Predicting Time to Merge of a Pull Request¶
One of the machine learning explorations within the OpenShift CI Analysis project is predicting time to merge of a pull request (see this issue for more details). In a previous notebook we showed how to access the PR data for the openshift/origin repo, and then performed initial data analysis as well as feature engineering on it. Furthermore, we also split the time_to_merge values for the PRs into the following 10 discrete, equally populated bins, so that this task becomes a classification problem:
Class 0 : < 3 hrs
Class 1 : < 6 hrs
Class 2 : < 15 hrs
Class 3 : < 24 hrs / 1 day
Class 4 : < 36 hrs / 1.5 days
Class 5 : < 60 hrs / 2.5 days
Class 6 : < 112 hrs / ~4.5 days
Class 7 : < 190 hrs / ~8 days
Class 8 : < 462 hrs / ~19 days
Class 9: > 462 hrs
In this notebook, we will train a machine learning model to classify the time_to_merge values for PRs into one of these 10 bins (or “classes”), using the features engineered from the raw PR data.
import os
import sys
import boto3
import warnings
import tempfile
from io import BytesIO
from copy import deepcopy
from joblib import dump, load
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_selection import RFE
from sklearn.preprocessing import PowerTransformer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from dotenv import load_dotenv, find_dotenv
metric_template_path = "../data-sources/TestGrid/metrics"
if metric_template_path not in sys.path:
sys.path.insert(1, metric_template_path)
from ipynb.fs.defs.metric_template import ( # noqa: E402
CephCommunication, # noqa: E402
) # noqa: E402
warnings.filterwarnings("ignore")
load_dotenv(find_dotenv())
True
## CEPH Bucket variables
## Create a .env file on your local with the correct configs,
s3_endpoint_url = os.getenv("S3_ENDPOINT")
s3_access_key = os.getenv("S3_ACCESS_KEY")
s3_secret_key = os.getenv("S3_SECRET_KEY")
s3_bucket = os.getenv("S3_BUCKET")
s3_path = "github"
REMOTE = os.getenv("REMOTE")
INPUT_DATA_PATH = "../../../data/processed/github"
if REMOTE:
cc = CephCommunication(s3_endpoint_url, s3_access_key, s3_secret_key, s3_bucket)
ttm_dataset = cc.read_from_ceph(s3_path, "ttm_dataset.parquet")
else:
print(
"The ttm_dataset.parquet file is not included in the ocp-ci-analysis github repo."
)
print(
"Please set REMOTE=1 in the .env file and read this data from the S3 bucket instead."
)
# extract X and y from dataset
X = ttm_dataset.drop(columns="ttm_class")
y = ttm_dataset["ttm_class"]
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# upload X_test and y_test to S3 bucket for testing / running sanity check on the model inference service
ret = cc.upload_to_ceph(X_test, s3_path, "X_test.parquet")
print(ret["ResponseMetadata"]["HTTPStatusCode"])
ret = cc.upload_to_ceph(y_test.to_frame(), s3_path, "y_test.parquet")
print(ret["ResponseMetadata"]["HTTPStatusCode"])
200
200
# convert from pandas series to lists to avoid warnings during training
y_train = y_train.to_list()
y_test = y_test.to_list()
Scale data¶
# lets apply a yeo johnson transform to try to make the data more gaussian
scaler = PowerTransformer()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Define Training and Evaluation Pipeline¶
Here, we will define a function to train a given classifier on the training set and then evaluate it on the test set.
def train_evaluate_classifier(clf, xtrain, ytrain, xtest, ytest):
# Train our classifier
clf.fit(xtrain, ytrain)
# Make predictions
preds = clf.predict(xtest)
# View classification report
print(classification_report(ytest, preds))
# Plot confusion matrix heatmap
plt.figure(figsize=(16, 12))
cf_matrix = confusion_matrix(ytest, preds)
group_counts = ["{0:0.0f}\n".format(value) for value in cf_matrix.flatten()]
group_percentages = [
"{0:.2%}".format(value) for value in cf_matrix.flatten() / np.sum(cf_matrix)
]
box_labels = [
f"{v1}{v2}".strip() for v1, v2 in zip(group_counts, group_percentages)
]
box_labels = np.asarray(box_labels).reshape(cf_matrix.shape[0], cf_matrix.shape[1])
sns.heatmap(cf_matrix, cmap="OrRd", annot=box_labels, fmt="")
plt.xlabel("Predicted TTM Label")
plt.ylabel("True TTM Label")
plt.title("Confusion Matrix Heatmap")
Define Models and Parameters¶
Next, we will define and initialize the classifiers that we will be exploring for the time-to-merge prediction task.
