GitHub Data for OpenShift Origins¶
In this notebook we will quickly walk through how to access and start analyzing the PR data for the OpenShift origins repository. We also explore the various fields in the PR dataset and the features that we can derive from them in order to frame an ML problem where we predict the time taken to merge a PR.
The ultimate hope for this work is that we will be able to connect the Github data (code changes) directly with the Bugs, Telemetry, TestGrid and Prow datasets in order to develop a complete picture of the OpenShift CI process.
Data Collection¶
The Thoth team already developed a tool for collecting data and perfoming analysis on GitHub repositoreis, MI-Scheduler. So, we will not be accessing the data directly from GitHub, but from ceph storage after requesting that the OpenShift/Origin repo be included in the MI-Scheduler tool (see issue for details).
import os
import sys
import gzip
import json
import boto3
import pathlib
import datetime
from tqdm import tqdm
from functools import partial
from collections import Counter
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import STOPWORDS
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.feature_selection import mutual_info_classif, f_classif
from dotenv import load_dotenv, find_dotenv
metric_template_path = "../TestGrid/metrics"
if metric_template_path not in sys.path:
sys.path.insert(1, metric_template_path)
from ipynb.fs.defs.metric_template import ( # noqa: E402
CephCommunication,
save_to_disk,
)
sns.set(rc={"figure.figsize": (20, 10)})
load_dotenv(find_dotenv())
True
## CEPH Bucket variables
## Create a .env file on your local with the correct configs,
s3_endpoint_url = os.getenv("S3_ENDPOINT")
s3_access_key = os.getenv("S3_ACCESS_KEY")
s3_secret_key = os.getenv("S3_SECRET_KEY")
s3_bucket = os.getenv("S3_BUCKET")
s3_path = os.getenv("S3_PROJECT_KEY", "github")
s3_input_data_path = "raw_data"
REMOTE = os.getenv("REMOTE")
data_path = "../../../data/raw/GitHub/PullRequest.json.gz"
OUTPUT_DATA_PATH = "../../../data/processed/github"
if REMOTE:
print("getting dataset from ceph")
s3 = boto3.resource(
"s3",
endpoint_url=s3_endpoint_url,
aws_access_key_id=s3_access_key,
aws_secret_access_key=s3_secret_key,
)
content = s3.Object(s3_bucket, "thoth/mi/openshift/origin/PullRequest.json")
file = content.get()["Body"].read().decode("utf-8")
prs = json.loads(file)
with gzip.open(data_path, "wb") as out_file:
out_file.write(json.dumps(prs).encode("utf-8"))
else:
print("getting dataset from local")
with gzip.open(data_path, "r") as f:
prs = json.loads(f.read().decode("utf-8"))
pr_df = pd.DataFrame(prs).T
getting dataset from ceph
pr_df.shape
(17183, 15)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | interactions | reviews | labels | commits | changed_files | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26100 | bug 1949306: add e2e test to block usage of re... | Right now this is set to flake in CI and provi... | XXL | deads2k | 1619104429 | 1619253940 | openshift-merge-robot | 1619253940 | 2 | 135 | {'deads2k': 1, 'openshift-ci-robot': 307, 'stt... | {} | [approved, bugzilla/severity-urgent, bugzilla/... | [13b0e99d5f35d85998af9f07eb0c5b7d6fcc0dd0, 0c3... | [go.mod, go.sum, test/extended/apiserver/api_r... |
| 26099 | bug 1951705: allow HighOverallControlPlaneCPU ... | adding the alert in https://github.com/openshi... | XS | deads2k | 1619091511 | 1619113470 | openshift-merge-robot | 1619113470 | 1 | 1 | {'openshift-ci-robot': 508, 'deads2k': 43, 'op... | {} | [approved, bugzilla/severity-high, bugzilla/va... | [7bc10c83eea29010f3b735c41847d43a992f606c] | [test/extended/prometheus/prometheus.go] |
Inspect the dataset¶
Let’s unroll a single row and see what kind of information we have access to.
pr = pr_df.iloc[4]
pr
title Bug 1949050: fix images.sh script
body This is a followup to https://github.com/opens...
size S
created_by soltysh
created_at 1618993979
closed_at 1619069721
closed_by openshift-merge-robot
merged_at 1619069721
commits_number 1
changed_files_number 2
interactions {'openshift-ci-robot': 279, 'soltysh': 2, 'ope...
reviews {'641526396': {'author': 'adambkaplan', 'words...
labels [approved, bugzilla/severity-high, bugzilla/va...
commits [06830a927241a44ae24e9a4b5b2ac75f666d36bc]
changed_files [test/extended/testdata/bindata.go, test/exten...
Name: 26096, dtype: object
Available Fields¶
title: text providing a short description of the of the PR.
body: text providing additional details regarding the changes.
size: categorical label generated by GitHub summerizing the size of the changes made to the code base.
created/closed/merged_at: timestamps for when the PR was opened, merged and finally closed.
created/closed_by: usernames for contributors who created the PR and closed it.
commits_number: integer indicating the number of commits in the PR.
changed_files_number: integer indicating the number of files changed.
The remaining fields appear to be collections of items, let’s unroll each one and see what additional information they provide.
pr["interactions"]
{'openshift-ci-robot': 279,
'soltysh': 2,
'openshift-bot': 180,
'openshift-ci[bot]': 79}
interactions: a dictionary with usernames for keys and the number of times they interacted with the PR as the value.
pr["reviews"]
{'641526396': {'author': 'adambkaplan',
'words_count': 1,
'submitted_at': 1619032331,
'state': 'APPROVED'}}
reviews: a dictionary of reviews that includes an id number key along with fields for author, word_count, submitted timestamp and state of review.
pr["labels"]
['approved', 'bugzilla/severity-high', 'bugzilla/valid-bug', 'lgtm']
labels: a list of labels tagged to the PR describing some of its attributes
pr["commits"]
['06830a927241a44ae24e9a4b5b2ac75f666d36bc']
commits: a list of commit hashes that point to specific changes made to the repo’s history
print(len(pr["changed_files"]))
pr["changed_files"][0:10]
2
['test/extended/testdata/bindata.go',
'test/extended/testdata/cmd/test/cmd/images.sh']
changed_files: a list of the paths and filenames for every file changed by this PR.
We now know what we have access to in this dataset. It is a collection of numerical, categorical and textual features used to describe a PR. This gives us a lot of potential avenues to explore from an EDA and Data Science perspective. But is also creates an additional challenge insofar as we’ll need to do a bit of feature engineering to get this data into format that is ready to be ingested by any ML models.
Feature engineering¶
In the next section we will do some basic feature engineering and correlation analyis on our dataset to see if anything interesting jumps out at us.
Time to Merge
We will derive a new feature called time_to_merge which will be the difference between the created_at and merged_at fields.
# derive time_to_merege
pr_df["time_to_merge"] = pr_df["merged_at"] - pr_df["created_at"]
pr_df["time_to_merge"] = pr_df["time_to_merge"].astype("float")
# NOTE: we cant fill NA with 0 because that would imply the PR got merged instantaneously
Let’s look at the distribution of the time to merge column. This can help us determine what the setup for ML problems such as #236 could be like. That is, should the time to merge problem be framed as a regression or classification problem.
First, lets try to determine what the granularity of the output values should be, in case of a regression setup. That is, should the model predict time to merge in number of seconds, number of hours, number of days, or some other chunk of time.
# what does the distribution of values look like if we choose days as the granularity
ttm_days = np.ceil(pr_df.time_to_merge / (60 * 60 * 24))
# value counts - to how many PRs have value 1, 2, 3, etc. for days to merge
vc = ttm_days.value_counts()
# normalized value counts (i.e. percent of PRs instead of raw number)
nvc = vc / vc.sum()
nvc
1.0 0.398226
2.0 0.145972
3.0 0.075166
4.0 0.050924
5.0 0.041463
...
150.0 0.000074
237.0 0.000074
197.0 0.000074
167.0 0.000074
170.0 0.000074
Name: time_to_merge, Length: 186, dtype: float64
# only plot top 100 values so that graph is legible
nvc.sort_index().iloc[:100].plot(kind="bar")
plt.xlabel("Days")
plt.ylabel("Number of PRs")
plt.title("Number of PRs per Day")
plt.show()
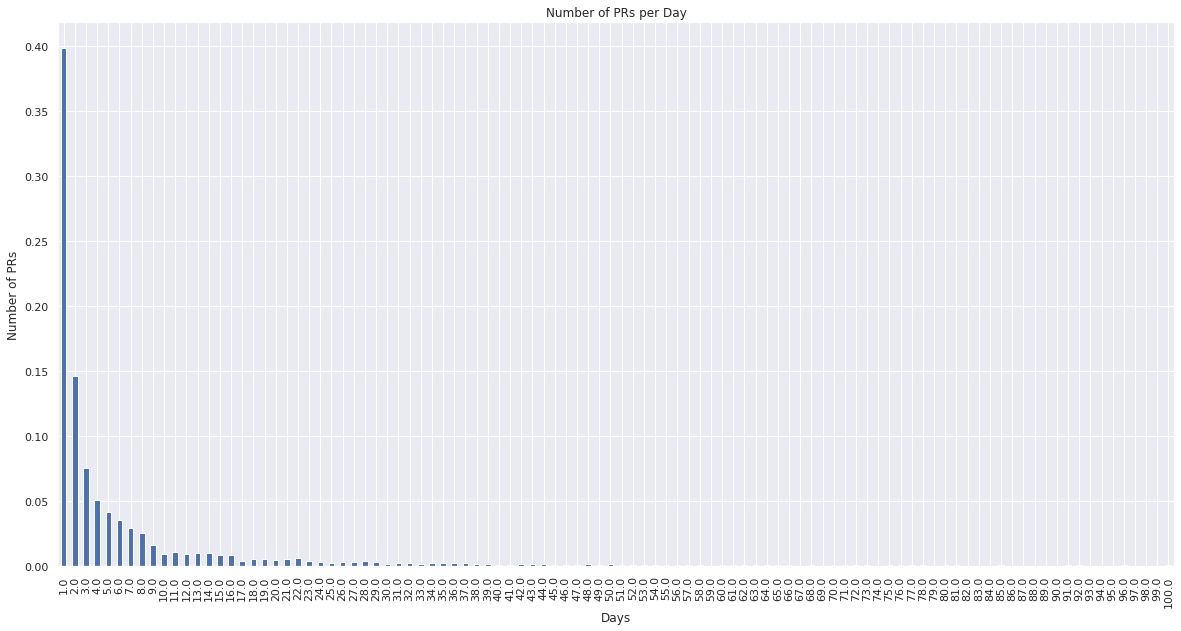
From the above graph we can see that if we bucket the data into days, then roughly 40% of the data points would have the value “1”, 15% would have the value “2” and so on. Therefore we need to select a finer granularity.
# what if we chose some intermediate value e.g. 3 hours as the granularity?
ttm_3hours = np.ceil(pr_df.time_to_merge / (60 * 60 * 3))
# value counts - to how many PRs have value 1, 2, 3, etc. for num. 3-hours to merge
vc = ttm_3hours.value_counts()
# normalized value counts (i.e. percent of PRs instead of raw number)
nvc = vc / vc.sum()
nvc
1.0 0.098670
2.0 0.080414
3.0 0.054619
4.0 0.038655
8.0 0.034812
...
