13 | cluster:node_instance_type_count:sum | 3.000000e+00 | 3.000000e+00 | 0.000000 |
| 19 | cluster:usage:kube_node_ready:avg5m | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 20 | cluster:usage:kube_schedulable_node_ready_reac... | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 26 | cluster:usage:workload:capacity_physical_cpu_c... | 6.000000e+00 | 6.000000e+00 | 0.000000 |
| 30 | cluster:usage:workload:kube_running_pod_ready:avg | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 42 | count:up1 | 1.200000e+01 | 1.200000e+01 | 0.000000 |
| 31 | cluster:virt_platform_nodes:sum | 6.000000e+00 | 6.000000e+00 | 0.000000 |
| 32 | cluster_feature_set | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 33 | cluster_infrastructure_provider | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 1 | cco_credentials_mode | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 37 | cluster_operator_conditions | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 38 | cluster_operator_up | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 40 | cluster_version_payload | 7.690000e+02 | 7.690000e+02 | 0.000000 |
| 34 | cluster_installer | 1.000000e+00 | 1.000000e+00 | 0.000000 |
| 2 | cluster:alertmanager_integrations:max | 0.000000e+00 | 0.000000e+00 | NaN |
| 11 | cluster:network_attachment_definition_enabled_... | 0.000000e+00 | 0.000000e+00 | NaN |
| 12 | cluster:network_attachment_definition_instance... | 0.000000e+00 | 0.000000e+00 | NaN |
| 21 | cluster:usage:openshift:ingress_request_error:... | 0.000000e+00 | 0.000000e+00 | NaN |
| 28 | cluster:usage:workload:ingress_request_error:f... | 0.000000e+00 | 0.000000e+00 | NaN |
| 29 | cluster:usage:workload:ingress_request_total:i... | 0.000000e+00 | 0.000000e+00 | NaN |
| 35 | cluster_legacy_scheduler_policy | 0.000000e+00 | 0.000000e+00 | NaN |
| 36 | cluster_master_schedulable | 0.000000e+00 | 0.000000e+00 | NaN |
| 44 | id_install_type | 0.000000e+00 | 0.000000e+00 | NaN |
| 46 | id_primary_host_type | 0.000000e+00 | 0.000000e+00 | NaN |
| 47 | id_provider | 0.000000e+00 | 0.000000e+00 | NaN |
| 48 | id_version | 0.000000e+00 | 0.000000e+00 | NaN |
| 58 | monitoring:haproxy_server_http_responses_total... | 0.000000e+00 | 0.000000e+00 | NaN |
| 69 | count:up0 | NaN | 1.000000e+00 | NaN |
In the next case, we are plotting some metrics values listed in the metric_list below. Using the plot we are able to compare the value for both successful and failed build types.
metric_list = df_merge.__name__.iloc[:5]
metric_list
3 cluster:apiserver_current_inflight_requests:su...
51 instance:etcd_disk_backend_commit_duration_sec...
56 instance:etcd_object_counts:sum
55 instance:etcd_network_peer_round_trip_time_sec...
22 cluster:usage:openshift:ingress_request_total:...
Name: __name__, dtype: object
filter_series1 = df_merge.__name__.isin(metric_list)
df_mergef = df_merge[filter_series1]
plt.figure(figsize=(20, 15))
plt.subplot(2, 1, 1)
plt.scatter(
df_mergef["__name__"],
df_mergef["Success_build_value"],
label="success build",
marker="s",
s=100,
)
plt.scatter(
df_mergef["__name__"],
df_mergef["Failure_build_value"],
label="failed build",
marker="o",
s=100,
)
plt.title("Metrics comparison for success and failed build")
plt.ylabel("metric value", fontsize=18)
plt.xticks([])
plt.yticks(fontsize=14)
plt.legend()
plt.subplot(2, 1, 2)
plt.scatter(
df_mergef["__name__"],
df_mergef["diff"],
label="Percentage Difference",
marker="o",
s=100,
)
plt.title("Difference in metric values")
plt.xlabel("metrics name", fontsize=18)
plt.ylabel("Percentage difference", fontsize=18)
plt.xticks(fontsize=14, rotation=45)
plt.yticks(fontsize=14)
plt.legend()
<matplotlib.legend.Legend at 0x7fef1ca51af0>
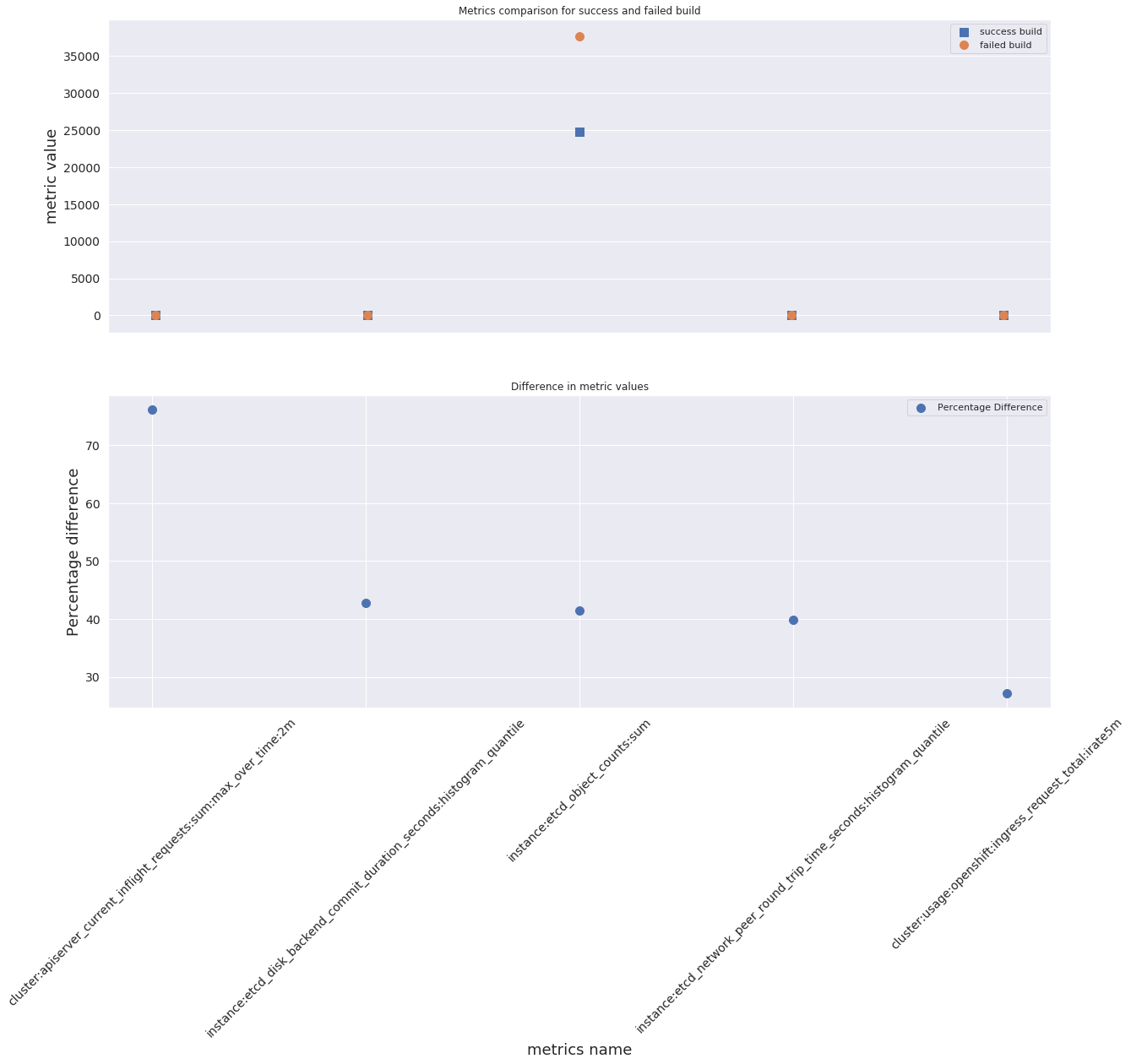
df_mergef
| __name__ | Success_build_value | Failure_build_value | diff | |
|---|---|---|---|---|
| 3 | cluster:apiserver_current_inflight_requests:su... | 13.000000 | 29.000000 | 76.190476 |
| 51 | instance:etcd_disk_backend_commit_duration_sec... | 0.021323 | 0.013819 | 42.706215 |
| 56 | instance:etcd_object_counts:sum | 24702.000000 | 37623.000000 | 41.463297 |
| 55 | instance:etcd_network_peer_round_trip_time_sec... | 0.037786 | 0.025216 | 39.902479 |
| 22 | cluster:usage:openshift:ingress_request_total:... | 3.400000 | 4.466667 | 27.118644 |
We plotted the metric values from the above table along with their respective percentage difference. Even though we do see from the plots that some point for success and failed build are overlapping. The percentage difference plot clarifies that the two are different and not of same value.