Gaussian Naive Bayes¶
# Initialize classifier
gnb = GaussianNB()
SVM¶
# Initialize classifier
svc = SVC(random_state=42)
Random Forest¶
# Initialize classifier
rf = RandomForestClassifier(
n_estimators=200,
max_features=0.75,
random_state=42,
n_jobs=-1,
)
XGBoost¶
# Initialize classifier
xgbc = XGBClassifier(
n_estimators=125,
learning_rate=0.1,
random_state=42,
verbosity=1,
n_jobs=-1,
)
Compare Model Results¶
Finally, we will run the train all of the classifiers defined above and evaluate their performance.
Train using all features¶
First, lets train the classifiers using all the engineered features as input.
train_evaluate_classifier(gnb, X_train_scaled, y_train, X_test_scaled, y_test)
precision recall f1-score support
0 0.18 0.05 0.08 249
1 0.08 0.95 0.15 217
2 0.00 0.00 0.00 364
3 0.12 0.01 0.02 240
4 0.00 0.00 0.00 275
5 0.00 0.00 0.00 236
6 0.00 0.00 0.00 333
7 0.25 0.01 0.01 270
8 0.22 0.01 0.01 260
9 0.22 0.07 0.10 262
accuracy 0.09 2706
macro avg 0.11 0.11 0.04 2706
weighted avg 0.10 0.09 0.03 2706
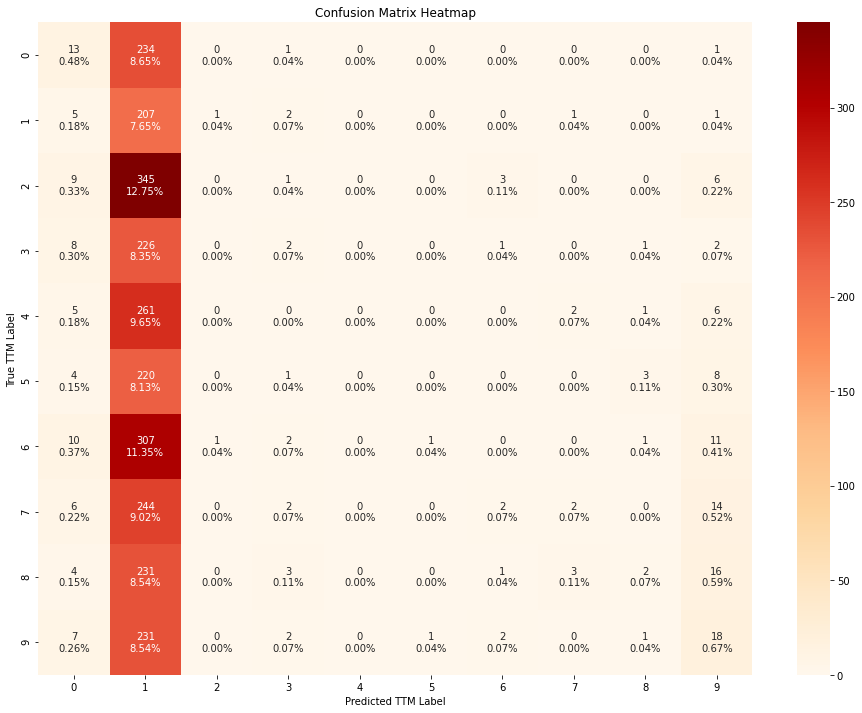
train_evaluate_classifier(svc, X_train_scaled, y_train, X_test_scaled, y_test)
precision recall f1-score support
0 0.26 0.48 0.33 249
1 0.67 0.01 0.02 217
2 0.20 0.37 0.26 364
3 0.12 0.10 0.11 240
4 0.18 0.08 0.11 275
5 0.11 0.03 0.05 236
6 0.20 0.26 0.22 333
7 0.14 0.05 0.07 270
8 0.18 0.22 0.20 260
9 0.22 0.27 0.24 262
accuracy 0.20 2706
macro avg 0.23 0.19 0.16 2706
weighted avg 0.22 0.20 0.17 2706
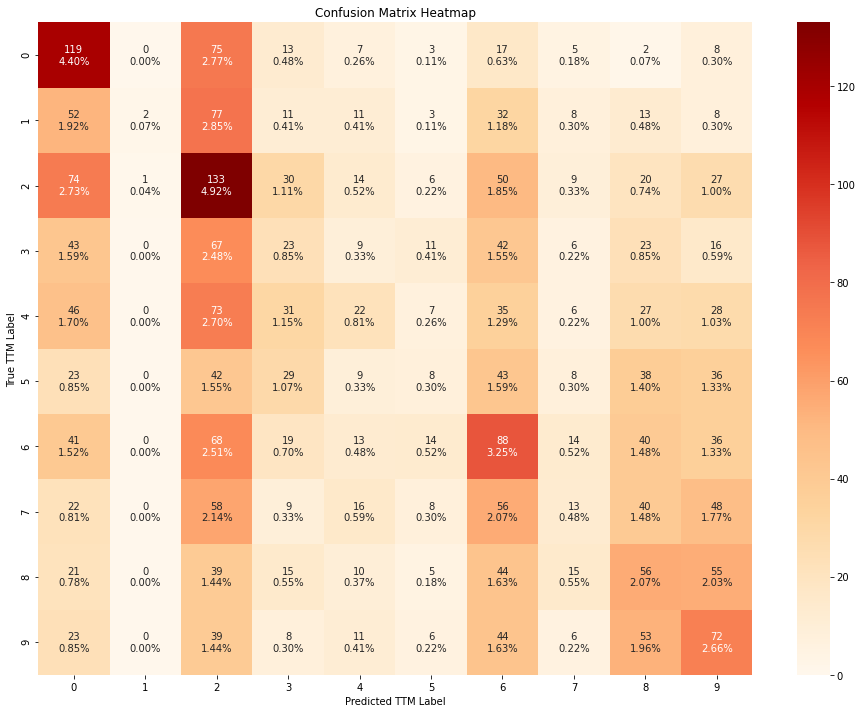