580.0 0.000074
489.0 0.000074
566.0 0.000074
345.0 0.000074
971.0 0.000074
Name: time_to_merge, Length: 691, dtype: float64
# only plot top 100 values so that graph is legible
nvc.sort_index().iloc[:100].plot(kind="bar")
plt.xlabel("3 Hour Intervals")
plt.ylabel("Number of PRs")
plt.title("Number of PRs per 3 Hour Interval")
plt.show()
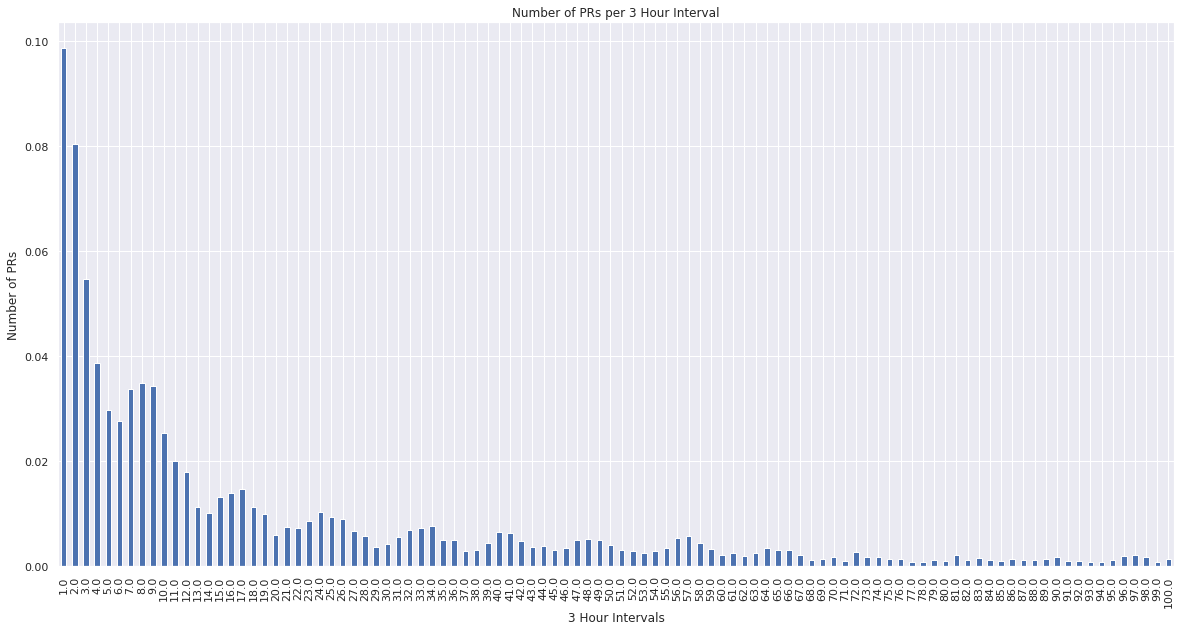
From the above outputs we can see that if we bucket the data into 3 hours, then roughly 10% of the data points would have the value “1”, 10% would have the value “2”, 5% would have the value 3, and so on. This is a slightly better value distribution than before, but could be made even better. Lets explore what this would look like with an “hours” granularity.
# what if we chose hours as the granularity?
ttm_hours = np.ceil(pr_df.time_to_merge / (60 * 60))
# value counts - to how many PRs have value 1, 2, 3, etc. for hours to merge
vc = ttm_hours.value_counts()
# normalized value counts (i.e. percent of PRs instead of raw number)
nvc = vc / vc.sum()
nvc
3.0 0.034368
2.0 0.034368
4.0 0.030007
1.0 0.029933
5.0 0.026829
...
827.0 0.000074
812.0 0.000074
733.0 0.000074
1714.0 0.000074
1854.0 0.000074
Name: time_to_merge, Length: 1314, dtype: float64
# only plot top 100 values so that graph is legible
nvc.sort_index().iloc[:100].plot(kind="bar")
plt.xlabel("Hours")
plt.ylabel("Number of PRs")
plt.title("Number of PRs per Hour")
plt.show()
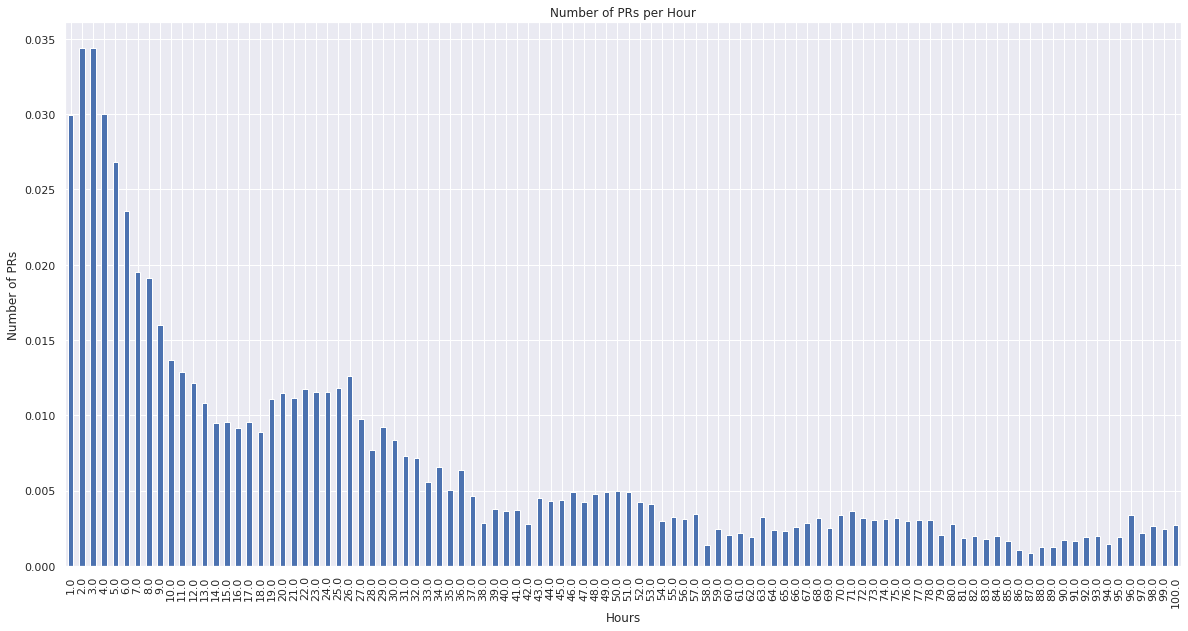
From the above outputs we can see that if we bucket the data into hours, then roughly 3% of the data points would have the value “2”, 3% would have the value “3”, 3% would have the value “4”, and so on. This seems like a reasonable distribution of values for a regression problem, since the data does not get skewed towards any one particular value.
As we make it more granular (e.g. minutes), the distribution would get even more uniform. However, a granularity finer than 1 hour might not provide any additional value to the end user. So we will go with granularity of 1 hour for our regression setup.
Now, lets try to determine, if we were to set this up as a classification problem, what the output classes should be. In the following cell, we’ll try to split the time-to-merge values into 10 equally populated buckets.
# lets look at what the 10th, 20th, 30th etc percentiles are, to see what the bin boundaries (in terms of hours)
# would be if we were to split the data in 10 equally populated bins
n_buckets = 10
quantiles = pr_df.time_to_merge.quantile(q=np.arange(0, 1 + 1e-100, 1 / n_buckets))
quantiles / 3600
0.0 0.000833
0.1 3.055000
0.2 7.060056
0.3 14.783722
0.4 24.154278
0.5 36.940833
0.6 65.870667
0.7 112.790861
0.8 191.135000
0.9 462.285278
Name: time_to_merge, dtype: float64
# gaps between the buckets (i.e. size of each bucket) in hours
(quantiles - quantiles.shift()) / 3600
0.0 NaN
0.1 3.054167
0.2 4.005056
0.3 7.723667
0.4 9.370556
0.5 12.786556
0.6 28.929833
0.7 46.920194
0.8 78.344139
0.9 271.150278
Name: time_to_merge, dtype: float64
If we want to frame our ML problem as a classification problem, we can use the above buckets to define the classes. That is, class 0 is “merged within 3 hours”, class 1 is “merged within 3-7 hours”, etc.
Based on the EDA so far, we cannot conclusively reject either classification or regression. We can explore both of these approaches in depth in forthcoming notebooks and re-evaluate the best setup for this problem.
Body
Here, we will derive a feature called body_size which will simply be the number of words in the body of the PR. We can use this numerical value to describe the body of the PR.
# derive body_size
pr_df["body_size"] = pr_df["body"].fillna("").apply(lambda x: len(x.split()))
# derive body_size
pr_df["body_size"] = pr_df["body"].fillna("").apply(lambda x: len(x.split()))
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | interactions | reviews | labels | commits | changed_files | time_to_merge | body_size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26100 | bug 1949306: add e2e test to block usage of re... | Right now this is set to flake in CI and provi... | XXL | deads2k | 1619104429 | 1619253940 | openshift-merge-robot | 1619253940 | 2 | 135 | {'deads2k': 1, 'openshift-ci-robot': 307, 'stt... | {} | [approved, bugzilla/severity-urgent, bugzilla/... | [13b0e99d5f35d85998af9f07eb0c5b7d6fcc0dd0, 0c3... | [go.mod, go.sum, test/extended/apiserver/api_r... | 149511.0 | 37 |
| 26099 | bug 1951705: allow HighOverallControlPlaneCPU ... | adding the alert in https://github.com/openshi... | XS | deads2k | 1619091511 | 1619113470 | openshift-merge-robot | 1619113470 | 1 | 1 | {'openshift-ci-robot': 508, 'deads2k': 43, 'op... | {} | [approved, bugzilla/severity-high, bugzilla/va... | [7bc10c83eea29010f3b735c41847d43a992f606c] | [test/extended/prometheus/prometheus.go] | 21959.0 | 30 |
Size
We can attempt to convert the categorical size label generated by GitHub, which summerizes the size of the changes made to the code base, to a numerical value.
convert_size = {"size": {"XS": 0, "S": 1, "M": 2, "L": 3, "XL": 4, "XXL": 5}}
pr_df = pr_df.replace(convert_size)
Title
Lets try to see if the PR title text can be used to extract any useful information regarding the PR.
# first lets preprocess the text available in the titles
# convert to lowercase
preproc_titles = pr_df["title"].str.lower()
# remove punctuations and symbols like : ; , # ( ) [ ] etc
preproc_titles = preproc_titles.str.replace(r'[`#-.?!,:;\/()\[\]"\']', " ", regex=True)
# remove hash-like strings i.e. 25+ char long strings containing 0-9 or a-f
preproc_titles = preproc_titles.str.replace(r"[0-9a-f]{25,}", " ", regex=True)
preproc_titles
26100 bug 1949306 add e2e test to block usage of re...
26099 bug 1951705 allow highoverallcontrolplanecpu ...
26098 refactor testmultipleimagechangebuildtriggers ...
26097 wip monitor move crashlooping pods test to...
26096 bug 1949050 fix images sh script
...
5 add examples for pod creation
4 wip added project template json schema
3 added etcd folder into gitignore
2 add alpha api documentation
1 add link to gopath doc and fixup typo
Name: title, Length: 17183, dtype: object
# what are the most commonly appearing words in the titles
# combin all titles and split into words
words = preproc_titles.str.cat(sep=" ").split()
# remove stopwords and numbers (e.g. bugzilla ids)
words = [w for w in words if w not in set(STOPWORDS) and not w.isnumeric()]
# word frequencies
unique_words, counts = np.unique(words, return_counts=True)
vc = pd.Series(counts, index=unique_words).sort_values(ascending=False)
# plot the 20 most common words
sns.barplot(
x=vc.index[:20],
y=vc.values[:20],
)
plt.title("Top word frequencies in the PR Titles")
plt.xlabel("words")
plt.ylabel("count")
plt.show()
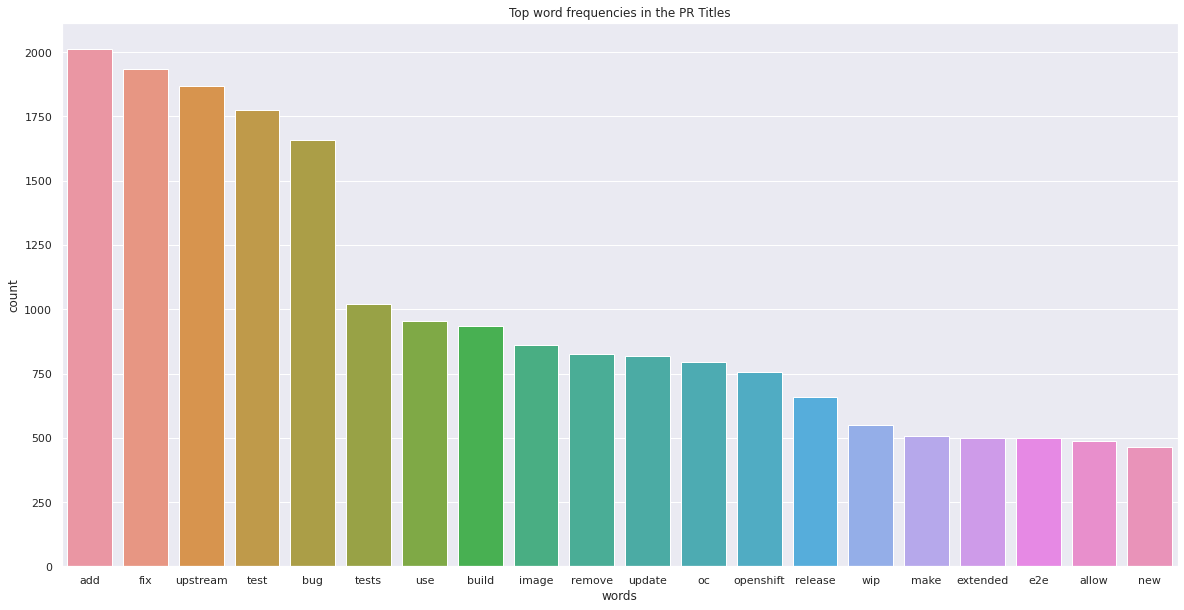
From the above graph, we can see that titles often contain some keywords that can hint towards the type of changes being made in the PR. We will create a feature which is a vector indicating how many times each word appeared in the title. This way, even if a less prominent word is more correlated with time_to_merge, we will be able to capture that relationship.