Get Data for Multiple Builds for a Given Job#
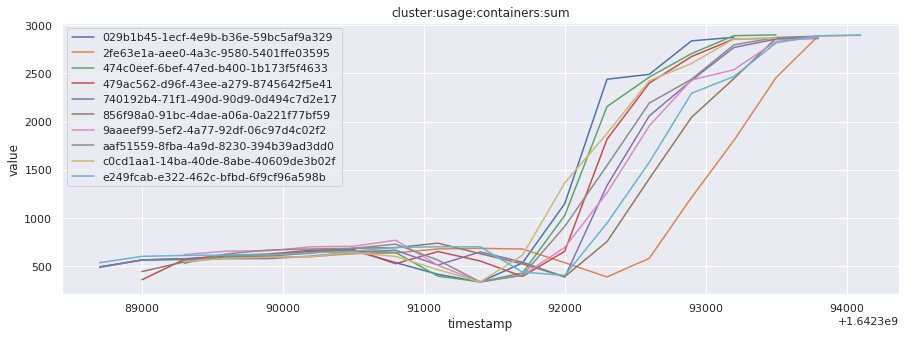
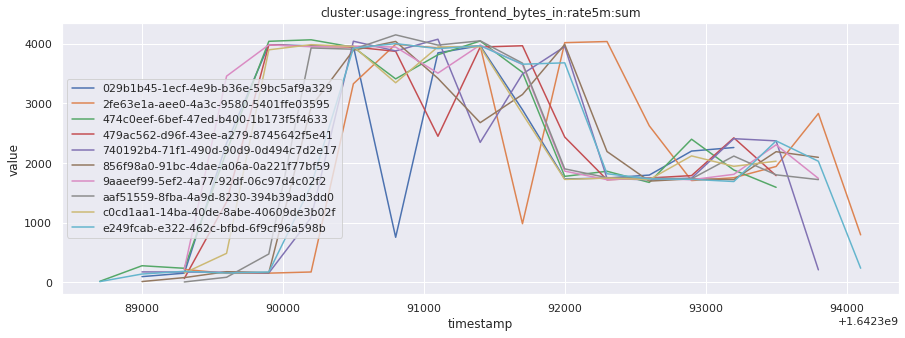
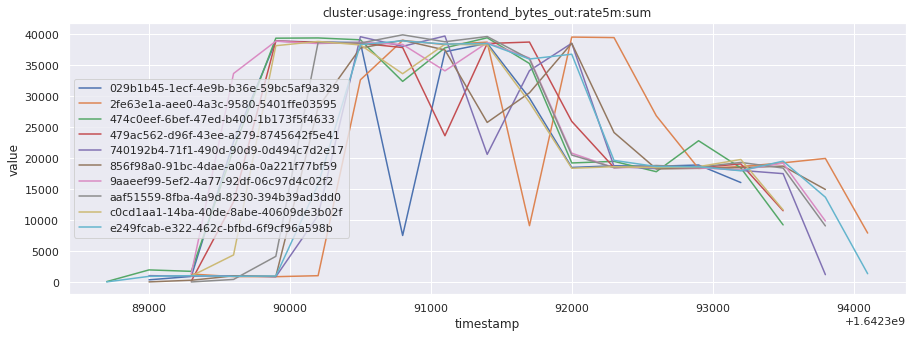
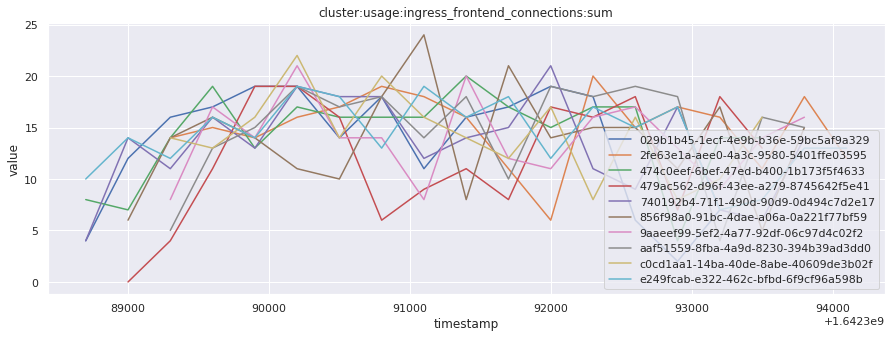
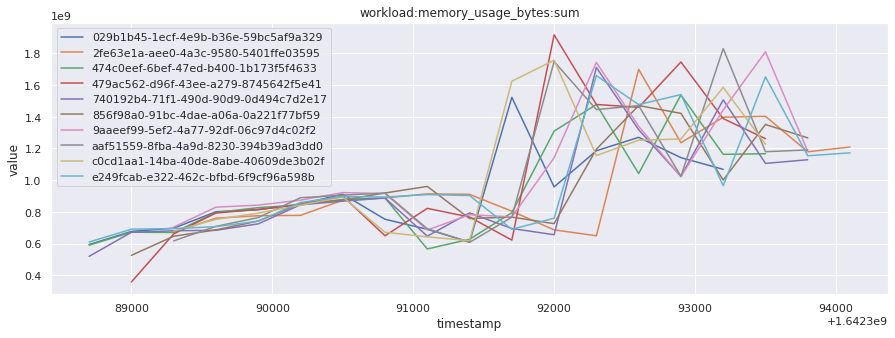
In this section, we will fetch all the telemetry metrics from all timestamps for the top 10 most recent builds for a given job. This data can help understand how the behavior of the available metrics changed over time, across builds.