train_evaluate_classifier(rf, X_train_scaled, y_train, X_test_scaled, y_test)
precision recall f1-score support
0 0.31 0.42 0.36 249
1 0.14 0.10 0.12 217
2 0.23 0.27 0.25 364
3 0.15 0.17 0.16 240
4 0.13 0.10 0.11 275
5 0.14 0.10 0.12 236
6 0.23 0.23 0.23 333
7 0.16 0.14 0.15 270
8 0.18 0.17 0.17 260
9 0.23 0.28 0.25 262
accuracy 0.20 2706
macro avg 0.19 0.20 0.19 2706
weighted avg 0.19 0.20 0.20 2706
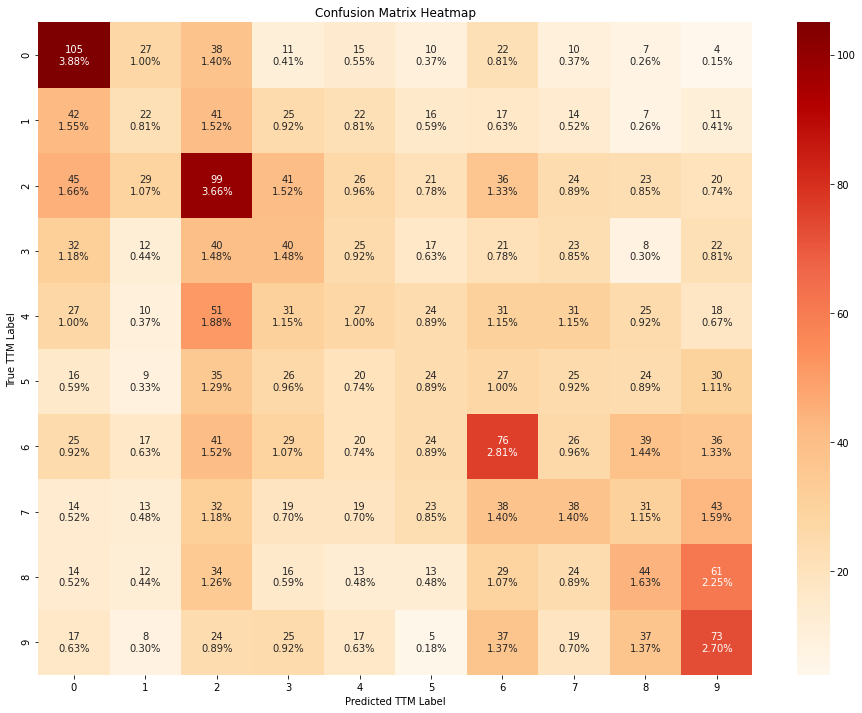
train_evaluate_classifier(xgbc, X_train_scaled, y_train, X_test_scaled, y_test)
[21:44:45] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
precision recall f1-score support
0 0.28 0.43 0.34 249
1 0.09 0.05 0.06 217
2 0.22 0.27 0.25 364
3 0.16 0.17 0.16 240
4 0.18 0.11 0.14 275
5 0.18 0.13 0.15 236
6 0.25 0.30 0.28 333
7 0.17 0.13 0.14 270
8 0.20 0.21 0.21 260
9 0.26 0.31 0.28 262
accuracy 0.22 2706
macro avg 0.20 0.21 0.20 2706
weighted avg 0.20 0.22 0.21 2706
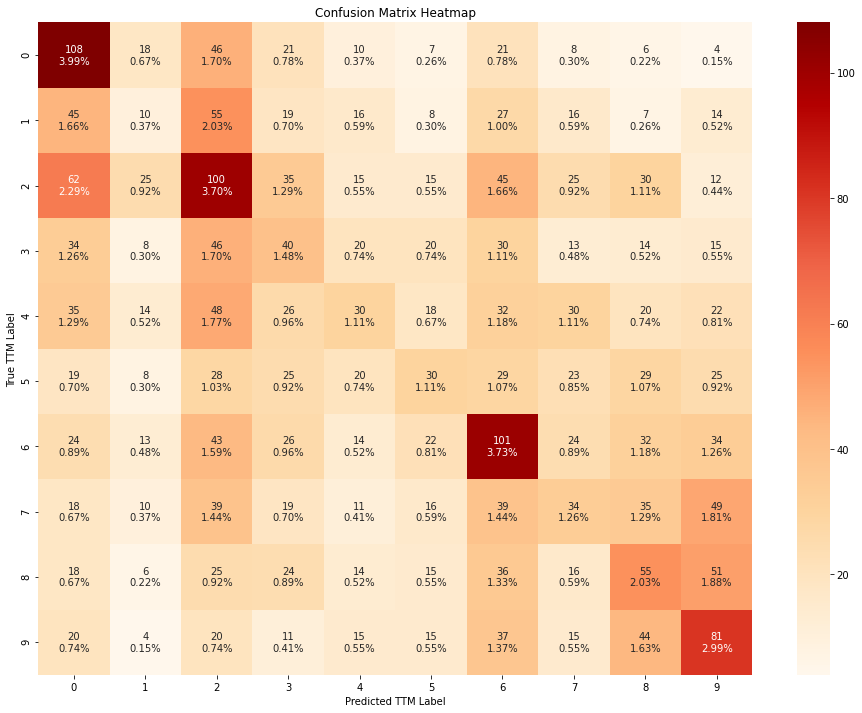
Based on the results above, it seems like all the models outperform a random guess. The XGBoost classifier outperforms all others, followed closely by random forest. Furthermore, the Naive bayes and SVM models seem to be heavily biased towards a few classes. On the contrary, the random forest andthe XGBoost models seem to be less biased and have mis-classifications within the bordering classes amongst the ordinal classes.