# add word count columns
for word in tqdm(unique_words):
pr_df[f"title_wordcount_{word}"] = preproc_titles.apply(
lambda x: x.split().count(word)
)
1%|█▎ | 96/7828 [00:01<01:43, 74.51it/s]/tmp/ipykernel_130991/4191214648.py:3: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider using pd.concat instead. To get a de-fragmented frame, use `newframe = frame.copy()`
pr_df[f"title_wordcount_{word}"] = preproc_titles.apply(
100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 7828/7828 [01:53<00:00, 68.96it/s]
# collapse the high dim vector into one column
wordcount_columns = [c for c in pr_df.columns if "wordcount" in c]
pr_df["title_word_counts_vec"] = pr_df[wordcount_columns].apply(
lambda x: x.tolist(), axis=1
)
# drop the individual wordcount columns
pr_df = pr_df.drop(columns=wordcount_columns)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | interactions | reviews | labels | commits | changed_files | time_to_merge | body_size | title_word_counts_vec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26100 | bug 1949306: add e2e test to block usage of re... | Right now this is set to flake in CI and provi... | 5 | deads2k | 1619104429 | 1619253940 | openshift-merge-robot | 1619253940 | 2 | 135 | {'deads2k': 1, 'openshift-ci-robot': 307, 'stt... | {} | [approved, bugzilla/severity-urgent, bugzilla/... | [13b0e99d5f35d85998af9f07eb0c5b7d6fcc0dd0, 0c3... | [go.mod, go.sum, test/extended/apiserver/api_r... | 149511.0 | 37 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 26099 | bug 1951705: allow HighOverallControlPlaneCPU ... | adding the alert in https://github.com/openshi... | 0 | deads2k | 1619091511 | 1619113470 | openshift-merge-robot | 1619113470 | 1 | 1 | {'openshift-ci-robot': 508, 'deads2k': 43, 'op... | {} | [approved, bugzilla/severity-high, bugzilla/va... | [7bc10c83eea29010f3b735c41847d43a992f606c] | [test/extended/prometheus/prometheus.go] | 21959.0 | 30 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
Created By
Is the time taken to merge a PR affected by the author of the PR? E.g. if a code reviewer or someone who has already made several contributions to a repo creates a PR, is it likely to get merged relatively faster?
# approvers and reviewers list from the repo
approvers = [
"bparees",
"deads2k",
"derekwaynecarr",
"eparis",
"knobunc", # Network, Multi-cluster, Storage
"mfojtik",
"pweil-",
"sjenning",
"soltysh",
"sttts",
"smarterclayton",
]
reviewers = [
"bparees",
"deads2k",
"sjenning",
"smarterclayton",
"soltysh",
]
# is the pr creator on the approvers or reviewers list
pr_df["is_reviewer"] = pr_df["created_by"].isin(reviewers)
pr_df["is_approver"] = pr_df["created_by"].isin(approvers)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | interactions | reviews | labels | commits | changed_files | time_to_merge | body_size | title_word_counts_vec | is_reviewer | is_approver | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 26100 | bug 1949306: add e2e test to block usage of re... | Right now this is set to flake in CI and provi... | 5 | deads2k | 1619104429 | 1619253940 | openshift-merge-robot | 1619253940 | 2 | 135 | {'deads2k': 1, 'openshift-ci-robot': 307, 'stt... | {} | [approved, bugzilla/severity-urgent, bugzilla/... | [13b0e99d5f35d85998af9f07eb0c5b7d6fcc0dd0, 0c3... | [go.mod, go.sum, test/extended/apiserver/api_r... | 149511.0 | 37 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | True | True |
| 26099 | bug 1951705: allow HighOverallControlPlaneCPU ... | adding the alert in https://github.com/openshi... | 0 | deads2k | 1619091511 | 1619113470 | openshift-merge-robot | 1619113470 | 1 | 1 | {'openshift-ci-robot': 508, 'deads2k': 43, 'op... | {} | [approved, bugzilla/severity-high, bugzilla/va... | [7bc10c83eea29010f3b735c41847d43a992f606c] | [test/extended/prometheus/prometheus.go] | 21959.0 | 30 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | True | True |
We also want to derive a feature called num_prev_merged_prs captures the number of PRs that the creator created before this PR.
# how many prs did the creator create before this pr
def get_prev_pr_info(creator_pr_df):
num_prev_merged_prs = (
creator_pr_df["time_to_merge"].expanding().count().shift(1).fillna(0)
)
return num_prev_merged_prs
# need to sort before applying groupby
# because merging is not possible as df index types are different
pr_df = pr_df.sort_values(by="created_at")
num_prev_merged_prs = pr_df.groupby("created_by").apply(get_prev_pr_info)
num_prev_merged_prs = num_prev_merged_prs.reset_index(drop=True).rename("num_prev_prs")
pr_df["num_prev_merged_prs"] = num_prev_merged_prs.values
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | ... | reviews | labels | commits | changed_files | time_to_merge | body_size | title_word_counts_vec | is_reviewer | is_approver | num_prev_merged_prs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Add link to GOPATH doc and fixup typo | None | 0 | jwforres | 1407759383 | 1407759502 | smarterclayton | 1407759502 | 1 | 1 | ... | {} | [] | [3c15fd6dd7cee58393feb786fd7876b6f22fe9b5] | [README.md] | 119.0 | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 |
| 2 | Add alpha API documentation | Merge of csrwng/oo-api-v3\n | 5 | csrwng | 1407834992 | 1407844533 | danmcp | 1407844533 | 1 | 54 | ... | {} | [] | [24acb7993293e311e8c1f76f4b17791998c2f391] | [api/README.md, api/build_flow.odg, api/doc/co... | 9541.0 | 3 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 |
2 rows × 21 columns
Created At
This column can give us information on when the PR was created. Using the created_at field, we can derive other features like time_of_day, day_of_week, day_of_month, month_in_year each of which can be categorical features that can be useful to our analysis.
# convert to datetime object
pr_df["created_at_datetime"] = (
pr_df["created_at"].fillna("").apply(lambda x: datetime.datetime.fromtimestamp(x))
)
# get day as categorical variable
pr_df["created_at_day"] = pr_df["created_at_datetime"].apply(lambda x: x.day)
# get month as categorical variable
pr_df["created_at_month"] = pr_df["created_at_datetime"].apply(lambda x: x.month)
# get weekday as categorical variable
pr_df["created_at_weekday"] = pr_df["created_at_datetime"].apply(lambda x: x.weekday())
# get hour of day as categorical variable
pr_df["created_at_hour"] = pr_df["created_at_datetime"].apply(lambda x: x.hour)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | ... | body_size | title_word_counts_vec | is_reviewer | is_approver | num_prev_merged_prs | created_at_datetime | created_at_day | created_at_month | created_at_weekday | created_at_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Add link to GOPATH doc and fixup typo | None | 0 | jwforres | 1407759383 | 1407759502 | smarterclayton | 1407759502 | 1 | 1 | ... | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-11 08:16:23 | 11 | 8 | 0 | 8 |
| 2 | Add alpha API documentation | Merge of csrwng/oo-api-v3\n | 5 | csrwng | 1407834992 | 1407844533 | danmcp | 1407844533 | 1 | 54 | ... | 3 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-12 05:16:32 | 12 | 8 | 1 | 5 |
2 rows × 26 columns
Commits Number
Commits Number gives the number of commits created within the PR. This could be a numerical feature for our model.
pr_df.commits_number.value_counts()
1 13304
2 1986
3 737
4 353
5 234
...
28 1
31 1
83 1
350 1
561 1
Name: commits_number, Length: 105, dtype: int64
pr_df.commits_number.value_counts().sort_index(ascending=True).plot(kind="bar")
plt.title("Commit frequency across PRs")
plt.xlabel("No. of commits")
plt.ylabel("No. of PRs")
plt.show()
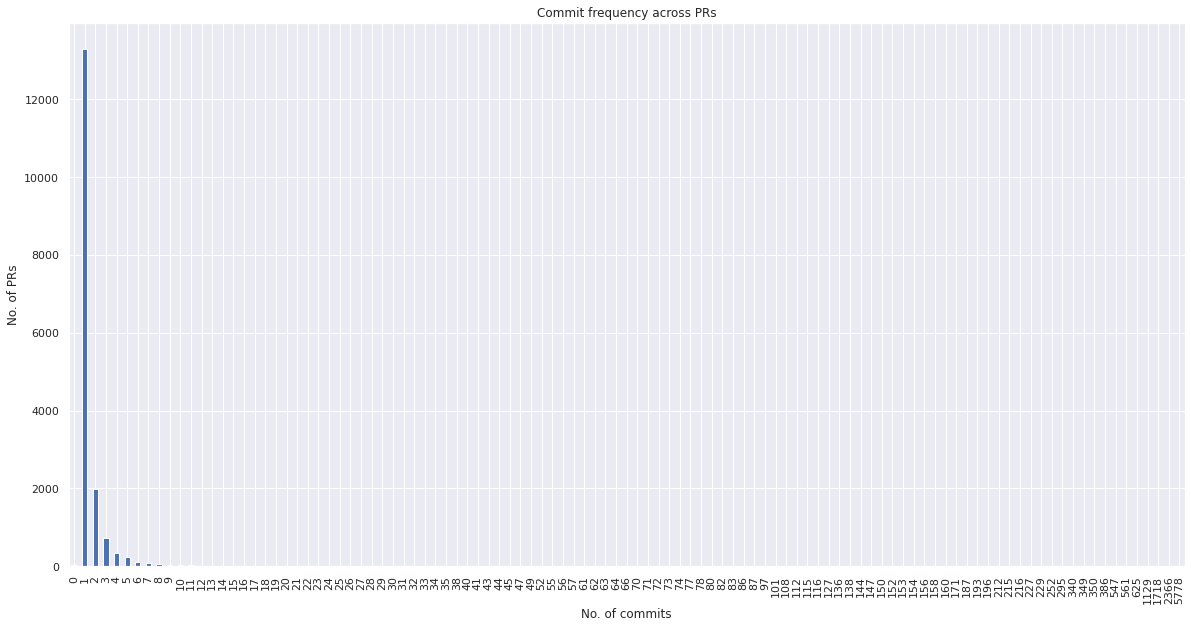
As we see above, in this dataset, there is not much variability in the commits number. Majority of the PRs (77%) have 1 commit, 11% have 2 commits and rest(12%) have more than 2 commits. We can break commits number down into 3 categorical variables, contains_1_commit, contains_2_commits, contains_3_or_more_commits. However, there might be some value in knowing whether a PR had 5 commits vs. 10 commits. So we will treat it as a numerical variable to begin with.