# fetch data from this number of builds for this job
NBUILDS = 10
# number of previous days of data to search to get the last n builds data for this job
NDAYS = 2
# max runtime of a build
# NOTE: this is a (over)estimate number derived from SME conversations, as well as time duration from testgrid
MAX_DURATION_HRS = 12
# get invoker details
prev_ndays_invokers = MetricRangeDataFrame(
pc.custom_query_range(
query=f'max by (_id, invoker) (cluster_installer{{invoker=~"^openshift-internal-ci/{job_name}.*"}})',
end_time=query_eval_time,
start_time=query_eval_time - dt.timedelta(days=NDAYS),
step="5m",
)
).sort_index()
# split invoker name into prefix, job id, build id.
prev_ndays_invokers[["prefix", "job_name", "build_id"]] = prev_ndays_invokers[
"invoker"
].str.split("/", expand=True)
# drop now redundant columns.
prev_ndays_invokers.drop(columns=["invoker", "prefix", "value"], inplace=True)
# drop irrelevant columns.
prev_ndays_invokers.drop(columns=drop_cols, errors="ignore", inplace=True)
prev_ndays_invokers.head()
| _id | job_name | build_id | |
|---|---|---|---|
| timestamp | |||
| 1642388700 | e249fcab-e322-462c-bfbd-6f9cf96a598b | periodic-ci-openshift-release-master-nightly-4... | 1482905366760001536 |
| 1642388700 | 740192b4-71f1-490d-90d9-0d494c7d2e17 | periodic-ci-openshift-release-master-nightly-4... | 1482905366944550912 |
| 1642388700 | 029b1b45-1ecf-4e9b-b36e-59bc5af9a329 | periodic-ci-openshift-release-master-nightly-4... | 1482905366688698368 |
| 1642389000 | 474c0eef-6bef-47ed-b400-1b173f5f4633 | periodic-ci-openshift-release-master-nightly-4... | 1482905366797750272 |
| 1642389000 | 740192b4-71f1-490d-90d9-0d494c7d2e17 | periodic-ci-openshift-release-master-nightly-4... | 1482905366944550912 |
# for each build, get cluster id and then the corresponding metrics from all timestamps
all_metrics_df = pd.DataFrame()
for build_id in tqdm(prev_ndays_invokers["build_id"].unique()[:NBUILDS]):