Note that for model deployment (which is the eventual goal), we will also need to include any scaler or preprocessor objects. This is because the input to the inference service will be raw unscaled data. We plan to address this issue by using sklearn.Pipeline object to package the preprocessor(s) and model as one “combined” model. Since an XGBoost model baked into an sklearn.Pipeline object might be complicated to serve on a seldon sklearn server, and since random forest performs almost as well as xgboost, we will save the random forest as the “best” model here. In the step below, we create a copy of the model so that we can save it to S3 later on and use it for model deployment.
# create a clone (create a copy of the object with the learned weights)
selected_model = deepcopy(rf)
# sanity check
print(classification_report(y_test, selected_model.predict(X_test_scaled)))
precision recall f1-score support
0 0.31 0.42 0.36 249
1 0.14 0.10 0.12 217
2 0.23 0.27 0.25 364
3 0.15 0.17 0.16 240
4 0.13 0.10 0.11 275
5 0.14 0.10 0.12 236
6 0.23 0.23 0.23 333
7 0.16 0.14 0.15 270
8 0.18 0.17 0.17 260
9 0.23 0.28 0.25 262
accuracy 0.20 2706
macro avg 0.19 0.20 0.19 2706
weighted avg 0.19 0.20 0.20 2706
Train using pruned features¶
In the previous notebook we performed some feature engineering and pruned the number of features down to 96. However, it might be possible that further pruning the features based on the importances given to them by the models yields more generalizable and accurate models. So in this section, we will explore using Recursive Feature Elimination (RFE) to rank the features in terms of their importance, and recursively select the best subsets to train our models with.