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | ... | body_size | title_word_counts_vec | is_reviewer | is_approver | num_prev_merged_prs | created_at_datetime | created_at_day | created_at_month | created_at_weekday | created_at_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Add link to GOPATH doc and fixup typo | None | 0 | jwforres | 1407759383 | 1407759502 | smarterclayton | 1407759502 | 1 | 1 | ... | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-11 08:16:23 | 11 | 8 | 0 | 8 |
| 2 | Add alpha API documentation | Merge of csrwng/oo-api-v3\n | 5 | csrwng | 1407834992 | 1407844533 | danmcp | 1407844533 | 1 | 54 | ... | 3 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-12 05:16:32 | 12 | 8 | 1 | 5 |
2 rows × 26 columns
Changed Files Number
Changed files is a numberical variable which captures the numer of files that were modified in the PR.
# convert changed_files_number to int
pr_df["changed_files_number"] = pr_df["changed_files_number"].astype("int")
pr_df.changed_files_number.value_counts()
1 6151
2 3046
3 1622
4 1035
5 669
...
409 1
11489 1
7556 1
8786 1
135 1
Name: changed_files_number, Length: 422, dtype: int64
pr_df.changed_files_number.value_counts().iloc[:50].sort_index(ascending=True).plot(
kind="bar"
)
plt.title("Frequency of changed files across PRs")
plt.xlabel("No. of changed files")
plt.ylabel("No. of PRs")
plt.show()
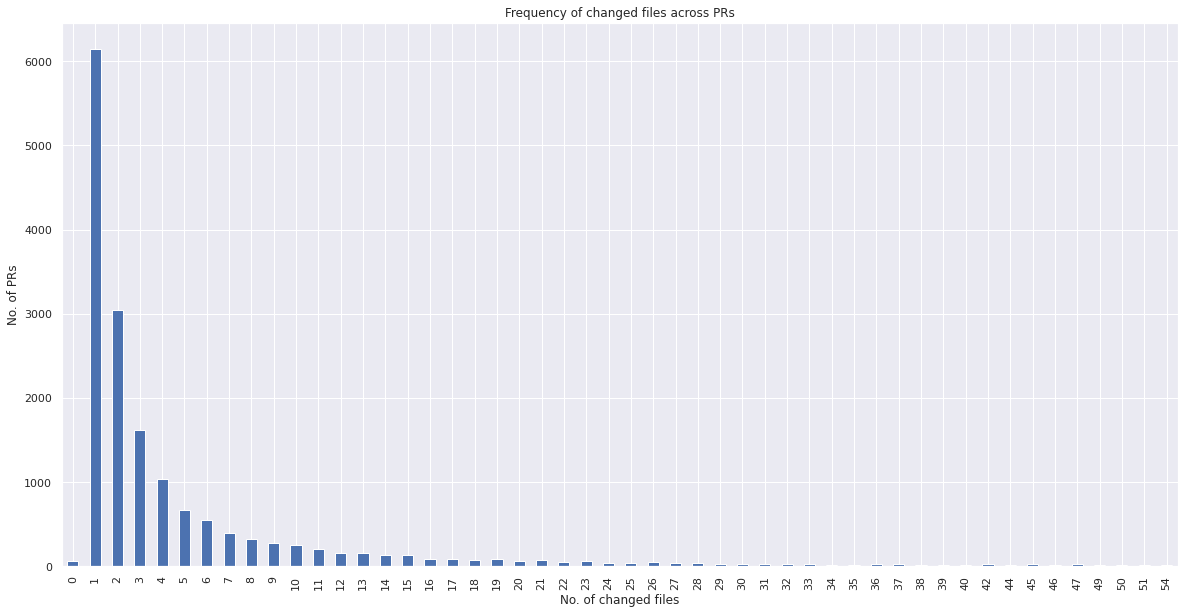
changed_files_number has more variability than the commits_number. We can incorporate this as a numerical feature.
Changed_files
changed_files is a list of the paths and filenames for every file changed by this PR. From changed_files, we know, for each PR, which file types were changed which can be encoded as a frequency vector. Also we know which directory the change is made in, so that can be encoded as a categorical variable.
pr_df.changed_files[7]
['pkg/template/example/project.json',
'pkg/template/generator.go',
'pkg/template/generator/from_url.go',
'pkg/template/generator/generator.go',
'pkg/template/generator/template.go',
'pkg/template/generator_test.go',
'pkg/template/service_links.go',
'pkg/template/service_links_test.go',
'pkg/template/types.go']
def filetype(filepath):
# if standard file extension, return file extension
if pathlib.Path(filepath).suffix:
return pathlib.Path(filepath).suffix
else:
# if single file at the root of repo
if "/" not in filepath:
# if a file like README/Dockerfile etc
if "." not in filepath:
return filepath
# if file not at root
else:
# get file name
file = filepath.rsplit("/", 1)[1]
if "." not in file:
return file
elif "." in file:
return "." + file.rsplit(".", 1)[1]
# get list of all file types that were modified across all openshift origin PRs
changed_files = list(pr_df["changed_files"])
all_changed_files = [filetype(filepath) for pr in changed_files for filepath in pr]
count = Counter(all_changed_files)
# save 100 most commonly occuring file extensions across PRs
top_fileextensions_freq = count.most_common(100)
top_fileextensions = [ext[0] for ext in top_fileextensions_freq]
top_fileextensions
['.go',
'.json',
'.1',
'.sh',
'.md',
'.yaml',
'BUILD',
'.proto',
'.yml',
'OWNERS',
'.html',
'.adoc',
'Dockerfile',
'.js',
'LICENSE',
'Makefile',
'.txt',
'.gitignore',
'oc',
'.pem',
'.s',
'.mod',
'openshift',
'.lock',
'.py',
'.sum',
'.conf',
'.bats',
'.png',
'.less',
'.pb',
'.feature',
'.xml',
'.tar',
'.crt',
'.spec',
'.template',
'AUTHORS',
'.service',
'.key',
'run',
'.mk',
'.scss',
'.golden',
'oadm',
'.rhel',
'.cert',
'result',
'.original',
'.h',
'.toml',
'.dat',
'.edited',
'MAINTAINERS',
'.svg',
'.in',
'.text',
'README',
'.cfg',
'.cc',
'NOTICE',
'.c',
'.bash',
'.pl',
'Vagrantfile',
'.chain',
'.centos7',
'CONTRIBUTORS',
'.gz',
'cert',
'key',
'.swift',
'.csr',
'.files_generated_oc',
'.sc',
'Readme',
'.tmpl',
'.empty',
'.insecure',
'.hcl',
'PATENTS',
'.files_generated_openshift',
'.sec',
None,
'VERSION',
'.css',
'.ini',
'Procfile',
'.ber',
'.env',
'.sls',
'.mailmap',
'.markdown',
'test',
'.com',
'.sysconfig',
'.yaml-merge-patch',
'.gitattributes',
'.java',
'.signature']
def file_type_freq(list_of_filepaths):
"""
For a given PR's list of changed files,
return a changed files frequency vector
( a vector which holds the frequency of
changed files of the type for every
file type in top_fileextensions )
"""
file_extensions = [filetype(f) for f in list_of_filepaths]
ext_dict = {key: 0 for key in top_fileextensions}
for f in file_extensions:
if f in ext_dict:
ext_dict[f] += 1
return list(ext_dict.values())
pr_df["changed_file_type_vec"] = pr_df["changed_files"].apply(
lambda x: file_type_freq(x)
)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | ... | title_word_counts_vec | is_reviewer | is_approver | num_prev_merged_prs | created_at_datetime | created_at_day | created_at_month | created_at_weekday | created_at_hour | changed_file_type_vec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Add link to GOPATH doc and fixup typo | None | 0 | jwforres | 1407759383 | 1407759502 | smarterclayton | 1407759502 | 1 | 1 | ... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-11 08:16:23 | 11 | 8 | 0 | 8 | [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 2 | Add alpha API documentation | Merge of csrwng/oo-api-v3\n | 5 | csrwng | 1407834992 | 1407844533 | danmcp | 1407844533 | 1 | 54 | ... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 2014-08-12 05:16:32 | 12 | 8 | 1 | 5 | [0, 47, 0, 0, 4, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,... |
2 rows × 27 columns
# We will also create a categorical variable for a modification in
# each of the directories present in the openshift origins repo
directories = [
".github",
"cmd",
"docs",
"e2echart",
"examples",
"hack",
"images",
"pkg",
"test",
"tools",
"vendor",
"root",
]
def directory_from_filepath(list_of_filepaths):
directories = []
for filepath in list_of_filepaths:
if "/" in filepath:
directories.append(filepath.split("/", 1)[0])
else:
directories.append("root")
return directories
# does the PR make a change to the given directory
pr_df["change_in_.github"] = pr_df["changed_files"].apply(
lambda x: 1 if ".github" in directory_from_filepath(x) else 0
)
pr_df["change_in_cmd"] = pr_df["changed_files"].apply(
lambda x: 1 if "cmd" in directory_from_filepath(x) else 0
)
pr_df["change_in_docs"] = pr_df["changed_files"].apply(
lambda x: 1 if "docs" in directory_from_filepath(x) else 0
)
pr_df["change_in_e2echart"] = pr_df["changed_files"].apply(
lambda x: 1 if "e2echart" in directory_from_filepath(x) else 0
)
pr_df["change_in_examples"] = pr_df["changed_files"].apply(
lambda x: 1 if "examples" in directory_from_filepath(x) else 0
)
pr_df["change_in_hack"] = pr_df["changed_files"].apply(
lambda x: 1 if "hack" in directory_from_filepath(x) else 0
)
pr_df["change_in_images"] = pr_df["changed_files"].apply(
lambda x: 1 if "images" in directory_from_filepath(x) else 0
)
pr_df["change_in_pkg"] = pr_df["changed_files"].apply(
lambda x: 1 if "pkg" in directory_from_filepath(x) else 0
)
pr_df["change_in_test"] = pr_df["changed_files"].apply(
lambda x: 1 if "test" in directory_from_filepath(x) else 0
)
pr_df["change_in_tools"] = pr_df["changed_files"].apply(
lambda x: 1 if "tools" in directory_from_filepath(x) else 0
)
pr_df["change_in_vendor"] = pr_df["changed_files"].apply(
lambda x: 1 if "vendor" in directory_from_filepath(x) else 0
)
pr_df["change_in_root"] = pr_df["changed_files"].apply(
lambda x: 1 if "root" in directory_from_filepath(x) else 0
)
pr_df.head(2)
| title | body | size | created_by | created_at | closed_at | closed_by | merged_at | commits_number | changed_files_number | ... | change_in_docs | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Add link to GOPATH doc and fixup typo | None | 0 | jwforres | 1407759383 | 1407759502 | smarterclayton | 1407759502 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | Add alpha API documentation | Merge of csrwng/oo-api-v3\n | 5 | csrwng | 1407834992 | 1407844533 | danmcp | 1407844533 | 1 | 54 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2 rows × 39 columns
We can see above that some PRs have 0 for all directory fields since the directory structure of the repo has changed over time and we are interested in only the latest directory structure.