job_build_cluster_installer = pc.custom_query_range(
query=f'cluster_installer{{invoker="openshift-internal-ci/{job_name}/{build_id}"}}',
end_time=query_eval_time,
start_time=query_eval_time
- dt.timedelta(days=NDAYS)
- dt.timedelta(days=MAX_DURATION_HRS),
step="5m",
)
# extract cluster id out of the installer info metric
cluster_id = job_build_cluster_installer[0]["metric"]["_id"]
# get all telemetry time series
for metric in metrics_to_fetch:
# fetch the metric
metric_result = pc.custom_query_range(
query=f'{metric}{{_id="{cluster_id}"}}',
end_time=query_eval_time,
start_time=query_eval_time
- dt.timedelta(days=NDAYS)
- dt.timedelta(days=MAX_DURATION_HRS),
step="5m",
)
if len(metric_result) > 0:
metric_df = MetricRangeDataFrame(metric_result).reset_index(drop=False)
# drop irrelevant cols, if any
metric_df.drop(columns=drop_cols, errors="ignore", inplace=True)
# combine all the metrics data.
all_metrics_df = pd.concat(
[
all_metrics_df,
metric_df,
],
axis=0,
join="outer",
ignore_index=True,
)
all_metrics_df["value"] = all_metrics_df["value"].astype(float)
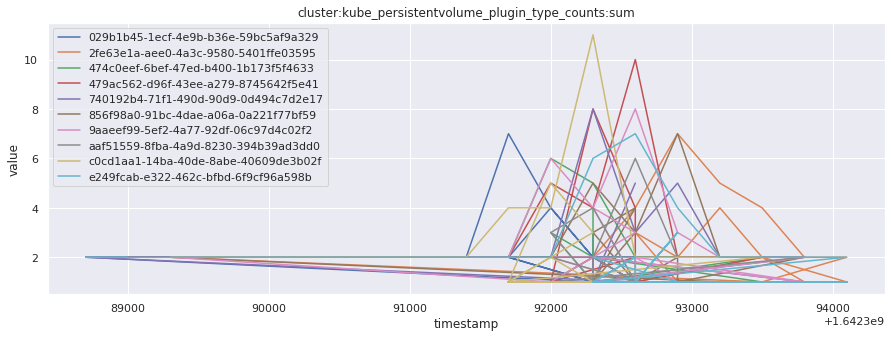
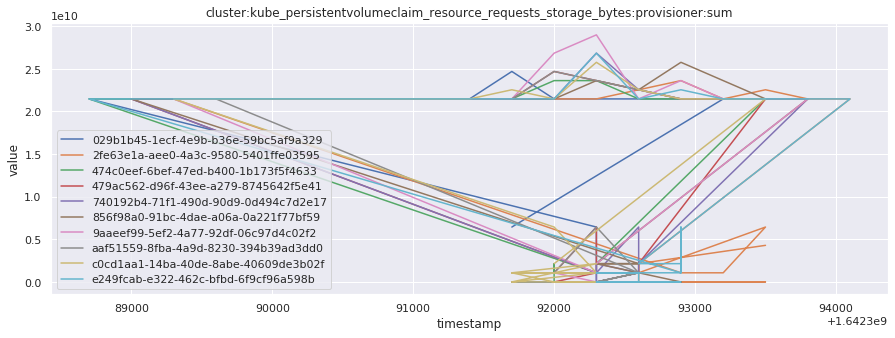
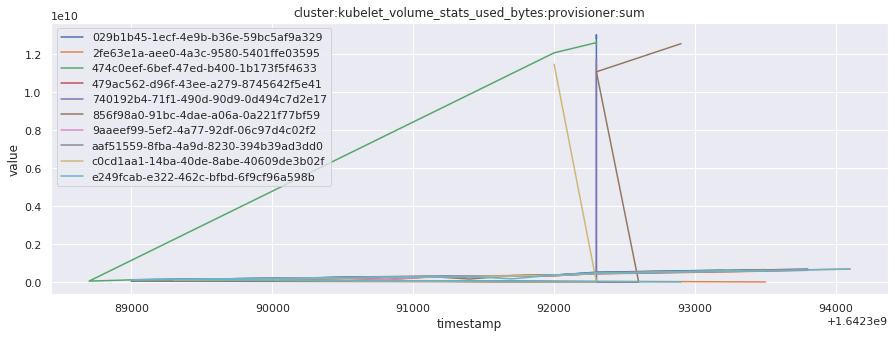
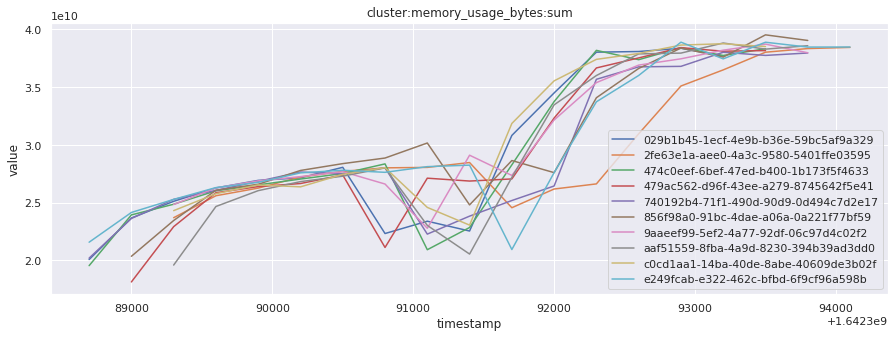
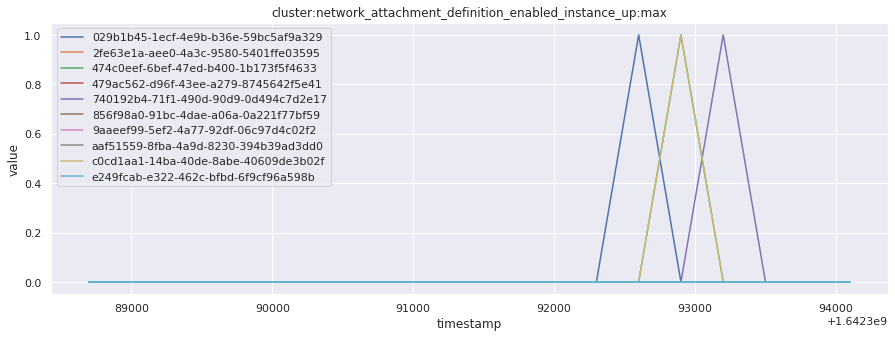
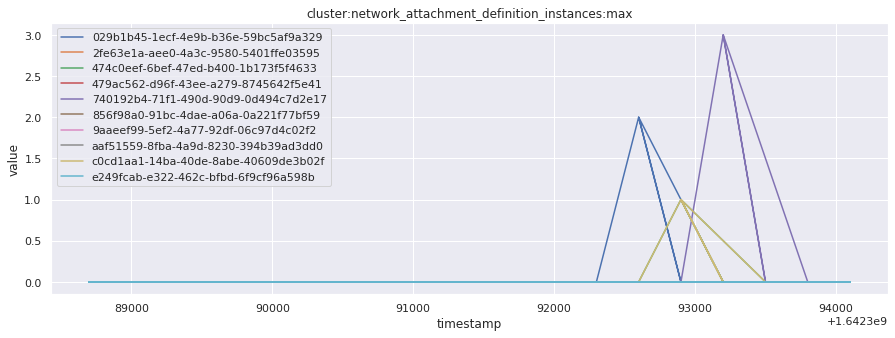
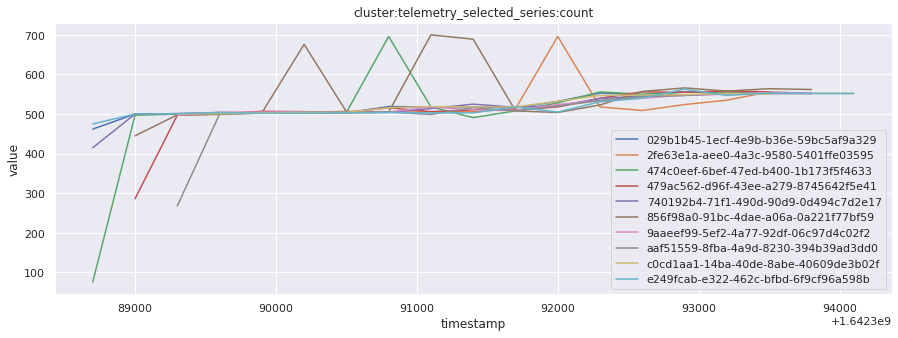
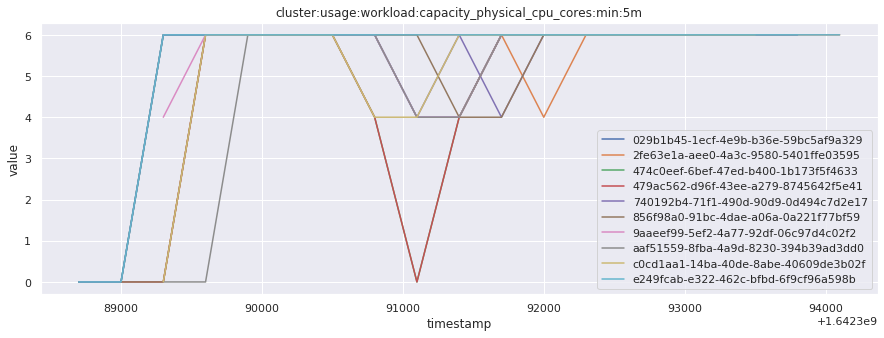
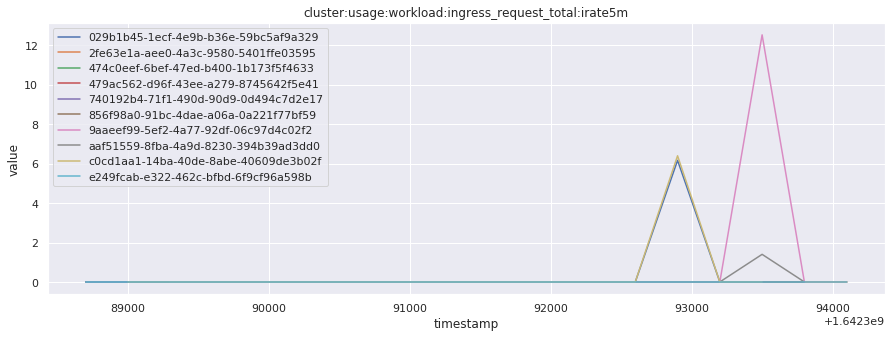
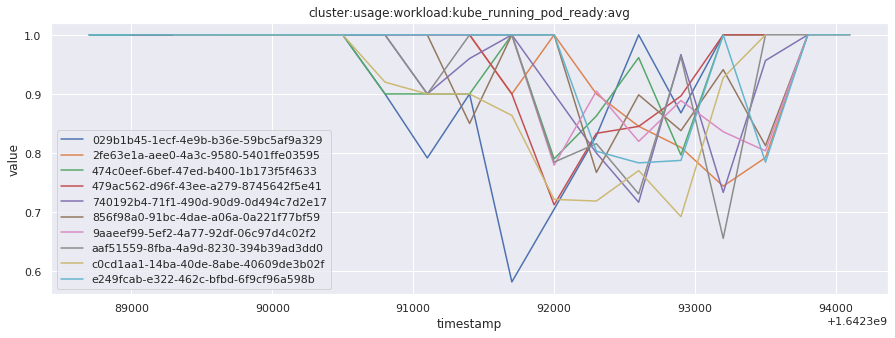
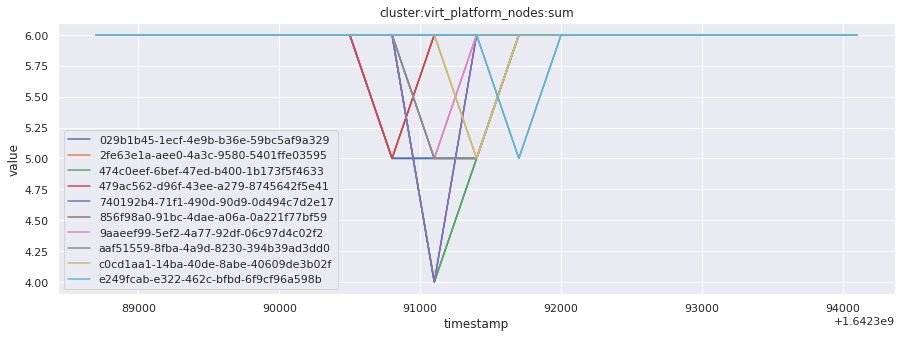
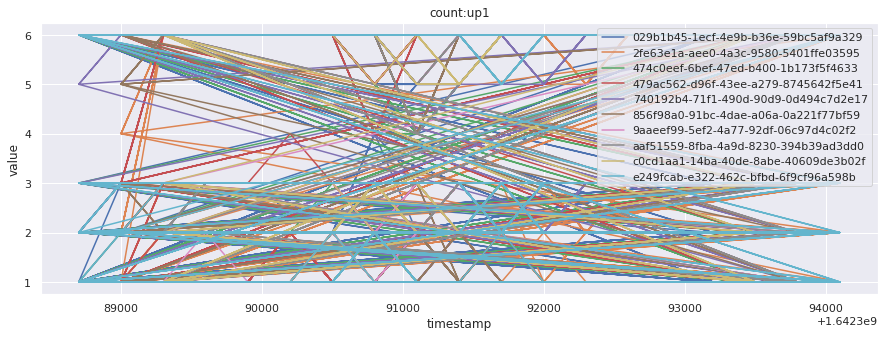
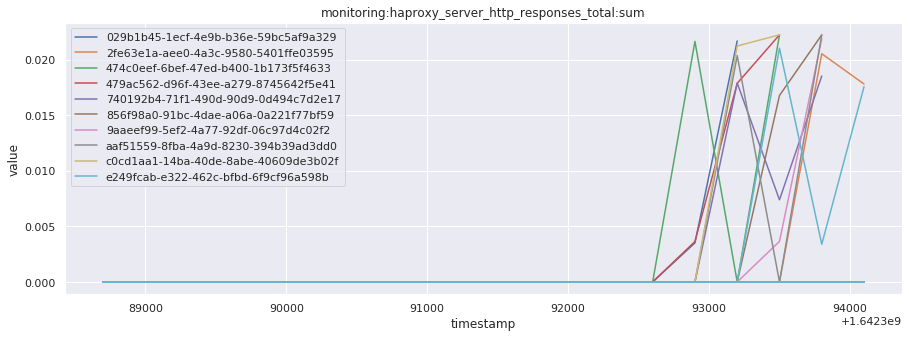
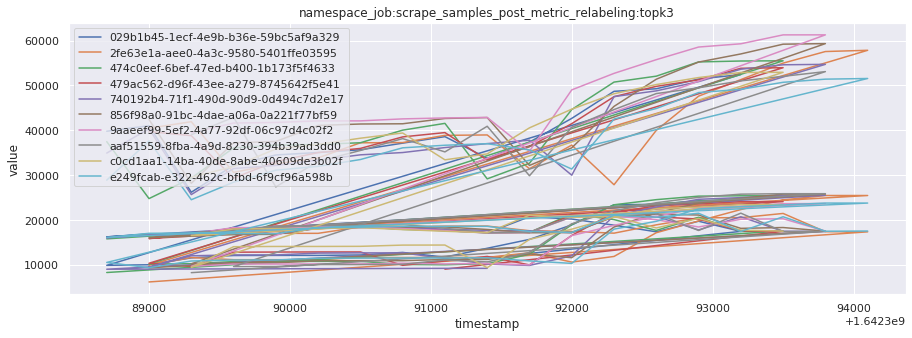
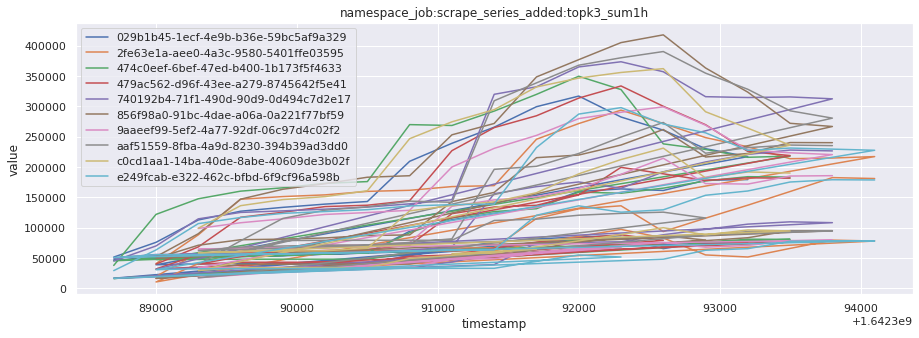
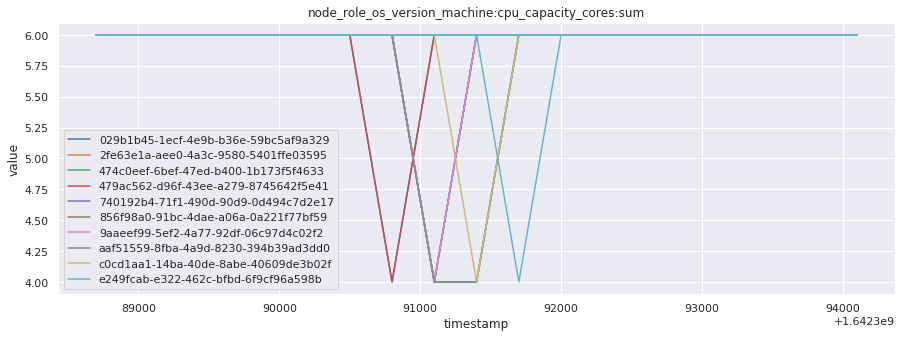
# visualize time series behavior across builds
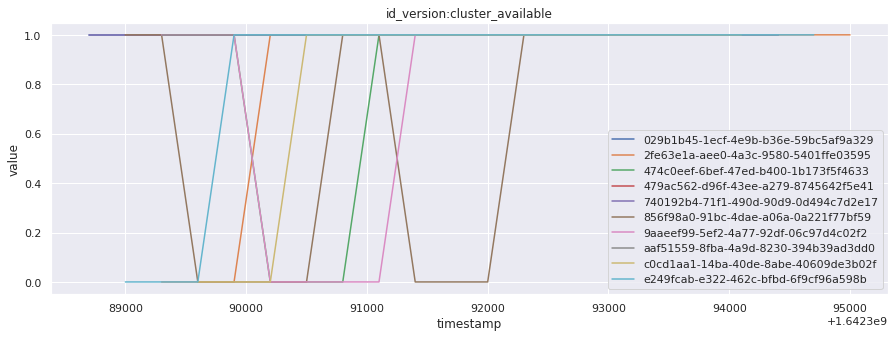
for metric in all_metrics_df["__name__"].unique():