# use the xgboost classifier as the base estimator since it had the highest f1
selector = RFE(xgbc, n_features_to_select=20, step=5)
selector = selector.fit(X_train_scaled, y_train)
[21:44:59] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:45:17] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:45:31] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:45:47] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:46:03] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:46:16] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:46:28] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:46:40] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:46:51] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:02] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:12] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:21] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:30] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:38] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:45] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:53] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
[21:47:59] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
# No of top features to select
top = 20
ranks = selector.ranking_
ranks
array([ 1, 1, 1, 3, 3, 1, 1, 15, 1, 2, 1, 1, 4, 3, 1, 1, 1,
1, 6, 5, 6, 7, 5, 7, 7, 7, 1, 5, 6, 9, 5, 9, 4, 1,
11, 12, 1, 13, 8, 15, 16, 12, 10, 5, 1, 11, 9, 17, 17, 8, 8,
10, 15, 17, 10, 13, 10, 17, 10, 14, 9, 11, 14, 14, 17, 15, 9, 8,
16, 14, 13, 15, 12, 12, 16, 7, 13, 12, 16, 14, 16, 4, 1, 1, 11,
4, 3, 8, 3, 11, 1, 1, 6, 6, 4, 13])
cols = X_train.columns.to_numpy()
cols
array(['size', 'is_reviewer', 'is_approver', 'created_at_day',
'created_at_month', 'created_at_weekday', 'created_at_hour',
'change_in_.github', 'change_in_docs', 'change_in_pkg',
'change_in_test', 'change_in_vendor', 'change_in_root',
'changed_files_number', 'body_size', 'num_prev_merged_prs',
'commits_number', 'filetype_.go', 'filetype_.json', 'filetype_.1',
'filetype_.sh', 'filetype_.md', 'filetype_.yaml', 'filetype_BUILD',
'filetype_.proto', 'filetype_.yml', 'filetype_.html',
'filetype_.adoc', 'filetype_Dockerfile', 'filetype_LICENSE',
'filetype_Makefile', 'filetype_.txt', 'filetype_.gitignore',
'filetype_oc', 'filetype_.s', 'filetype_.mod',
'filetype_openshift', 'filetype_.sum', 'filetype_.conf',