# subset DataFrame to use as features
feature_df = pr_df[
[
"time_to_merge",
"changed_files_number",
"body_size",
"size",
"title_word_counts_vec",
"is_reviewer",
"is_approver",
"num_prev_merged_prs",
"created_at_day",
"created_at_month",
"created_at_weekday",
"created_at_hour",
"commits_number",
"changed_file_type_vec",
"change_in_.github",
"change_in_cmd",
"change_in_docs",
"change_in_e2echart",
"change_in_examples",
"change_in_hack",
"change_in_images",
"change_in_pkg",
"change_in_test",
"change_in_tools",
"change_in_vendor",
"change_in_root",
]
]
Add PR TTM Class Column¶
Lets split up the time to merge values into 10 discrete bins (as discussed above) to use as our prediction classes.
def get_ttm_class(ttm):
"""
Assign a ttm "class" / "category" / "bin" to the input numerical ttm value
E.g. if the time to merge was 1.5 hours, this function will return
class "0" which represents "merged in 0-3 hours"
"""
if ttm < 3:
return 0
elif ttm < 6:
return 1
elif ttm < 15:
return 2
elif ttm < 24:
return 3
elif ttm < 36:
return 4
elif ttm < 60:
return 5
elif ttm < 112:
return 6
elif ttm < 190:
return 7
elif ttm < 462:
return 8
else:
return 9
feature_df["ttm_class"] = (feature_df["time_to_merge"] / 3600).apply(get_ttm_class)
feature_df.head()
/home/kachau/.local/share/virtualenvs/ocp-ci-analysis-XKK7qNs8/lib/python3.8/site-packages/pandas/core/frame.py:3607: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._set_item(key, value)
| time_to_merge | changed_files_number | body_size | size | title_word_counts_vec | is_reviewer | is_approver | num_prev_merged_prs | created_at_day | created_at_month | ... | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 119.0 | 1 | 0 | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 11 | 8 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 9541.0 | 54 | 3 | 5 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 12 | 8 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 30435.0 | 1 | 0 | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | True | 0.0 | 12 | 8 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 |
| 4 | NaN | 1 | 0 | 3 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | True | 0.0 | 12 | 8 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9 |
| 5 | 20040.0 | 7 | 0 | 2 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | False | False | 0.0 | 12 | 8 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
5 rows × 27 columns
# visualize data points distribution across classes
feature_df["ttm_class"].hist()
plt.title("Distribution of PRs across TTM Labels")
plt.xlabel("Time to Merge Class")
plt.ylabel("Number of PRs")
plt.show()
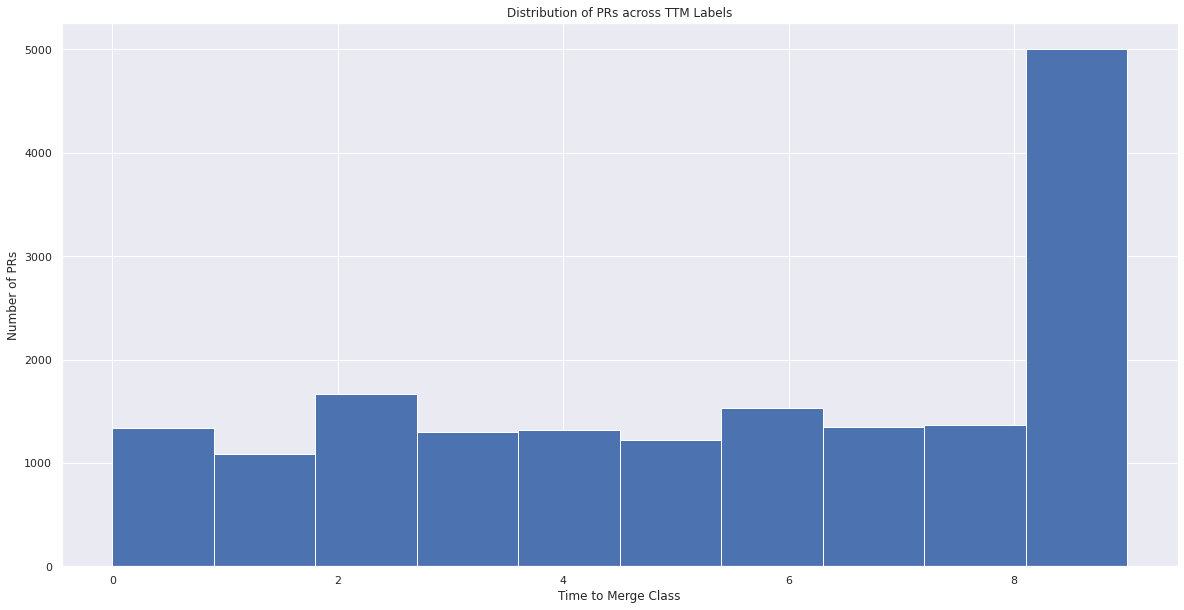
From the above graph, we can see that data is fairly uniformly distributed across all classes. At the same time, the class definitions are also easily interpretable by human experts. So this seems like a good setup for our classification task.
Let’s look at some pair-wise scatter plots of our data to see if there are any obvious correlations between our features.
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(2, 3)
ax1.scatter(pr_df["time_to_merge"], pr_df["body_size"])
ax1.set(xlabel="time to merge (seconds)", ylabel="body_size")
ax2.scatter(pr_df["time_to_merge"], pr_df["changed_files_number"])
ax2.set(xlabel="time to merge (seconds)", ylabel="changed_file_number")
ax3.scatter(pr_df["body_size"], pr_df["changed_files_number"])
ax3.set(xlabel="body size", ylabel="changed_file_number")
ax4.scatter(pr_df["size"], pr_df["changed_files_number"])
ax4.set(xlabel="size", ylabel="changed_file_number")
ax5.scatter(pr_df["size"], pr_df["time_to_merge"])
ax5.set(xlabel="size", ylabel="time_to_merge (seconds)")
ax6.scatter(pr_df["size"], pr_df["body_size"])
ax6.set(xlabel="size", ylabel="body_size")
fig.suptitle("Pair-Wise Scatter Plots")
plt.show()
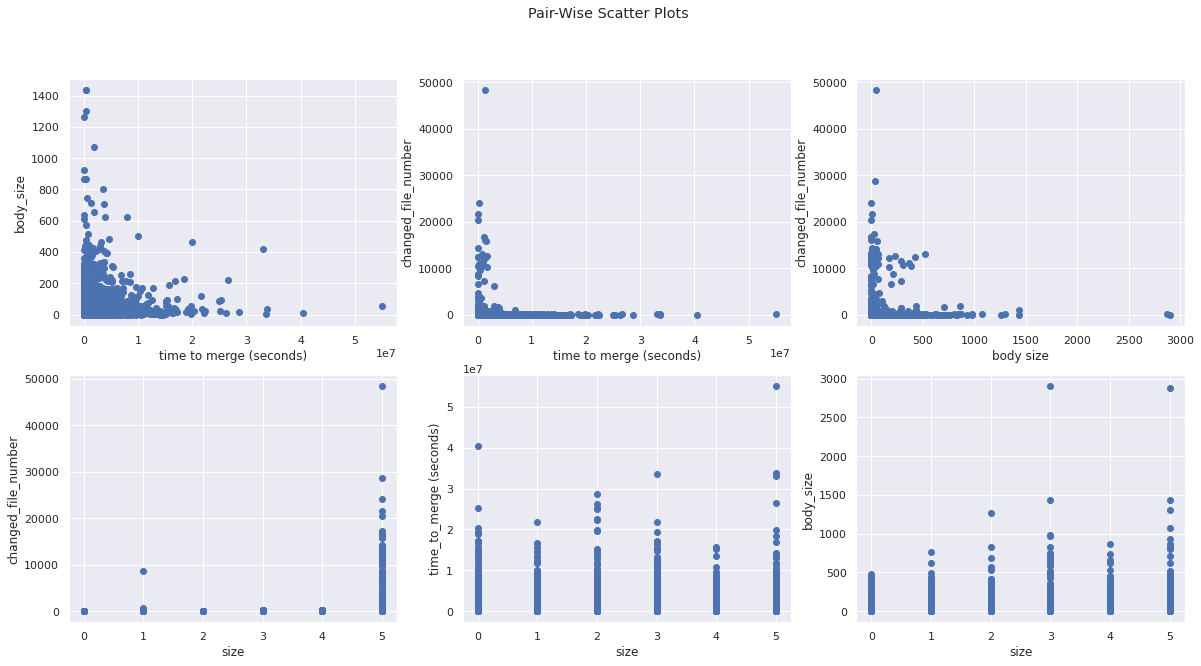
Its tough to see any meaningful correlations here. Despite this “L” shaped scatter plot the vast majority of the points are centered around (0,0) for the 3 pairs of features in the top row. There is some positive correlation seen between size and changed_file_number and size and body_size since the points appear to increase in the same direction. However, there does not appear to be any correlation seen between time_to_merge and size since the time_to_merge does not change even as size increases. Let’s calculate the correlation value for each pair of variables to see some actual numbers.
feature_df.describe()
| time_to_merge | changed_files_number | body_size | size | num_prev_merged_prs | created_at_day | created_at_month | created_at_weekday | created_at_hour | change_in_.github | ... | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1.353000e+04 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | ... | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 | 17183.000000 |
| mean | 6.801719e+05 | 68.379910 | 31.476867 | 1.839260 | 229.372752 | 15.549555 | 6.285166 | 2.111738 | 11.149916 | 0.000698 | ... | 0.000349 | 0.057091 | 0.124600 | 0.052959 | 0.511727 | 0.310947 | 0.014084 | 0.165396 | 0.085433 | 5.490194 |
| std | 1.848350e+06 | 885.774654 | 66.186398 | 1.593258 | 322.057245 | 8.733964 | 3.314577 | 1.542693 | 4.896269 | 0.026418 | ... | 0.018684 | 0.232024 | 0.330274 | 0.223959 | 0.499877 | 0.462895 | 0.117839 | 0.371548 | 0.279534 | 3.122439 |
| min | 3.000000e+00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 3.684875e+04 | 1.000000 | 3.000000 | 0.000000 | 19.000000 | 8.000000 | 3.000000 | 1.000000 | 8.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 3.000000 |
| 50% | 1.329870e+05 | 2.000000 | 14.000000 | 2.000000 | 87.000000 | 16.000000 | 6.000000 | 2.000000 | 11.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 6.000000 |
| 75% | 5.245955e+05 | 6.000000 | 36.000000 | 3.000000 | 289.000000 | 23.000000 | 9.000000 | 3.000000 | 14.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 9.000000 |
| max | 5.500529e+07 | 48386.000000 | 2899.000000 | 5.000000 | 1429.000000 | 31.000000 | 12.000000 | 6.000000 | 23.000000 | 1.000000 | ... | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 9.000000 |
8 rows × 22 columns
feature_df.corr()
| time_to_merge | changed_files_number | body_size | size | is_reviewer | is_approver | num_prev_merged_prs | created_at_day | created_at_month | created_at_weekday | ... | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| time_to_merge | 1.000000 | 0.004417 | 0.115515 | 0.117721 | -0.096736 | -0.102332 | -0.018753 | 0.004176 | 0.032199 | 0.008731 | ... | -0.003522 | -0.012264 | -0.008334 | 0.052237 | 0.006355 | 0.076274 | 0.011415 | 0.043098 | 0.013162 | 0.476700 |
| changed_files_number | 0.004417 | 1.000000 | 0.028810 | 0.144649 | 0.022640 | 0.038375 | -0.009828 | 0.012245 | -0.005152 | 0.004709 | ... | -0.001102 | 0.111870 | 0.120545 | 0.064884 | 0.017680 | 0.060799 | 0.297162 | 0.101134 | 0.143168 | 0.051084 |