plt.figure(figsize=(15, 5))
metric_df = all_metrics_df[all_metrics_df["__name__"] == metric][
["_id", "timestamp", "value"]
]
metric_df.set_index("timestamp").groupby("_id").value.plot(legend=True)
plt.xlabel("timestamp")
plt.ylabel("value")
plt.legend(loc="best")
plt.title(metric)
plt.show()
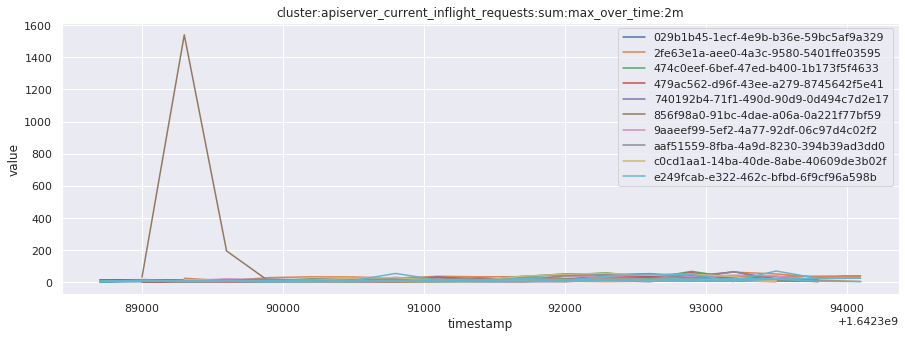
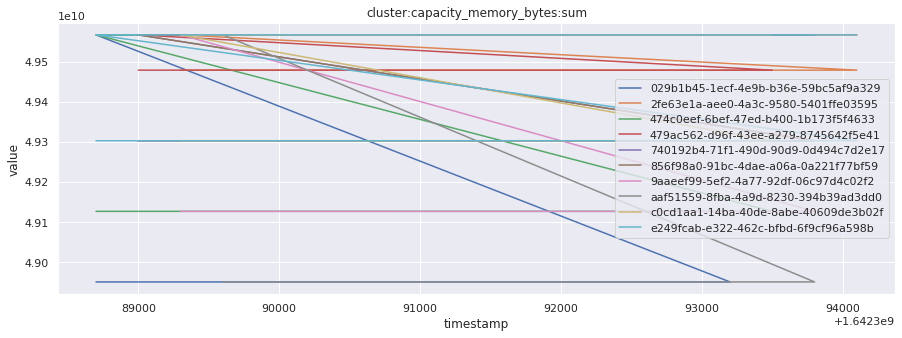
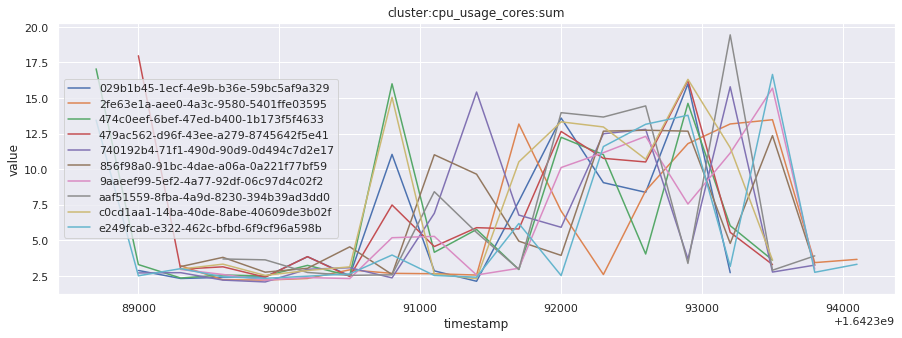
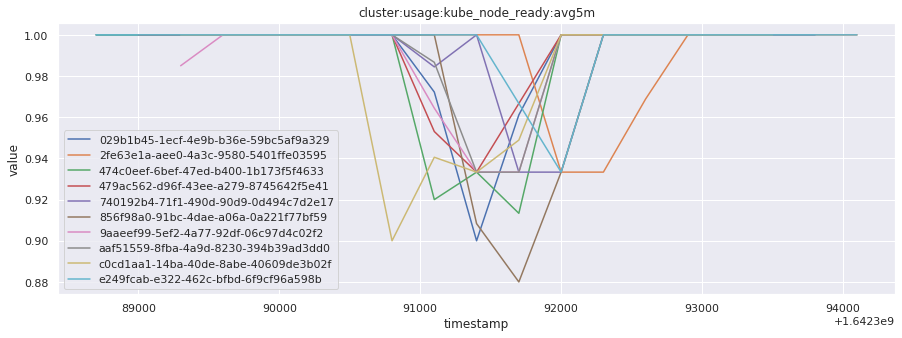
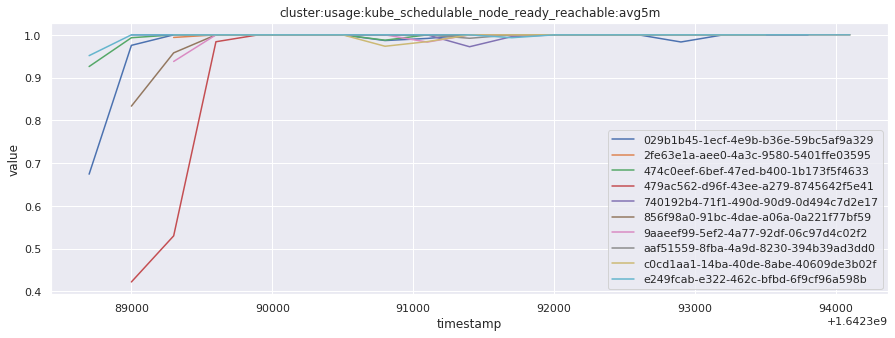
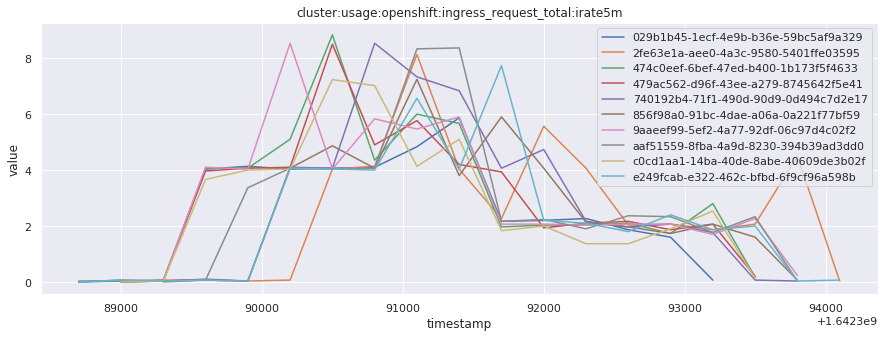
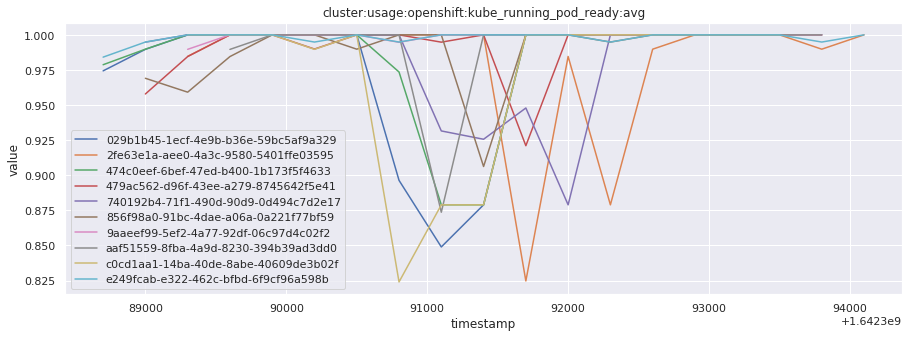
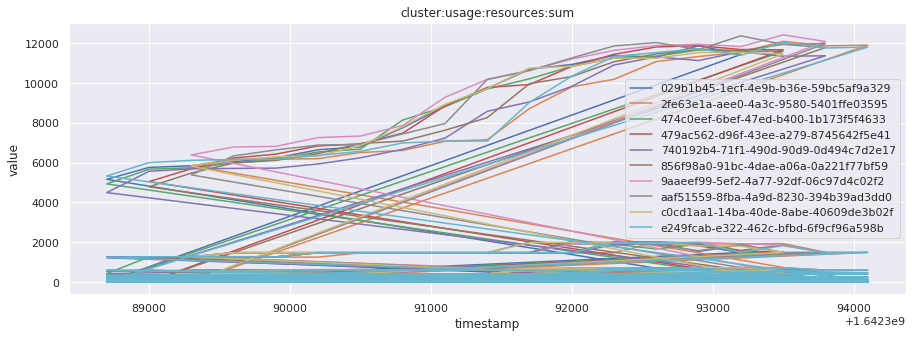
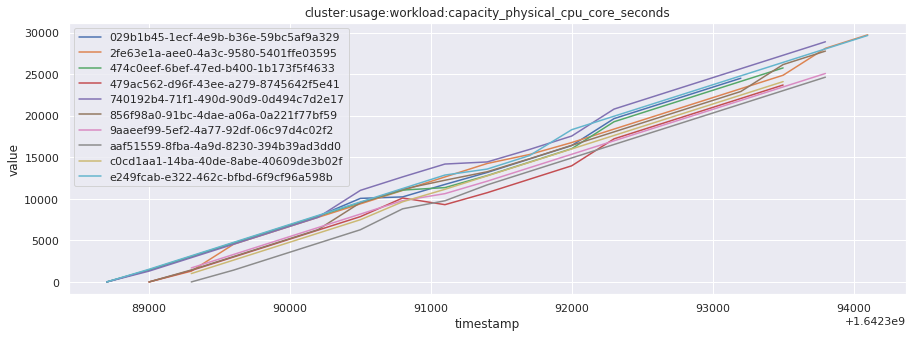
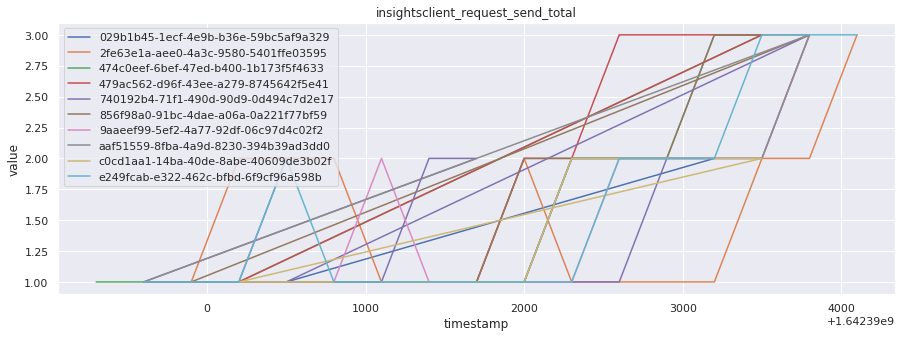
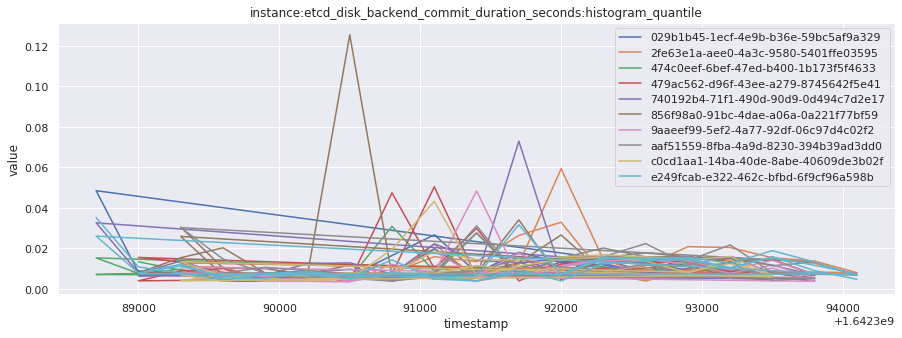
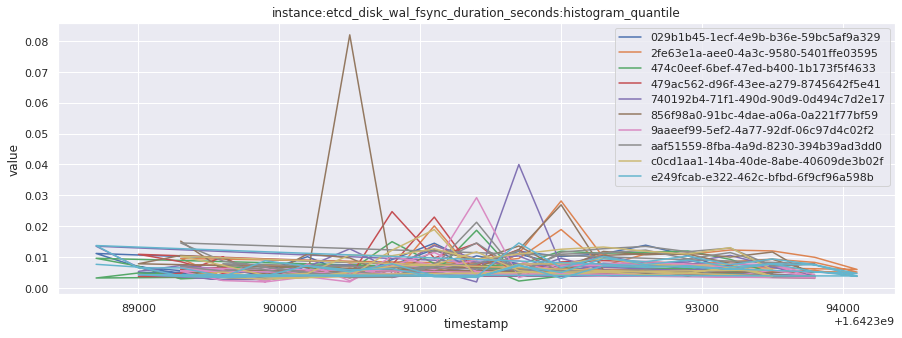
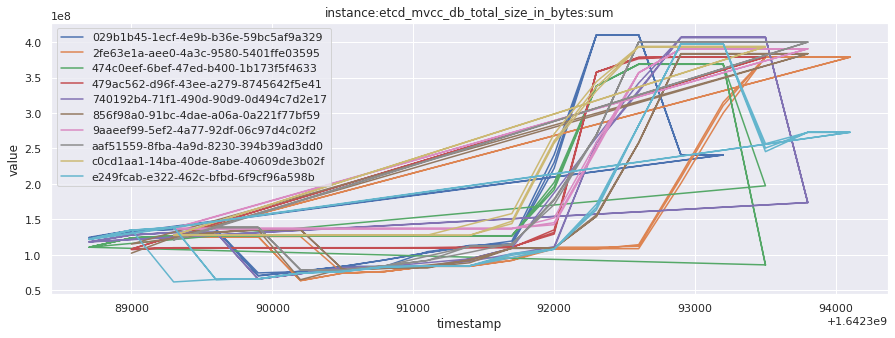
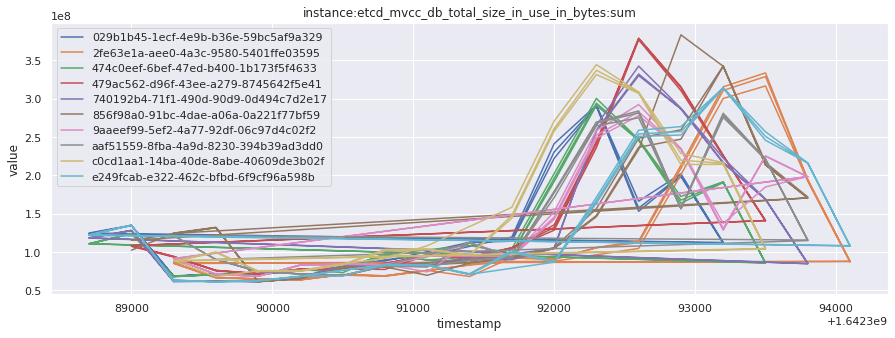
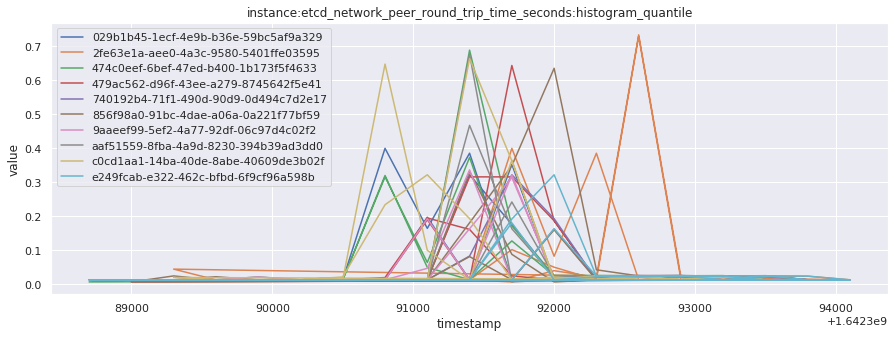
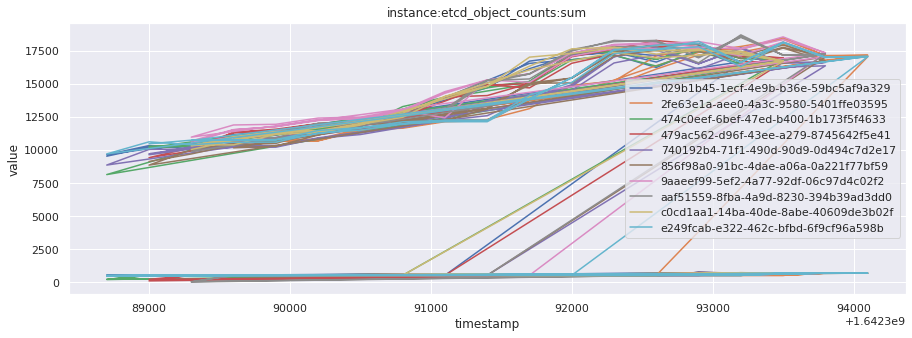