'filetype_.bats', 'filetype_.feature', 'filetype_.xml',
'filetype_.crt', 'filetype_.spec', 'filetype_.template',
'filetype_AUTHORS', 'filetype_.service', 'filetype_.key',
'filetype_run', 'filetype_.mk', 'filetype_oadm', 'filetype_.rhel',
'filetype_.cert', 'filetype_result', 'filetype_MAINTAINERS',
'filetype_README', 'filetype_NOTICE', 'filetype_.c',
'filetype_.bash', 'filetype_.pl', 'filetype_Vagrantfile',
'filetype_.centos7', 'filetype_CONTRIBUTORS', 'filetype_.gz',
'filetype_cert', 'filetype_key', 'filetype_.files_generated_oc',
'filetype_Readme', 'filetype_.empty', 'filetype_PATENTS',
'filetype_.files_generated_openshift', 'filetype_.sec',
'filetype_VERSION', 'filetype_.ini', 'filetype_.mailmap',
'filetype_.markdown', 'filetype_test', 'filetype_.sysconfig',
'filetype_.yaml-merge-patch', 'filetype_.gitattributes',
'filetype_.signature', 'title_wordcount_add',
'title_wordcount_bug', 'title_wordcount_bump',
'title_wordcount_diagnostics', 'title_wordcount_disable',
'title_wordcount_fix', 'title_wordcount_haproxy',
'title_wordcount_oc', 'title_wordcount_publishing',
'title_wordcount_revert', 'title_wordcount_router',
'title_wordcount_sh', 'title_wordcount_staging',
'title_wordcount_support', 'title_wordcount_travis'], dtype=object)
indices_by_ranks = ranks.argsort()
indices_by_ranks
array([ 0, 26, 36, 91, 90, 44, 17, 16, 15, 33, 83, 14, 10, 1, 8, 82, 6,
2, 11, 5, 9, 3, 4, 88, 86, 13, 85, 94, 81, 32, 12, 30, 27, 19,
22, 43, 93, 28, 18, 92, 20, 21, 23, 24, 75, 25, 87, 49, 50, 67, 38,
31, 60, 66, 29, 46, 54, 56, 58, 51, 42, 89, 84, 61, 34, 45, 35, 41,
73, 77, 72, 76, 95, 70, 37, 55, 62, 63, 79, 59, 69, 65, 71, 52, 39,
7, 80, 68, 40, 74, 78, 64, 57, 53, 48, 47])
sorted_ranks = ranks[indices_by_ranks]
sorted_ranks
array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 5, 5, 5,
5, 5, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8,
9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 11, 11, 11, 11, 11, 12, 12,
12, 12, 12, 13, 13, 13, 13, 13, 14, 14, 14, 14, 14, 15, 15, 15, 15,
15, 16, 16, 16, 16, 16, 17, 17, 17, 17, 17])
cols_by_rank = cols[indices_by_ranks]
cols_by_rank[:top]
array(['size', 'filetype_.html', 'filetype_openshift',
'title_wordcount_router', 'title_wordcount_revert',
'filetype_.template', 'filetype_.go', 'commits_number',
'num_prev_merged_prs', 'filetype_oc', 'title_wordcount_bump',