| body_size | 0.115515 | 0.028810 | 1.000000 | 0.144166 | -0.046570 | -0.038743 | -0.014049 | 0.006723 | -0.010400 | 0.002409 | ... | 0.002783 | -0.035196 | 0.032767 | 0.034976 | 0.061880 | 0.086399 | 0.022451 | -0.016925 | -0.021174 | 0.140033 |
| size | 0.117721 | 0.144649 | 0.144166 | 1.000000 | 0.105623 | 0.101558 | 0.037782 | -0.006642 | 0.015888 | 0.007616 | ... | 0.017527 | 0.068593 | 0.162049 | -0.004033 | 0.261642 | 0.186384 | 0.122105 | 0.155420 | 0.116169 | 0.215049 |
| is_reviewer | -0.096736 | 0.022640 | -0.046570 | 0.105623 | 1.000000 | 0.834052 | 0.020988 | 0.021388 | -0.029631 | 0.066488 | ... | 0.015755 | 0.035323 | 0.097542 | -0.048938 | 0.063370 | 0.094600 | 0.032614 | 0.022099 | 0.007114 | -0.170191 |
| is_approver | -0.102332 | 0.038375 | -0.038743 | 0.101558 | 0.834052 | 1.000000 | 0.019125 | 0.018234 | -0.039108 | 0.037910 | ... | 0.011703 | 0.031128 | 0.096303 | -0.039032 | 0.055353 | 0.069149 | 0.033465 | 0.052098 | 0.010770 | -0.163709 |
| num_prev_merged_prs | -0.018753 | -0.009828 | -0.014049 | 0.037782 | 0.020988 | 0.019125 | 1.000000 | -0.016880 | -0.099440 | -0.001537 | ... | -0.013137 | -0.064679 | 0.027780 | -0.036691 | 0.013441 | 0.020455 | 0.005067 | -0.022072 | 0.002253 | -0.023095 |
| created_at_day | 0.004176 | 0.012245 | 0.006723 | -0.006642 | 0.021388 | 0.018234 | -0.016880 | 1.000000 | -0.054627 | -0.009093 | ... | 0.006314 | 0.008096 | -0.002877 | 0.003389 | -0.004855 | 0.015543 | 0.004129 | 0.005635 | -0.001067 | -0.001453 |
| created_at_month | 0.032199 | -0.005152 | -0.010400 | 0.015888 | -0.029631 | -0.039108 | -0.099440 | -0.054627 | 1.000000 | -0.026082 | ... | -0.014765 | 0.004333 | 0.012625 | -0.007644 | -0.025272 | 0.024974 | -0.010879 | 0.013779 | 0.030803 | 0.041676 |
| created_at_weekday | 0.008731 | 0.004709 | 0.002409 | 0.007616 | 0.066488 | 0.037910 | -0.001537 | -0.009093 | -0.026082 | 1.000000 | ... | -0.015488 | -0.003352 | 0.014366 | -0.000957 | -0.009926 | 0.015076 | 0.008951 | 0.002583 | 0.022130 | 0.023051 |
| created_at_hour | -0.025977 | -0.019019 | 0.027592 | 0.051971 | 0.147640 | 0.031878 | -0.012987 | -0.017174 | -0.035043 | 0.038989 | ... | 0.002609 | -0.000260 | 0.012274 | 0.027205 | 0.057279 | 0.000719 | -0.007896 | -0.042168 | -0.009146 | -0.016692 |
| change_in_.github | 0.009195 | 0.053228 | -0.005749 | 0.005433 | -0.011847 | -0.006324 | -0.011625 | -0.022347 | -0.002939 | 0.010938 | ... | -0.000494 | 0.021980 | 0.010038 | 0.023259 | -0.013842 | -0.003481 | 0.052926 | 0.000090 | 0.031326 | 0.017722 |
| change_in_cmd | 0.004834 | 0.215083 | 0.049231 | 0.132196 | 0.051883 | 0.050978 | 0.001879 | -0.004365 | 0.011268 | 0.006919 | ... | -0.003075 | 0.062840 | 0.122697 | 0.087603 | -0.008584 | 0.058967 | 0.159127 | 0.023538 | 0.123842 | 0.037454 |
| change_in_docs | 0.064161 | 0.108738 | 0.051589 | 0.129191 | -0.003584 | -0.004837 | -0.041726 | -0.002821 | 0.033794 | -0.001528 | ... | -0.003846 | 0.084050 | 0.075899 | 0.043485 | 0.076560 | 0.036913 | 0.108001 | -0.013050 | 0.038355 | 0.058807 |
| change_in_e2echart | -0.003522 | -0.001102 | 0.002783 | 0.017527 | 0.015755 | 0.011703 | -0.013137 | 0.006314 | -0.014765 | -0.015488 | ... | 1.000000 | -0.004599 | -0.007051 | -0.004420 | 0.005793 | 0.021092 | -0.002234 | 0.000064 | 0.016575 | 0.008040 |
| change_in_examples | -0.012264 | 0.111870 | -0.035196 | 0.068593 | 0.035323 | 0.031128 | -0.064679 | 0.008096 | 0.004333 | -0.003352 | ... | -0.004599 | 1.000000 | 0.085645 | 0.037013 | -0.000504 | 0.039537 | 0.115338 | -0.060256 | 0.031578 | 0.006035 |
| change_in_hack | -0.008334 | 0.120545 | 0.032767 | 0.162049 | 0.097542 | 0.096303 | 0.027780 | -0.002877 | 0.012625 | 0.014366 | ... | -0.007051 | 0.085645 | 1.000000 | 0.102772 | -0.037581 | 0.022941 | 0.152303 | -0.050327 | 0.163960 | -0.006236 |
| change_in_images | 0.052237 | 0.064884 | 0.034976 | -0.004033 | -0.048938 | -0.039032 | -0.036691 | 0.003389 | -0.007644 | -0.000957 | ... | -0.004420 | 0.037013 | 0.102772 | 1.000000 | -0.092366 | -0.047698 | 0.042306 | -0.053513 | 0.069962 | 0.057753 |
| change_in_pkg | 0.006355 | 0.017680 | 0.061880 | 0.261642 | 0.063370 | 0.055353 | 0.013441 | -0.004855 | -0.025272 | -0.009926 | ... | 0.005793 | -0.000504 | -0.037581 | -0.092366 | 1.000000 | -0.063423 | 0.025849 | -0.248599 | -0.150034 | 0.000512 |
| change_in_test | 0.076274 | 0.060799 | 0.086399 | 0.186384 | 0.094600 | 0.069149 | 0.020455 | 0.015543 | 0.024974 | 0.015076 | ... | 0.021092 | 0.039537 | 0.022941 | -0.047698 | -0.063423 | 1.000000 | 0.059485 | -0.136954 | -0.052837 | 0.102073 |
| change_in_tools | 0.011415 | 0.297162 | 0.022451 | 0.122105 | 0.032614 | 0.033465 | 0.005067 | 0.004129 | -0.010879 | 0.008951 | ... | -0.002234 | 0.115338 | 0.152303 | 0.042306 | 0.025849 | 0.059485 | 1.000000 | 0.049149 | 0.083617 | 0.034858 |
| change_in_vendor | 0.043098 | 0.101134 | -0.016925 | 0.155420 | 0.022099 | 0.052098 | -0.022072 | 0.005635 | 0.013779 | 0.002583 | ... | 0.000064 | -0.060256 | -0.050327 | -0.053513 | -0.248599 | -0.136954 | 0.049149 | 1.000000 | 0.111065 | 0.113722 |
| change_in_root | 0.013162 | 0.143168 | -0.021174 | 0.116169 | 0.007114 | 0.010770 | 0.002253 | -0.001067 | 0.030803 | 0.022130 | ... | 0.016575 | 0.031578 | 0.163960 | 0.069962 | -0.150034 | -0.052837 | 0.083617 | 0.111065 | 1.000000 | 0.028099 |
| ttm_class | 0.476700 | 0.051084 | 0.140033 | 0.215049 | -0.170191 | -0.163709 | -0.023095 | -0.001453 | 0.041676 | 0.023051 | ... | 0.008040 | 0.006035 | -0.006236 | 0.057753 | 0.000512 | 0.102073 | 0.034858 | 0.113722 | 0.028099 | 1.000000 |
24 rows × 24 columns
From the correlation values, above we do not see any strong correlation between time to merge and other variables. We can see that body_size and size are most correlated with time_to_merge, but 0.11 is a rather weak correlation value. This is good if we are going to use these as input features to a model, but not so good if we wanted to try and predict one value from the other two. In the next section, we will calculate feature importance scores for our features to select the most important features for our model.
# NOTE: rows where the `time_to_merge` value is nan represent the PR's that did not get merged
# since predicting time to close/reject is out of the scope of this exploration
# we will drop those rows from further analysus
feature_df = feature_df[~feature_df["time_to_merge"].isna()]
feature_df.shape
(13530, 27)
Evaluating Feature Importances¶
Categorical Features¶
First, lets try to determine what categorical featuers are powerful influencers for time to merge of a PR
# feature selection helper function
def select_features(x, y, func):
fs = SelectKBest(score_func=func, k="all")
fs.fit(x, y)
x_fs = fs.transform(x)
return x_fs, fs
selected_features = []
cat_df = feature_df[
[
"size",
"is_reviewer",
"is_approver",
"created_at_day",
"created_at_month",
"created_at_weekday",
"created_at_hour",
"change_in_.github",
"change_in_cmd",
"change_in_docs",
"change_in_e2echart",
"change_in_examples",