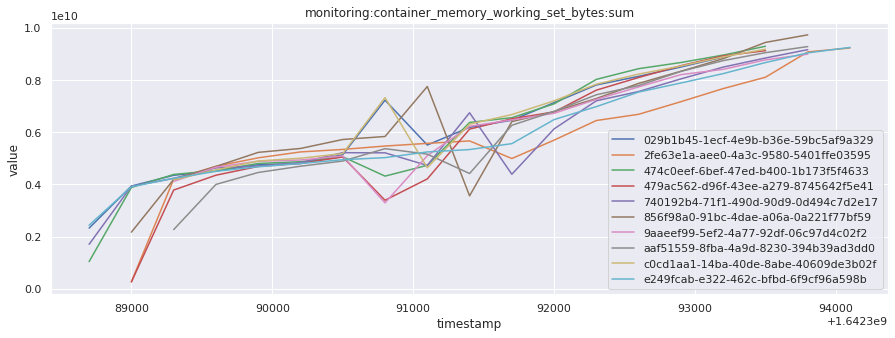
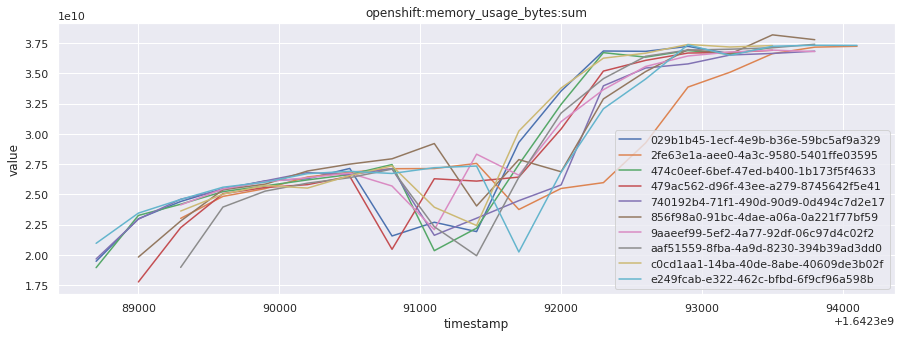
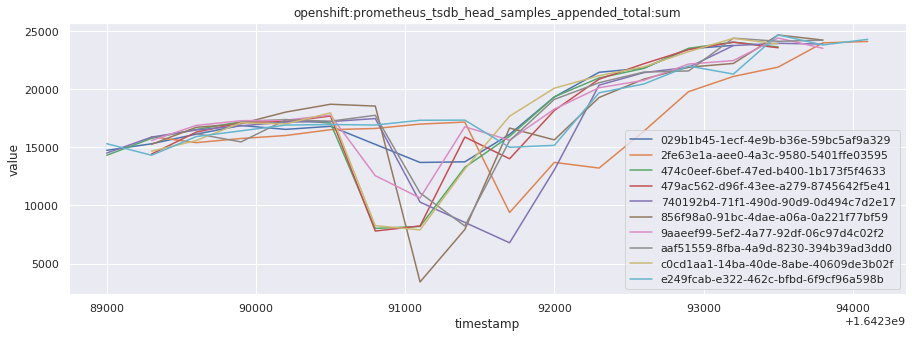
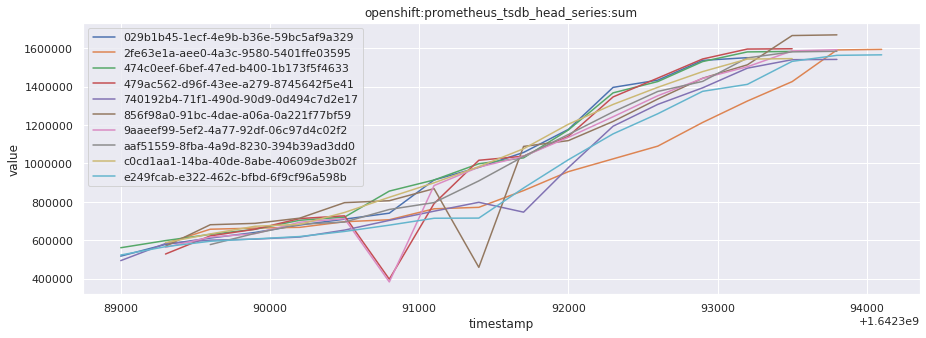
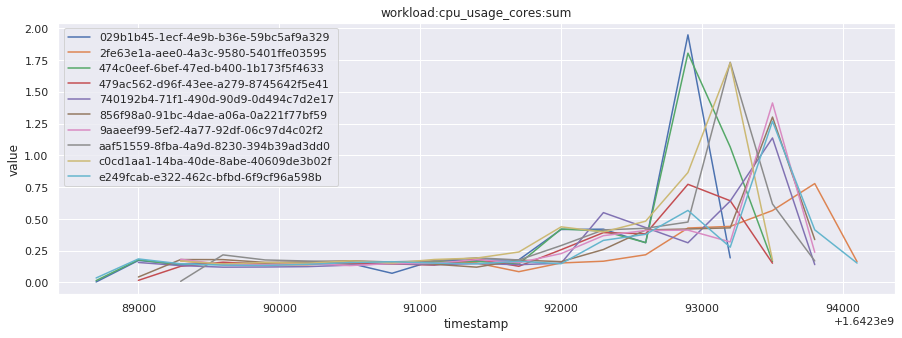
# save the metrics as a static dataset to use in future
save_to_disk(
all_metrics_df,
"../../../data/raw/",
f"telemetry-{query_eval_time.year}-{query_eval_time.month}-{query_eval_time.day}.parquet",
)
True
Conclusion#
In this notebook, we have :
Checked the status of (pass/fail) builds of corresponding job.
Collected all telemetry data corresponding to a given job and build.
Compared the telemetry data for both SUCCESSFUL and FAILED builds of corresponding job.
Understood how to interpret Prometheus data using an example metric.
Collected all telemetry data from all timestamps for the top 10 most recent builds for a given job.
Visualized what the general time series behavior of metrics looks like across builds.
Saved the above data for further analysis.