'body_size', 'change_in_test', 'is_reviewer', 'change_in_docs',
'title_wordcount_bug', 'created_at_hour', 'is_approver',
'change_in_vendor', 'created_at_weekday'], dtype=object)
# prune the training set
X_train_scaled_pruned = X_train_scaled[:, selector.support_]
X_test_scaled_pruned = X_test_scaled[:, selector.support_]
train_evaluate_classifier(
gnb, X_train_scaled_pruned, y_train, X_test_scaled_pruned, y_test
)
precision recall f1-score support
0 0.17 0.54 0.26 249
1 0.10 0.35 0.16 217
2 0.26 0.06 0.10 364
3 0.12 0.12 0.12 240
4 0.28 0.02 0.03 275
5 0.14 0.03 0.05 236
6 0.19 0.14 0.16 333
7 0.00 0.00 0.00 270
8 0.20 0.15 0.17 260
9 0.22 0.26 0.24 262
accuracy 0.16 2706
macro avg 0.17 0.17 0.13 2706
weighted avg 0.17 0.16 0.13 2706
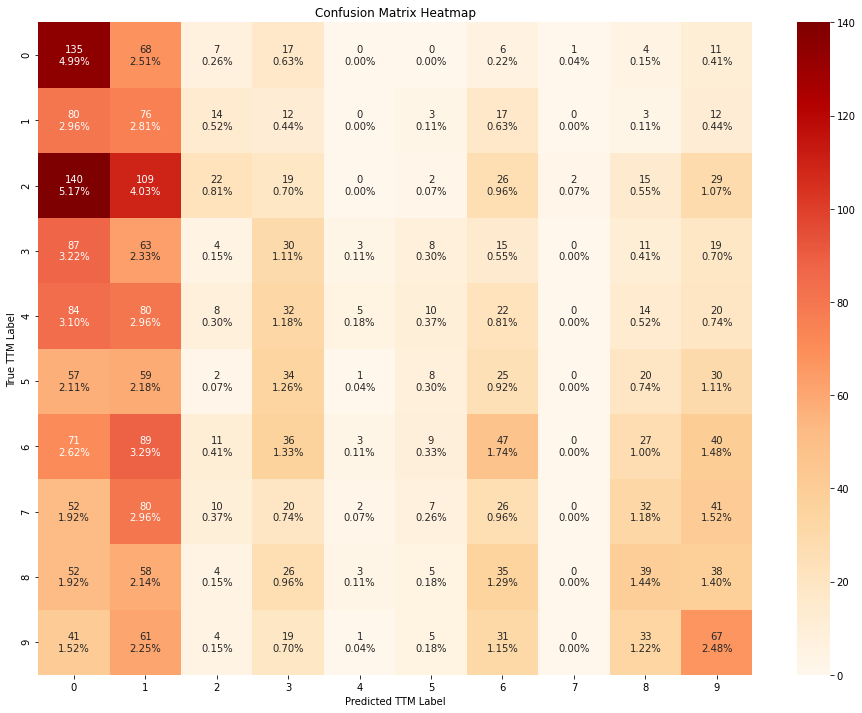
train_evaluate_classifier(
svc, X_train_scaled_pruned, y_train, X_test_scaled_pruned, y_test
)
precision recall f1-score support
0 0.24 0.47 0.32 249
1 0.40 0.03 0.05 217
2 0.20 0.32 0.24 364
3 0.11 0.11 0.11 240
4 0.16 0.08 0.11 275
5 0.12 0.05 0.07 236
6 0.24 0.24 0.24 333
7 0.18 0.12 0.14 270
8 0.14 0.15 0.14 260
9 0.21 0.29 0.25 262
accuracy 0.19 2706
macro avg 0.20 0.19 0.17 2706
weighted avg 0.20 0.19 0.17 2706
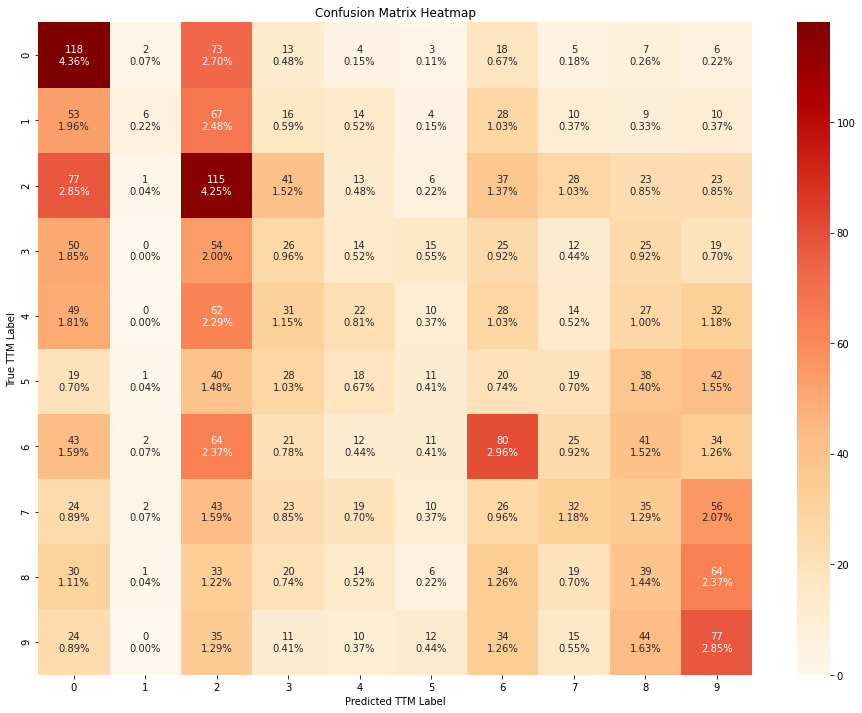
train_evaluate_classifier(
rf, X_train_scaled_pruned, y_train, X_test_scaled_pruned, y_test
)
precision recall f1-score support
0 0.25 0.31 0.28 249
1 0.16 0.14 0.15 217
2 0.21 0.22 0.21 364
3 0.13 0.14 0.14 240
4 0.13 0.11 0.12 275
5 0.16 0.14 0.15 236
6 0.20 0.20 0.20 333
7 0.18 0.16 0.17 270
8 0.17 0.17 0.17 260
9 0.22 0.26 0.24 262
accuracy 0.19 2706
macro avg 0.18 0.19 0.18 2706
weighted avg 0.18 0.19 0.18 2706
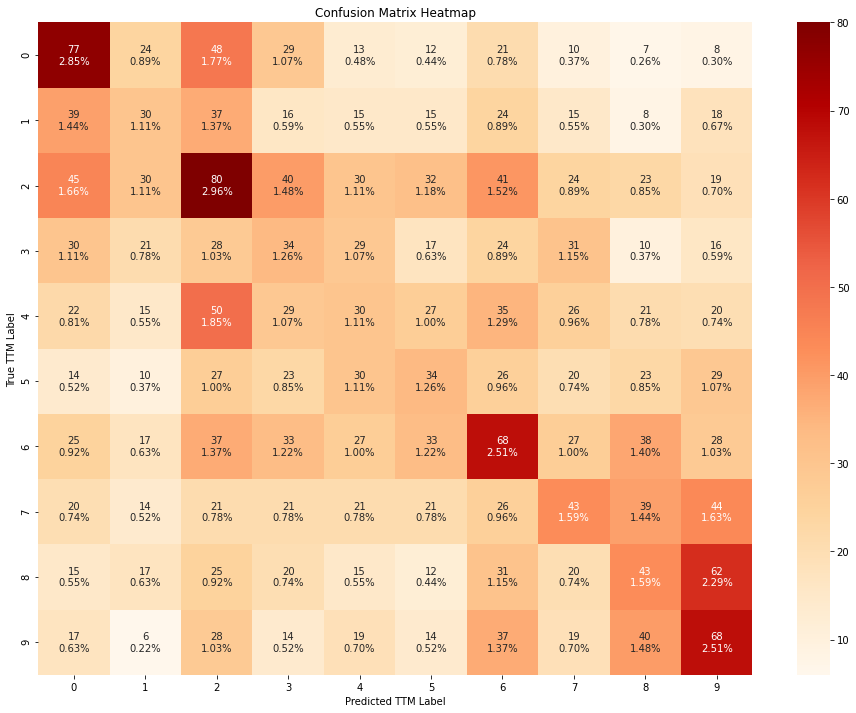
train_evaluate_classifier(
xgbc, X_train_scaled_pruned, y_train, X_test_scaled_pruned, y_test
)
[21:48:18] WARNING: ../src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
precision recall f1-score support
0 0.23 0.39 0.29 249
1 0.12 0.06 0.07 217
2 0.20 0.24 0.22 364
3 0.17 0.17 0.17 240
4 0.10 0.07 0.08 275
5 0.17 0.12 0.14 236
6 0.26 0.32 0.28 333
7 0.16 0.13 0.14 270
8 0.14 0.13 0.14 260
9 0.24 0.26 0.25 262
accuracy 0.20 2706
macro avg 0.18 0.19 0.18 2706
weighted avg 0.18 0.20 0.18 2706
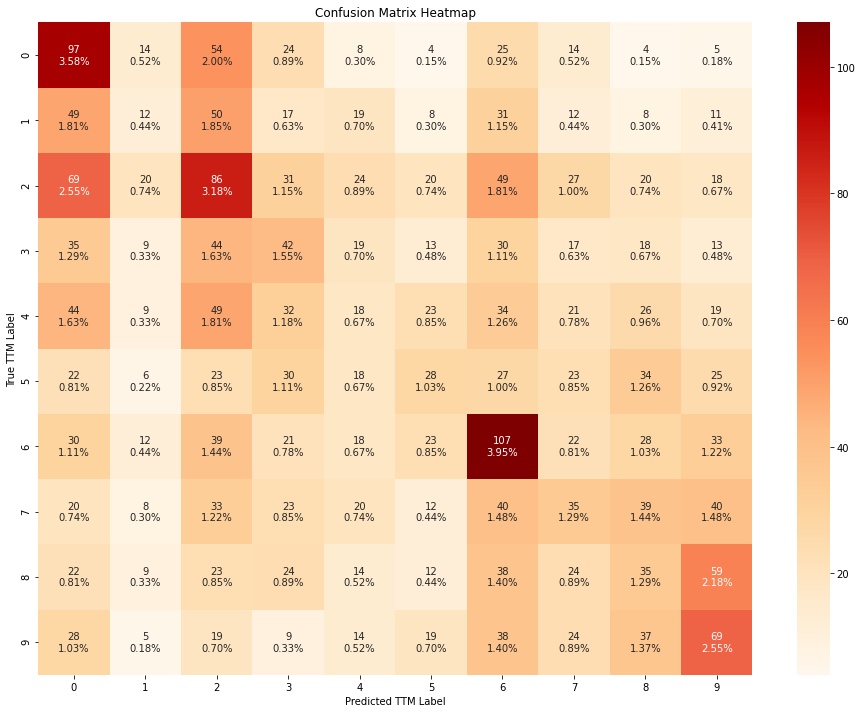
From the confusion matrices above, we can conclude that the models perform slightly better when trained using all the features, instead of using only the RFE-pruned subset.