"change_in_hack",
"change_in_images",
"change_in_pkg",
"change_in_test",
"change_in_tools",
"change_in_vendor",
"change_in_root",
"ttm_class",
]
]
cat_df.head()
| size | is_reviewer | is_approver | created_at_day | created_at_month | created_at_weekday | created_at_hour | change_in_.github | change_in_cmd | change_in_docs | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | False | False | 11 | 8 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 5 | False | False | 12 | 8 | 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | False | True | 12 | 8 | 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 |
| 5 | 2 | False | False | 12 | 8 | 1 | 8 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 6 | 0 | False | False | 12 | 8 | 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
# split into input (X) and output (y) variables
X = cat_df.drop(columns=["ttm_class"])
y = cat_df["ttm_class"]
# rank using mutual_info_classif
X_fs, fs = select_features(X, y, mutual_info_classif)
for i in range(len(fs.scores_)):
print("Feature %s: %f" % (X.columns[i], fs.scores_[i]))
Feature size: 0.044264
Feature is_reviewer: 0.000000
Feature is_approver: 0.010190
Feature created_at_day: 0.000000
Feature created_at_month: 0.005857
Feature created_at_weekday: 0.034658
Feature created_at_hour: 0.009211
Feature change_in_.github: 0.000000
Feature change_in_cmd: 0.005738
Feature change_in_docs: 0.005591
Feature change_in_e2echart: 0.000000
Feature change_in_examples: 0.000000
Feature change_in_hack: 0.000000
Feature change_in_images: 0.005793
Feature change_in_pkg: 0.000000
Feature change_in_test: 0.008334
Feature change_in_tools: 0.000000
Feature change_in_vendor: 0.013850
Feature change_in_root: 0.010854
# visualize scores of all features
sns.barplot(x=X.columns, y=fs.scores_)
plt.title("Feature importance scores for Mutual Information Statistic")
plt.xticks(rotation=60)
plt.xlabel("Features")
plt.ylabel("Scores")
plt.show()
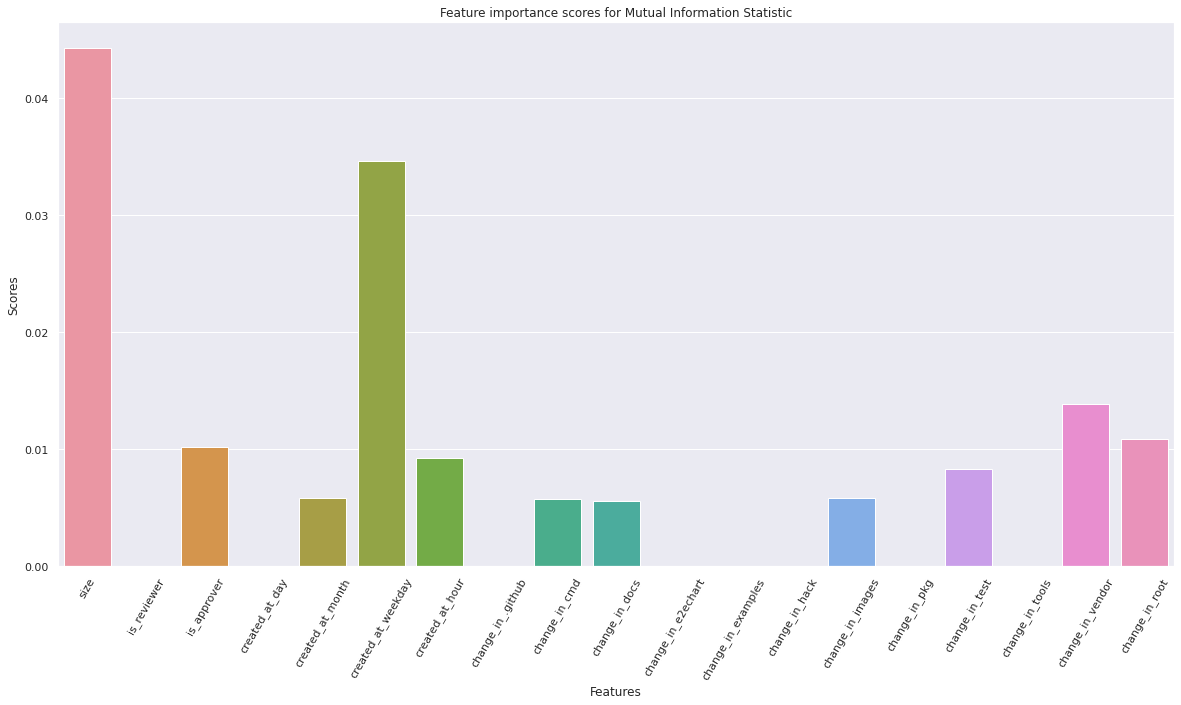
# Lets get a list of the top 10 feature indices based on Mutual Info Stat feature scores
top_mis = fs.scores_.argsort()[-10:][::-1]
# rank using chi_sq
X_fs, fs = select_features(X, y, chi2)
for i in range(len(fs.scores_)):
print("Feature %s: %f" % (X.columns[i], fs.scores_[i]))
Feature size: 1366.621250
Feature is_reviewer: 236.344523
Feature is_approver: 230.186533
Feature created_at_day: 142.625122
Feature created_at_month: 79.020129
Feature created_at_weekday: 304.529657
Feature created_at_hour: 443.231756
Feature change_in_.github: 11.115579
Feature change_in_cmd: 13.926693
Feature change_in_docs: 103.058228
Feature change_in_e2echart: 6.738201
Feature change_in_examples: 15.022310
Feature change_in_hack: 9.801802
Feature change_in_images: 52.527167
Feature change_in_pkg: 72.741790
Feature change_in_test: 210.102073
Feature change_in_tools: 21.982763
Feature change_in_vendor: 141.668045
Feature change_in_root: 56.153303
# visualize scores of all features
sns.barplot(x=X.columns, y=fs.scores_)
plt.title("Feature importance scores for Chi Squared")
plt.xticks(rotation=60)
plt.xlabel("Features")
plt.ylabel("Scores")
plt.show()
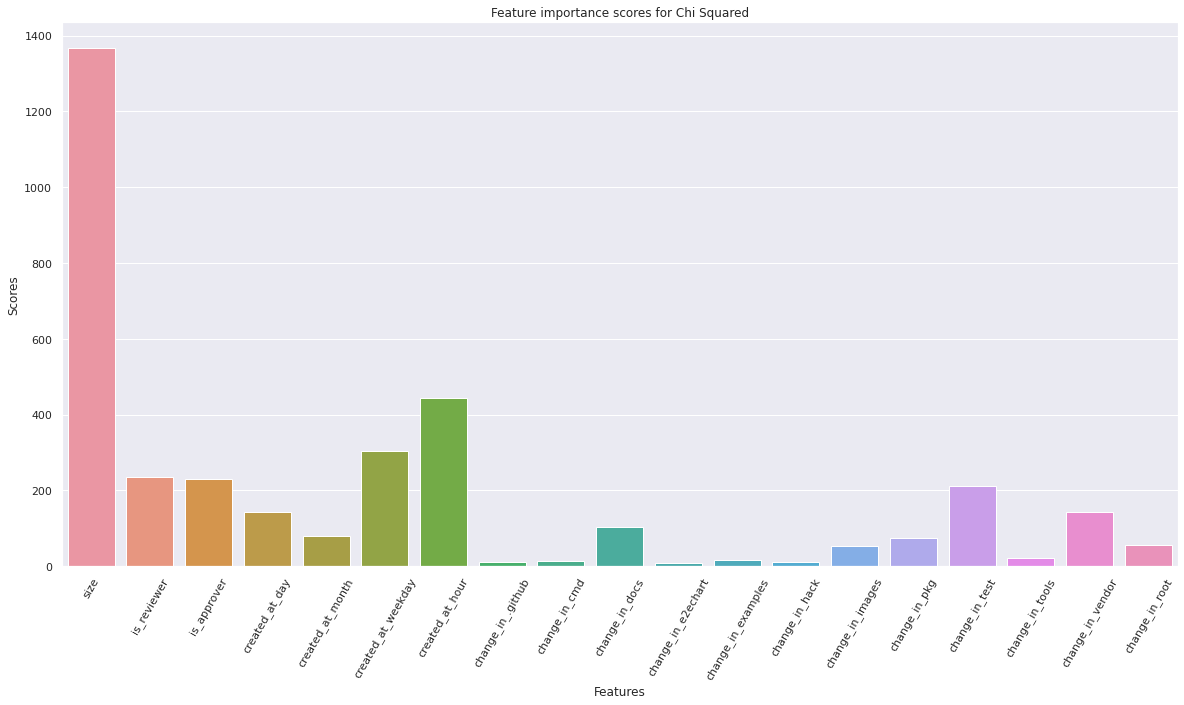
# Lets get a list of the top 10 feature indices based on Chi Sq feature scores
top_chi2 = fs.scores_.argsort()[-10:][::-1]
Let’s get a Union of the top 10 features derived from features based on both scores of both Mutual Info Statistic and Chi Squared
union = set(top_mis).union(set(top_chi2))
print(len(union))
union
13
{0, 1, 2, 3, 4, 5, 6, 8, 9, 13, 15, 17, 18}
We now have the top 12 features based on their feature importance scores. We can eliminate the remaining 7 features from the categorical features which have low feature importance scores for both Mutual Info Statistic and Chi Squared
cat_df.head()
| size | is_reviewer | is_approver | created_at_day | created_at_month | created_at_weekday | created_at_hour | change_in_.github | change_in_cmd | change_in_docs | change_in_e2echart | change_in_examples | change_in_hack | change_in_images | change_in_pkg | change_in_test | change_in_tools | change_in_vendor | change_in_root | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | False | False | 11 | 8 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 5 | False | False | 12 | 8 | 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | False | True | 12 | 8 | 1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 |
| 5 | 2 | False | False | 12 | 8 | 1 | 8 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 6 | 0 | False | False | 12 | 8 | 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
# update list of features to keep for training
selected_features += [
"size",
"is_reviewer",
"is_approver",
"created_at_day",
"created_at_month",
"created_at_weekday",
"created_at_hour",
"change_in_.github",
"change_in_docs",
"change_in_pkg",
"change_in_test",
"change_in_vendor",
"change_in_root",
]
Numerical Features¶
Now, lets try to determine what numerical featuers are powerful influencers for time to merge of a PR
numerical_df = feature_df[
[
"changed_files_number",
"body_size",
"num_prev_merged_prs",
"commits_number",
"ttm_class",
]
]
numerical_df.head()
| changed_files_number | body_size | num_prev_merged_prs | commits_number | ttm_class | |
|---|---|---|---|---|---|
| 1 | 1 | 0 | 0.0 | 1 | 0 |
| 2 | 54 | 3 | 0.0 | 1 | 0 |
| 3 | 1 | 0 | 0.0 | 1 | 2 |
| 5 | 7 | 0 | 0.0 | 1 | 1 |
| 6 | 1 | 42 | 0.0 | 2 | 1 |
# split into input features and target
X = numerical_df.drop(columns=["ttm_class"])
y = numerical_df["ttm_class"]
# create k best feature selector object based on mutual information
numerical_feats_mi, k_best_selector_mi = select_features(
X,
y,
partial(
mutual_info_classif,
discrete_features=False,
random_state=42,
n_neighbors=3,
),
)
# visualize the MI scores of all features
sns.barplot(x=X.columns, y=k_best_selector_mi.scores_)
plt.title("Feature importance based on Mutual Information")
plt.xticks(rotation=60)
plt.xlabel("Features")
plt.ylabel("Scores")
plt.show()
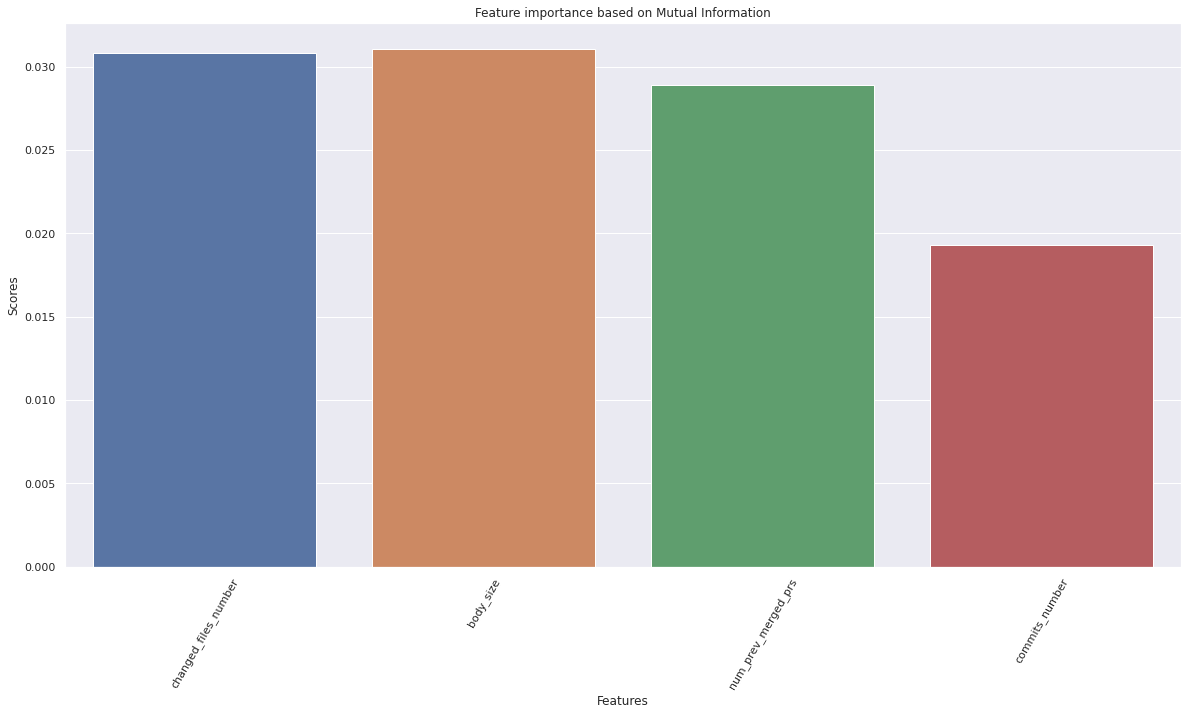
# create k best feature selector object based on anova f statistic
numerical_feats_f, k_best_selector_f = select_features(
X,
y,
f_classif,
)
# visualize the f stat scores and pvalues of all features
fig, axes = plt.subplots(2, 1, sharex=True)
fig.suptitle("Feature importance based on ANOVA F stat")
sns.barplot(x=X.columns, y=k_best_selector_f.scores_, ax=axes[0])
sns.barplot(x=X.columns, y=k_best_selector_f.pvalues_, ax=axes[1])
plt.xticks(rotation=60)
plt.xlabel("Features")
axes[0].set_ylabel("Scores")
axes[1].set_ylabel("p-values")
plt.show()
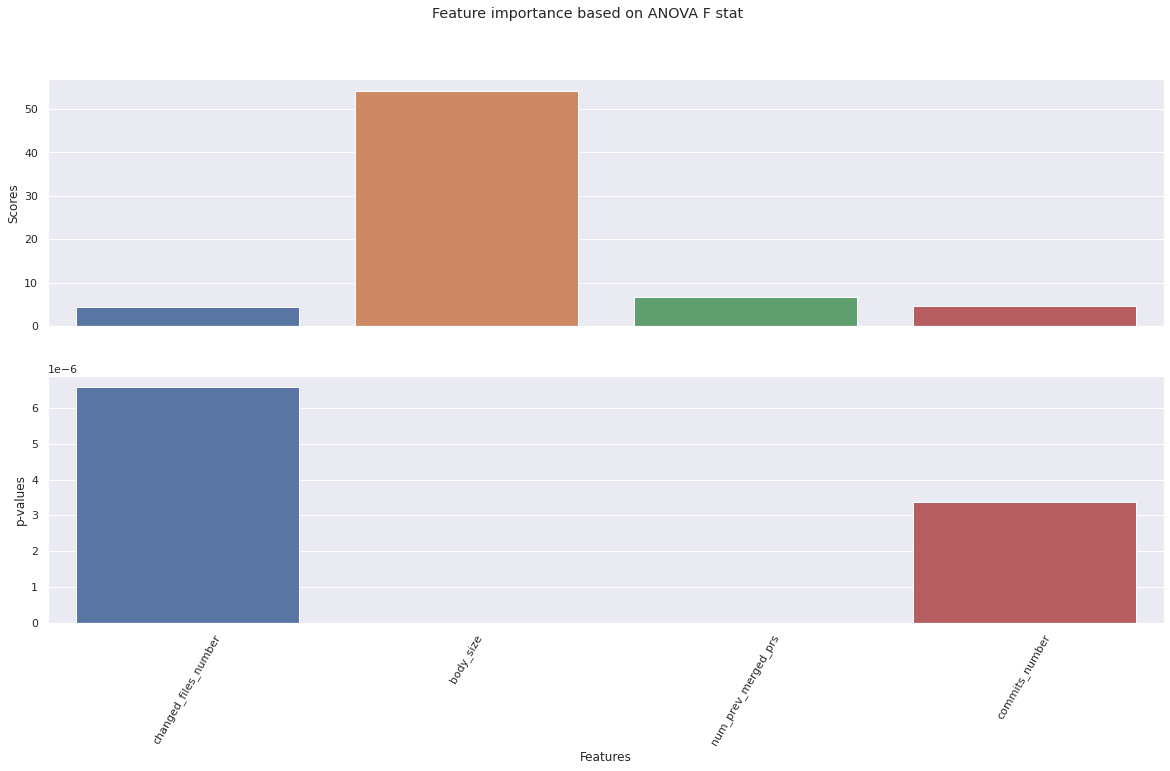
From the above cells, we can see that all numerical featuers seem to have similar importances based on the mutual information criterion. Based on ANOVA F statistic, all but one (body_size) of them have similar scores. Since there are only 4 of these features, we will keep all of them in our features dataframe.
# update list of features to keep for training
selected_features += [
"changed_files_number",
"body_size",
"num_prev_merged_prs",
"commits_number",
]
Count Vector Type Features¶
Finally, lets determine the most important features from the count vector type columns.
# explode the list column so that there is 1 column representing frequency of each file type
filetype_df = pd.DataFrame(feature_df.changed_file_type_vec.to_list())
filetype_df.index = feature_df.index
filetype_df.columns = [f"filetype_{f}" for f in top_fileextensions]
# compute correlation with ttm
corr = filetype_df.corrwith(feature_df["ttm_class"])
corr.sort_values(ascending=False)
filetype_openshift 0.117514
filetype_oc 0.114041
filetype_oadm 0.067057
filetype_.files_generated_oc 0.057013
filetype_.files_generated_openshift 0.054466
...
filetype_.in -0.000853
filetype_None -0.005314
filetype_.scss -0.005494
filetype_OWNERS -0.009672
filetype_Vagrantfile -0.020005
Length: 100, dtype: float64
corr[corr.abs() > 0.01]
filetype_.go 0.045924
filetype_.json 0.022556
filetype_.1 0.023154
filetype_.sh 0.039563
filetype_.md 0.026897
...
filetype_test 0.016087
filetype_.sysconfig 0.019626
filetype_.yaml-merge-patch 0.012821
filetype_.gitattributes 0.010586
filetype_.signature 0.017807
Length: 64, dtype: float64
# update list of features to keep for training
# take everything that has more than 0.01 correlation magnitude
keep_cols = corr[corr.abs() > 0.01].index.tolist()
selected_features += keep_cols
# only keep the relevant columns now
filetype_df = filetype_df[keep_cols]
# explode the list column so that there is 1 column representing frequency of each word
title_wordcount_df = pd.DataFrame(feature_df.title_word_counts_vec.to_list())
title_wordcount_df.index = feature_df.index
title_wordcount_df.columns = [f"title_wordcount_{w}" for w in unique_words]
# compute correlation with ttm
corr = title_wordcount_df.corrwith(feature_df["ttm_class"])
corr = corr.dropna()
corr.sort_values(ascending=False)
title_wordcount_bug 0.108769
title_wordcount_oc 0.056590
title_wordcount_support 0.053857
title_wordcount_router 0.052250
title_wordcount_add 0.049126
...
title_wordcount_revert -0.045302
title_wordcount_disable -0.049128
title_wordcount_fix -0.054172
title_wordcount_publishing -0.057387
title_wordcount_bump -0.070319
Length: 7033, dtype: float64
corr[corr.abs() > 0.04]
title_wordcount_add 0.049126
title_wordcount_bug 0.108769
title_wordcount_bump -0.070319
title_wordcount_diagnostics 0.041924
title_wordcount_disable -0.049128
title_wordcount_fix -0.054172
title_wordcount_haproxy 0.041492
title_wordcount_oc 0.056590
title_wordcount_publishing -0.057387
title_wordcount_revert -0.045302
title_wordcount_router 0.052250
title_wordcount_sh -0.040293
title_wordcount_staging -0.044244
title_wordcount_support 0.053857
title_wordcount_travis -0.043066
dtype: float64
# update list of features to keep for training
# take everything that has more than 0.01 correlation magnitude
keep_cols = corr[corr.abs() > 0.04].index.tolist()
selected_features += keep_cols
title_wordcount_df = title_wordcount_df[keep_cols]
Using various feature importance scores such as chi-squared, mutual information statistic, correlation values, we have selected the most relevant features amongst all of our features.
selected_features
['size',
'is_reviewer',
'is_approver',
'created_at_day',
'created_at_month',
'created_at_weekday',
'created_at_hour',
'change_in_.github',
'change_in_docs',
'change_in_pkg',
'change_in_test',
'change_in_vendor',
'change_in_root',
'changed_files_number',
'body_size',
'num_prev_merged_prs',
'commits_number',
'filetype_.go',
'filetype_.json',
'filetype_.1',
'filetype_.sh',
'filetype_.md',
'filetype_.yaml',
'filetype_BUILD',
'filetype_.proto',
'filetype_.yml',
'filetype_.html',
'filetype_.adoc',
'filetype_Dockerfile',
'filetype_LICENSE',
'filetype_Makefile',
'filetype_.txt',
'filetype_.gitignore',
'filetype_oc',
'filetype_.s',
'filetype_.mod',
'filetype_openshift',
'filetype_.sum',
'filetype_.conf',
'filetype_.bats',
'filetype_.feature',
'filetype_.xml',
'filetype_.crt',
'filetype_.spec',
'filetype_.template',
'filetype_AUTHORS',
'filetype_.service',
'filetype_.key',
'filetype_run',
'filetype_.mk',
'filetype_oadm',
'filetype_.rhel',
'filetype_.cert',
'filetype_result',
'filetype_MAINTAINERS',
'filetype_README',
'filetype_NOTICE',
'filetype_.c',
'filetype_.bash',
'filetype_.pl',
'filetype_Vagrantfile',
'filetype_.centos7',
'filetype_CONTRIBUTORS',
'filetype_.gz',
'filetype_cert',
'filetype_key',
'filetype_.files_generated_oc',
'filetype_Readme',
'filetype_.empty',
'filetype_PATENTS',
'filetype_.files_generated_openshift',
'filetype_.sec',
'filetype_VERSION',
'filetype_.ini',
'filetype_.mailmap',
'filetype_.markdown',
'filetype_test',
'filetype_.sysconfig',
'filetype_.yaml-merge-patch',
'filetype_.gitattributes',
'filetype_.signature',
'title_wordcount_add',
'title_wordcount_bug',
'title_wordcount_bump',
'title_wordcount_diagnostics',
'title_wordcount_disable',
'title_wordcount_fix',
'title_wordcount_haproxy',
'title_wordcount_oc',
'title_wordcount_publishing',
'title_wordcount_revert',
'title_wordcount_router',
'title_wordcount_sh',
'title_wordcount_staging',
'title_wordcount_support',
'title_wordcount_travis']
Save Feature Engineered Dataset¶
# join all types of features
ttm_dataset = pd.concat(
[feature_df, filetype_df, title_wordcount_df], axis=1, ignore_index=False
)
# keep only the selected features and the prediction label
ttm_dataset = ttm_dataset[selected_features + ["ttm_class"]]
ttm_dataset.head()
| size | is_reviewer | is_approver | created_at_day | created_at_month | created_at_weekday | created_at_hour | change_in_.github | change_in_docs | change_in_pkg | ... | title_wordcount_haproxy | title_wordcount_oc | title_wordcount_publishing | title_wordcount_revert | title_wordcount_router | title_wordcount_sh | title_wordcount_staging | title_wordcount_support | title_wordcount_travis | ttm_class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | False | False | 11 | 8 | 0 | 8 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 5 | False | False | 12 | 8 | 1 | 5 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | False | True | 12 | 8 | 1 | 5 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| 5 | 2 | False | False | 12 | 8 | 1 | 8 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 6 | 0 | False | False | 12 | 8 | 1 | 9 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 97 columns
Save results to Ceph or locally¶
Using the helper function to save the data frame in a parquet format on the Ceph bucket if we are running in automation, and locally if not.
## Sanity check to see if the dataset is the same
if REMOTE:
cc = CephCommunication(s3_endpoint_url, s3_access_key, s3_secret_key, s3_bucket)
try:
cc.upload_to_ceph(
ttm_dataset,
s3_path,
"ttm_dataset.parquet",
)
except ValueError as ve:
print(ve)
print("Files already uploaded to S3")
else:
save_to_disk(
ttm_dataset,
OUTPUT_DATA_PATH,
"ttm_dataset.parquet",
)
Conlusion¶
This notebook walked through how to access the relevant PR data for the OpenShift Origin project we whish to analyze along with the rest of the related CI data in this project. We also outlined what is contained in each record and provided a quick demonstration of how to convert the mixed data types into numerical values for statistical analysis and eventually machine learning.
We have also engineered some possible features which can be used to predict time to merge of a PR.
time_to_merge: time taken to merge a PR in seconds, this is feature we will try to predict
changed_files_number: integer indicating the number of files changed, this is an available column
body_size: integer indicating the number of words in the body of the PR, derived from body
size: integer corresponding to a categorical label generated by GitHub which summerizes the size of the changes made to the code base
title_word_counts_vec: vector or list indicating how many times each word appeared in the title
is_reviewer: categorical variable indicating whether the creator of the PR is a reviewer, derived from created_by and additional repo data
is_approver: categorical variable indicating whether the creator of the PR is an approver, derived from created_by and additional repo data
num_prev_merged_prs: categorical variable indicating whether the creator of the PR has previously created PRs, derived from created_by
created_at_day: categorical variable indicating the day of month the PR has been created, derived from created_at
created_at_month: categorical variable indicating the month of the year that the PR has been created, derived from created_at
created_at_weekday: categorical variable indicating the day of the week the PR has been created, derived from created_at
created_at_hour: categorical variable indicating the hour of the day the PR has been created, derived from created_at
commits_number: integer indicating the number of commiyts in the PR
changed_file_type_vec: vector or list consisting of number of files changed for the top 100 most frequently occuring datatypes, derived from changed_files
change_in_.github: categorical variable indicating whether the PR changes a file in the .github directory, derived from changed_files
change_in_cmd: categorical variable indicating whether the PR changes a file in the cmd directory, derived from changed_files
change_in_docs: categorical variable indicating whether the PR changes a file in the docs directory, derived from changed_files
change_in_e2echart: categorical variable indicating whether the PR changes a file in the e2echart directory, derived from changed_files
change_in_examples: categorical variable indicating whether the PR changes a file in the examples directory, derived from changed_files
change_in_hack: categorical variable indicating whether the PR changes a file in the hack directory, derived from changed_files
change_in_images: categorical variable indicating whether the PR changes a file in the images directory, derived from changed_files
change_in_pkg: categorical variable indicating whether the PR changes a file in the pkg directory, derived from changed_files
change_in_test: categorical variable indicating whether the PR changes a file in the test directory, derived from changed_files
change_in_tools: categorical variable indicating whether the PR changes a file in the tools directory, derived from changed_files
change_in_vendor: categorical variable indicating whether the PR changes a file in the vendor directory, derived from changed_files
change_in_root: categorical variable indicating whether the PR changes a file in the root directory of the repo, derived from changed_files
As next steps, we will train a classifier to predict time to merge of a PR using the features.