Create sklearn Pipeline¶
Here, we will create an sklearn pipeline consisting of 2 steps, scaling of the input features and the classifier itself. We will then save this Pipeline as a model.joblib file on S3 for serving the model pipeline using the Seldon Sklearn Server.
pipe = Pipeline(steps=[("scale", scaler), ("rf", selected_model)])
Write Model to S3¶
key = "github/ttm-model/pipeline"
filename = "model.joblib"
s3_resource = boto3.resource(
"s3",
endpoint_url=s3_endpoint_url,
aws_access_key_id=s3_access_key,
aws_secret_access_key=s3_secret_key,
)
with tempfile.TemporaryFile() as fp:
dump(pipe, fp)
fp.seek(0)
s3_obj = s3_resource.Object(s3_bucket, f"{key}/{filename}")
s3_obj.put(Body=fp.read())
## Sanity Check
buffer = BytesIO()
s3_object = s3_resource.Object(s3_bucket, f"{key}/{filename}")
s3_object.download_fileobj(buffer)
model = load(buffer)
model
Pipeline(steps=[('scale', PowerTransformer()),
('rf',
RandomForestClassifier(max_features=0.75, n_estimators=200,
n_jobs=-1, random_state=42))])
preds = model.predict(X_test)
print(classification_report(y_test, preds))
precision recall f1-score support
0 0.31 0.42 0.36 249
1 0.14 0.10 0.12 217
2 0.23 0.27 0.25 364
3 0.15 0.17 0.16 240
4 0.13 0.10 0.11 275
5 0.14 0.10 0.12 236
6 0.23 0.23 0.23 333
7 0.16 0.14 0.15 270
8 0.18 0.17 0.17 260
9 0.23 0.28 0.25 262
accuracy 0.20 2706
macro avg 0.19 0.20 0.19 2706
weighted avg 0.19 0.20 0.20 2706
Conclusion¶
In this notebook, we explored various vanilla classifiers, namely, Naive Bayes, SVM, Random Forests, and XGBoost. The XGBoost classifier was able to predict the classes with a weighted average f1 score of 0.21 an accuracy of 22% when trained using all the available features. Also, all of the models perform better when trained using all available features than when trained using a top 20 features determined using RFE.
Even though all models outperform the baseline (random guess), we believe there is still some room for improvement. Since the target variable of the github PR dataset is an ordinal variable, an ordinal classifier could perform better than the models trained in this notebook. We will explore this idea in a future notebook.
As the immediate next step, we will to deploy the best model from this notebook as an inference service using Seldon.